Что пишут в блогах
- Мои 12 недель в году. Часть 26 (Лицензия на ИП и 3-я книжка!)
- Как войти в новый проект: взаимоотношения с командой и пользователями, тестовая лаборатория
- Баги - отдельные задачи или комментарии?
- Митап от Тинькофф “Техтолк инженеров по тестированию” 20 марта 2024
- Опрос: поделитесь мнением про техдолг
- Если вы стали QA-менеджером
- Книга "Баг-трекинг: локализация и оформление дефектов" уже в продаже!
- Топ 30 вопросов на собеседовании на тестировщика ПО (Junior QA)
- Идеальный час
- Обратная связь и самомотивация

Что пишут в блогах (EN)
- Five for Friday – April 5, 2024
- The Possible and Impossible: Mathematical Thinking for Planning
- Looking back at Agile Testing, 15 years on
- Does Test Automation Necessarily Make Our Jobs Easier?
- 10 Bad Reasons Why Companies Don’t Hire Testers
- Judging Developers by GitHub Contributions
- Five for Friday – March 29, 2024
- Translating Agile Testing Condensed the unconvential way – part 3
- From Head of QA to Freelancing – Interview with Leonardo
- Five for Friday – March 22, 2024
Онлайн-тренинги
-
Школа тест-менеджеров v. 2.0Начало: 17 апреля 2024
-
Bash: инструменты тестировщикаНачало: 18 апреля 2024
-
Charles Proxy как инструмент тестировщикаНачало: 18 апреля 2024
-
Chrome DevTools: Инструменты тестировщикаНачало: 18 апреля 2024
-
Docker: инструменты тестировщикаНачало: 18 апреля 2024
-
Git: инструменты тестировщикаНачало: 18 апреля 2024
-
Python для начинающихНачало: 18 апреля 2024
-
Азбука ITНачало: 18 апреля 2024
-
Консольные утилиты Android: инструменты тестировщикаНачало: 18 апреля 2024
-
SQL: Инструменты тестировщикаНачало: 18 апреля 2024
-
Инженер по тестированию программного обеспеченияНачало: 18 апреля 2024
-
Практикум по тест-дизайну 2.0Начало: 19 апреля 2024
-
Английский для тестировщиковНачало: 22 апреля 2024
-
Школа Тест-АналитикаНачало: 24 апреля 2024
-
Автоматизация тестов для REST API при помощи PostmanНачало: 25 апреля 2024
-
Школа для начинающих тестировщиковНачало: 25 апреля 2024
-
Тестирование производительности: JMeter 5Начало: 26 апреля 2024
-
Логи как инструмент тестировщикаНачало: 29 апреля 2024
-
Тестирование REST APIНачало: 29 апреля 2024
-
Тестирование мобильных приложенийНачало: 1 мая 2024
-
Автоматизация тестирования REST API на PythonНачало: 1 мая 2024
-
Автоматизатор мобильных приложенийНачало: 1 мая 2024
-
Тестирование безопасностиНачало: 1 мая 2024
-
Автоматизация тестирования REST API на JavaНачало: 3 мая 2024
-
Техники локализации плавающих дефектовНачало: 6 мая 2024
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 13 мая 2024
-
Тестировщик ПО: интенсивный курс со стажировкой (ПОИНТ)Начало: 14 мая 2024
-
Тестирование юзабилити (usability)Начало: 15 мая 2024
-
Регулярные выражения в тестированииНачало: 16 мая 2024
-
Организация автоматизированного тестированияНачало: 17 мая 2024
-
Тестирование веб-приложений 2.0Начало: 17 мая 2024
-
Создание и управление командой тестированияНачало: 23 мая 2024
-
Автоматизация функционального тестированияНачало: 24 мая 2024
-
SQL для тестировщиковНачало: 27 мая 2024
-
Selenium IDE 3: стартовый уровеньНачало: 31 мая 2024
-
Программирование на Java для тестировщиковНачало: 31 мая 2024
-
Погружение в тестирование. Jedi pointНачало: 3 июня 2024
-
Аудит и оптимизация QA-процессовНачало: 7 июня 2024
-
Программирование на C# для тестировщиковНачало: 7 июня 2024
-
Комплексная система подготовки тестировщиков по программе ISTQB FLНачало: 17 июня 2024
| Откуда взялись в Google ненадёжные тесты |
| 24.07.2017 00:00 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
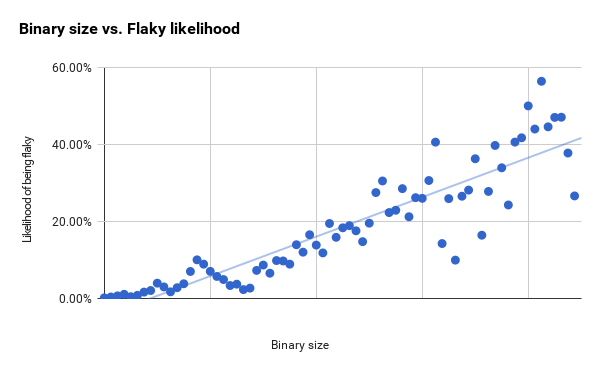
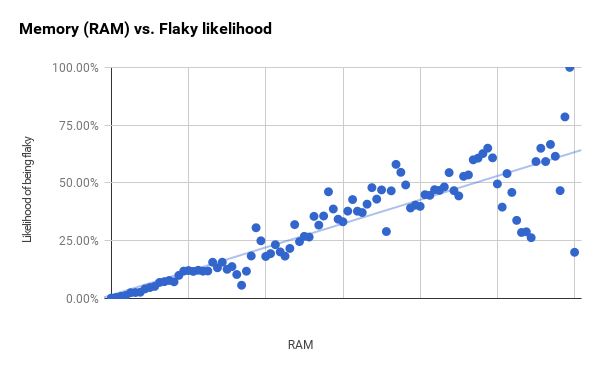
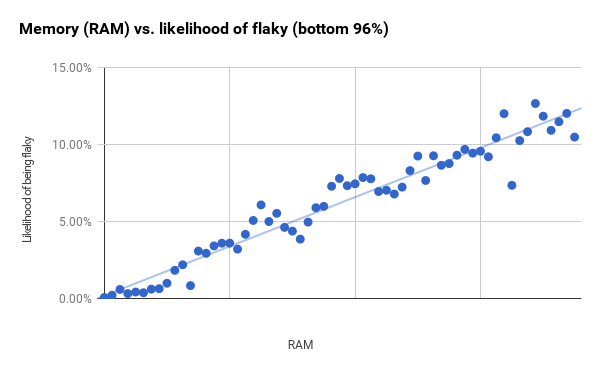
Автор оригинальной статьи: Джефф Листфилд, testing.googleblog.com/2017/04/where-do-our-flaky-tests-come-from.html Перевод: Анатолий Ализар, Habrahabr.ru (https://habrahabr.ru/post/327394/) Если тесты сбоят на ранее протестированном коде, то это явный признак того, что в коде появилась какая-то новая ошибка. Раньше тесты проходили успешно и код был правильный, сейчас тесты сбоят и код работает неправильно. Цель хорошего набора тестов заключается в том, чтобы сделать этот сигнал настолько ясным и чётко адресованным, насколько возможно. Ненадёжные тесты в Google В системе непрерывной интеграции Google работает около 4,2 млн тестов. Из них примерно 63 тыс. показывают непредсказуемый результат в течение недели. Хотя они представляют менее 2% от всех тестов, но всё равно ложатся серьёзным бременем на наших инженеров. Если мы хотим починить ненадёжные тесты (и избежать написания новых), то прежде всего нужно понять их. Мы в Google собираем много данных по своим тестам: время выполнения, типы тестов, флаги выполнения и потребляемые ресурсы. Я изучил, как некоторые из этих данных коррелируют с надёжностью тестов. Думаю, что это исследование может помочь нам улучшить и сделать более стабильными методы тестирования. В подавляющем большинстве случаев, чем больше тест (по размеру бинарника, использованию RAM или количеству библиотек), тем менее он надёжен. В остальной статье обсудим некоторые из обнаруженных закономерностей. Мы разбили тесты на три группы по размеру: маленькие, средние и большие. У каждого теста есть размер, но выбор метки субъективен. Инженер определяет размер, когда изначально пишет тест, и размер не всегда обновляется при изменениях теста. Для некоторых тестов эта метка больше не соответствует реальности. Тем не менее, у неё есть некоторая прогностическая ценность. В течение недели 0,5% наших маленьких тестов проявляли свойство недетерминированности, 1,6% средних тестов и 14% больших тестов [1]. Наблюдается явное уменьшение надёжности от маленьких тестов к средним и от средних к большим. Но это всё равно оставляет открытыми много вопросов. Мало можно понять, учитывая только размеры. Чем больше тест, тем меньше надёжность Мы собираем некоторые объективные оценки: бинарный размер теста и объём оперативной памяти, используемой во время работы теста [2]. Для этих двух метрик я сгруппировал тесты на две группы равного размера [3] и вычислил процент ненадёжных тестов в каждой группе. Числа внизу — это значения r2 для наилучшего линейного объективного прогноза [4].
Рассматриваемые здесь тесты — это по большей мере герметичные тесты, которые выдают сигнал успех/неудача. Бинарный размер и использование RAM хорошо коррелировали по всей выборке тестов, и между ними нет особой разницы. Так что речь не просто о том, что большие тесты скорее будут ненадёжными, а о постепенном уменьшении надёжности с увеличением теста. Ниже я составил графики с этими двумя метриками для всего набора тестов. Ненадёжность возрастает с увеличением бинарного размера [5], но мы также наблюдаем увеличение разности [6] в линейном объективном прогнозе. Некоторые инструменты обвиняют в том, что они являются причиной ненадёжных тестов. Например, тесты WebDriver (будь они написаны на Java, Python или JavaScript), имеют репутацию ненадёжных [7]. Для некоторых из наших обычных тестовых инструментов я вычислил долю ненадёжных тестов, написанных с помощью этого инструмента. Нужно отметить, что все эти инструменты чаще используются при создании тестов большего размера. Это не исчерпывающий список инструментов тестирования, и он покрывает примерно треть всех тестов. В остальных тестах используются менее известные инструменты или там нельзя определить инструмент.
Размер даёт лучший прогноз, чем инструменты Можно совместить выбор инструмента и размер теста — и посмотреть, что важнее. Для каждого упомянутого инструмента я изолировал тесты, которые используют этот инструмент, и разделил их на группы по использованию памяти (RAM) и бинарному размеру, по такому же принципу, как и раньше. Затем рассчитал линию наилучшего объективного прогноза и насколько она коррелирует с данными (r2). Потом вычислил прогноз вероятности, что тест будет ненадёжным в самой маленькой группе [8](которая уже покрывает 48% наших тестов), а также 90-й и 95-й процентиль по использованию RAM.
Эта таблица показывает результаты вычислений для RAM. Корреляция сильнее для всех инструментов, кроме эмулятора Android. Если игнорировать эмулятор, то разница в корреляции между инструментами при схожем использовании RAM будет в районе 4-5%. Разница между самым маленьким тестом и 95-м процентилем составляет 8-10%. Это один из самых полезных выводов нашего исследования: инструменты оказывают некое влияние, но использование RAM даёт гораздо большие отклонения по надёжности.
Выводы Выбранный разработчиком размер теста коррелирует с ненадёжностью, но в Google недостаточно вариантов выбора размера, чтобы этот параметр действительно был полезен для прогноза. Объективно измеренные показатели бинарного размера и использования RAM сильно коррелируют с надёжностью теста. Это непрерывная, а не ступенчатая функция. Последняя показала бы неожиданные скачки и означала бы, что в этих точках мы переходим от одного типа тестов к другому (например, от модульных тестов к системным или от системных тестов к интеграционным). Тесты, написанные с помощью определённых инструментов, чаще дают непредсказуемый результат. Но это в основном можно объяснить бóльшим размером этих тестов. Сами по себе инструменты вносят небольшой вклад в эту разницу по надёжности. Следует с осторожностью принимать решение о написании большого теста. Подумайте, какой код вы тестируете и как будет выглядеть минимальный тест для этого. И нужно очень осторожно писать большие тесты. Без дополнительных защитных мер есть большая вероятность, что вы сделаете тест с недетерминированным результатом, и такой тест придётся исправлять. Примечания
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||