Что пишут в блогах
- Мои 12 недель в году. Часть 26 (Лицензия на ИП и 3-я книжка!)
- Как войти в новый проект: взаимоотношения с командой и пользователями, тестовая лаборатория
- Баги - отдельные задачи или комментарии?
- Митап от Тинькофф “Техтолк инженеров по тестированию” 20 марта 2024
- Опрос: поделитесь мнением про техдолг
- Если вы стали QA-менеджером
- Книга "Баг-трекинг: локализация и оформление дефектов" уже в продаже!
- Топ 30 вопросов на собеседовании на тестировщика ПО (Junior QA)
- Идеальный час
- Обратная связь и самомотивация

Что пишут в блогах (EN)
- Five for Friday – April 5, 2024
- The Possible and Impossible: Mathematical Thinking for Planning
- Looking back at Agile Testing, 15 years on
- Does Test Automation Necessarily Make Our Jobs Easier?
- 10 Bad Reasons Why Companies Don’t Hire Testers
- Judging Developers by GitHub Contributions
- Five for Friday – March 29, 2024
- Translating Agile Testing Condensed the unconvential way – part 3
- From Head of QA to Freelancing – Interview with Leonardo
- Five for Friday – March 22, 2024
Онлайн-тренинги
-
Практикум по тест-дизайну 2.0Начало: 19 апреля 2024
-
Английский для тестировщиковНачало: 22 апреля 2024
-
Школа Тест-АналитикаНачало: 24 апреля 2024
-
Python для начинающихНачало: 25 апреля 2024
-
Автоматизация тестов для REST API при помощи PostmanНачало: 25 апреля 2024
-
Азбука ITНачало: 25 апреля 2024
-
Школа для начинающих тестировщиковНачало: 25 апреля 2024
-
Тестирование производительности: JMeter 5Начало: 26 апреля 2024
-
Логи как инструмент тестировщикаНачало: 29 апреля 2024
-
Тестирование REST APIНачало: 29 апреля 2024
-
Автоматизатор мобильных приложенийНачало: 1 мая 2024
-
Автоматизация тестирования REST API на JavaНачало: 1 мая 2024
-
Автоматизация тестирования REST API на PythonНачало: 1 мая 2024
-
Тестирование безопасностиНачало: 1 мая 2024
-
Тестирование мобильных приложенийНачало: 1 мая 2024
-
Инженер по тестированию программного обеспеченияНачало: 2 мая 2024
-
Техники локализации плавающих дефектовНачало: 6 мая 2024
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 13 мая 2024
-
Тестировщик ПО: интенсивный курс со стажировкой (ПОИНТ)Начало: 14 мая 2024
-
Тестирование юзабилити (usability)Начало: 15 мая 2024
-
Chrome DevTools: Инструменты тестировщикаНачало: 16 мая 2024
-
Git: инструменты тестировщикаНачало: 16 мая 2024
-
Docker: инструменты тестировщикаНачало: 16 мая 2024
-
SQL: Инструменты тестировщикаНачало: 16 мая 2024
-
Charles Proxy как инструмент тестировщикаНачало: 16 мая 2024
-
Консольные утилиты Android: инструменты тестировщикаНачало: 16 мая 2024
-
Регулярные выражения в тестированииНачало: 16 мая 2024
-
Bash: инструменты тестировщикаНачало: 16 мая 2024
-
Тестирование веб-приложений 2.0Начало: 17 мая 2024
-
Организация автоматизированного тестированияНачало: 17 мая 2024
-
Школа тест-менеджеров v. 2.0Начало: 22 мая 2024
-
Создание и управление командой тестированияНачало: 23 мая 2024
-
Автоматизация функционального тестированияНачало: 24 мая 2024
-
SQL для тестировщиковНачало: 27 мая 2024
-
Программирование на Java для тестировщиковНачало: 31 мая 2024
-
Selenium IDE 3: стартовый уровеньНачало: 31 мая 2024
-
Погружение в тестирование. Jedi pointНачало: 3 июня 2024
-
Программирование на C# для тестировщиковНачало: 7 июня 2024
-
Аудит и оптимизация QA-процессовНачало: 7 июня 2024
-
Комплексная система подготовки тестировщиков по программе ISTQB FLНачало: 17 июня 2024
| Как устроено автоматическое тестирование в Почте Mail.Ru под iOS |
| 25.05.2017 08:16 |
|
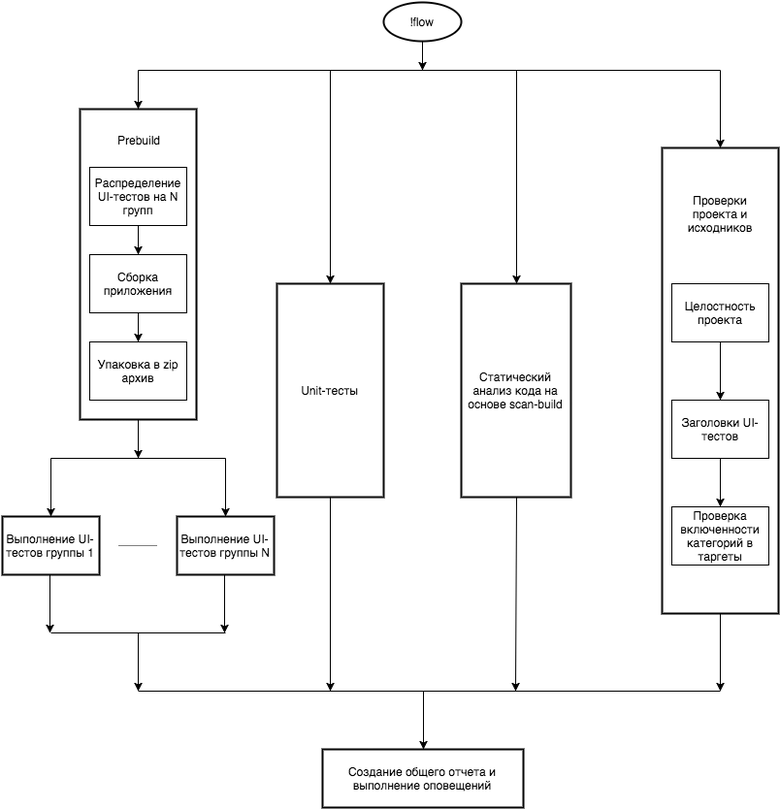
Оригинальная публикация: https://habrahabr.ru/company/mailru/blog/325552/ Некоторое время назад мы рассказали вам об автоматическом тестировании нашей Почты на Android и получили огромное количество вопросов от читателей. Сегодня приоткроем вам часть нашей «внутренней кухни», которая касается автотестирования на iOS. Для тестирования каждой сборки мы проводим более 500 автотестов, которые выполняются менее чем за один час. Как мы их реализовывали и зачем? С какими проблемами сталкивались и как смогли их решить? Обо всём этом читайте под катом. Схематически рабочий процесс выглядит следующим образом:
Нажмите на картинку, чтобы увеличить изображение Схема показывает начальные, наиболее жесткие и критически важные шаги задачи на пути к релизу. Начнем с одного из первых компонентов — Code Review. Gerrit Code Review Для код-ревью мы используем Gerrit Code Review. Он работает на отдельном узле, так как при некоторых действиях требует достаточно много ресурсов. Код хранится в git-репозитории. Помимо этого настроено зеркалирование репозитория на дополнительный узел, а также постоянно поддерживается полная резервная копия диска через Time Machine. Рабочий процесс тесно связан с Gerrit. Проводятся не только автоматизированные проверки, но и QA-тестирование. Approve/Fail на любом из этапов отмечается в Gerrit в виде балла: +1/–1. Если автоматизированная проверка завершается с ошибкой или не удается собрать тестовую сборку — выставляется –1. Если первый этап прошел успешно, далее за дело берется команда QA. Они взаимодействуют только с Jira, переводя задачу в состояние Open или QA Approved, поэтому при переходе выставляется соответствующий Label в Gerrit. Для этого реализован небольшой плагин для Jira, он выполняет именно эту задачу — и ничего более. Система команд и связь с CI Gerrit позволяет использовать server-side hooks при помощи дополнительного плагина. Мы реализуем на ruby следующие хуки:
Большая часть хуков используется для оповещения команды об изменениях, а также для синхронизации состояния задачи в Jira. Например, при создании очередного patchset’а в Gerrit вызывается соответствующий хук, в котором мы переводим Jira-задачу в состояние Code Review, а кастомное поле Merge Approved выставляется в значение No, так как автоматизированные проверки на этом patchset’е еще не выполнялись. Но есть и более насыщенные реализации, например хук comment-added. Через него мы запускаем проверки и сборку изменений на CI-платформе. Для этого реализована собственная система команд, которая позволяет запускать определенные Job’ы на CI на заданном patchset’е. Чтобы облегчить задачу расширения набора команд, мы реализовали небольшой DSL для описания отображений комментариев в Job’ы. Например, так выглядит описание команды запуска автоматизированных проверок: JobMapping.register do command 'flow' job BUILD_FLOW_JOB arguments_required processor do |args| { 'CHECKS_ENABLED' => args.key?('checks') } end processor do |args| { 'ANALYSIS_ENABLED' => args.key?('analysis') } end processor do |args| { 'UNITTESTS_ENABLED' => args.key?('unit') } end processor do |args| if args.key?('ui') tags = args['ui'] { 'UITESTS_ENABLED' => true, 'UI_TESTS_TAGS' => tags.nil? ? '' : tags.tr(',', ' ') } else { 'UITESTS_ENABLED' => false } end end end Автоматизированные проверки состоят из нескольких частей, и хочется иметь возможность запускать то, что нужно сейчас. Каждый JobMapping привязан к определенной команде, она задается методом command. Также эта команда должна отображаться в Job на Jenkins, он задается угадайте каким методом (job). Если у команды есть аргументы, в JobMapping их необходимость указывается методом arguments_required. Job’ы в Jenkins конфигурируются через переменные окружения, для этого в регистрации mapping’а можно добавлять блок-процессор методом processor и выполнять в нем преобразование строки вызова команды в набор env-переменных. Чаще всего этих методов хватает для создания нужных отображений. Затем возникает лень, и вместо «!flow ui unit» хочется написать просто «!tests». Поэтому появились трансляции: JobMapping.register do command 'tests' translates_to '!flow ui unit' rebase end Все говорит само за себя,
CI-платформа Бо́льшая часть платформы написана с нуля на Ruby. Каждая проверка или задача реализуется отдельным модулем, который можно запустить как локально, так и на CI. Для запуска задач мы используем Rake. Таким образом, для каждого модуля есть отдельный Rake-таск в Rakefile. Если при локальном запуске разработчик может положиться на консольные логи, то на CI он ожидает увидеть итоговый отчет и оповещение. Это один из исходных принципов — логи Job’ов в Jenkins нужны для разработчика CI, а не его клиента. Поэтому все модули проверок реализуют одинаковый интерфейс, чтобы при запуске на CI получить итоговое состояние задачи и описание ошибки (если она есть). Значит, для CI нам нужна система, которая позволяет просто запустить Rake-задачу и взять на себя некоторые основные операции вроде клонирования кода заданной ревизии, содержания сертификатов, сохранения артефактов. В качестве базы был освоен Jenkins. От него используем:
Все Job’ы — это последовательность sh-скриптов, которые выполняются после клонирования нашего репозитория. И в большинстве случаев sh-скрипт в Job’е просто вызывает Rake-таск. Все остальные операции — запуск xcodebuild, scan-build, модули проверок проекта и исходников, системы UI-тестов, обработку результатов — мы реализуем сами в рамках ruby-скриптов. На CI-платформе можно выделить два типа задач:
Сборки Сборка и проверки/тесты не зависят друг от друга, после успешной сборки приложение и задача сразу попадают к команде QA для ручной проверки конкретных новых кейсов. На каждом этапе по пути к релизу выходят сборки:
Полностью автоматически работают только первые два этапа, так как они выпускаются в HockeyApp, где это можно делать сколько угодно раз. Бета и релиз — события более редкие и требующие большей внимательности, поэтому запускаются вручную при необходимости. Тестовая сборка — этап 1 Когда изменение успешно проходит Code Review, готовится тестовая сборка: версия с изменениями, которые еще не влиты в основную ветку. Успешно собранное приложение сразу загружается в HockeyApp под отдельным идентификатором тестовых сборок. Ссылки на версию в HockeyApp крепятся к задаче в Jira. Если сборка закончилась успешно, задача переводится в состояние Ready For Test; если неудачно — в состояние Open для дальнейшей доработки и исправления ошибок. Команда QA проверяет сборку на соответствие поставленной задаче на разных девайсах и версиях iOS. Если изменения всех устраивают и к этому моменту уже прошли автоматизированные проверки, Code Review и ревью дизайна, то нажатие Pass в Jira сразу вольет изменение в основную ветку, тем самым запуская второй этап. Альфа-версия — этап 2 Когда изменение вливается в основную ветку проекта, мы должны выпустить альфа-версию приложения. Триггер этой сборки — хук в Gerrit change-merged. Сразу после мержинга изменения запускается Job сборки текущей альфа-версии приложения. На этом Job’е установлена задержка — 10 минут, которая нужна на случай мержа нескольких зависимых (или независимых) задач. Так как весь Job занимает в среднем 11—12 минут, то проще дождаться мержинга нескольких задач, чем тратить время на каждую в отдельности. Собранная альфа-версия включит в себя все изменения с момента последней удачно собранной версии. После успешного завершения свежая версия приложения загружается в HockeyApp. Задача в Jira считается закрытой именно тогда — как только она становится доступна в альфа-версии приложения. Поэтому после публикации в HockeyApp все вошедшие в версию задачи закрываются. Для этого мы обращаемся к API Jira. В них также остается комментарий со ссылками на Job в Jenkins и само приложение в HockeyApp. Неудача при сборке на этапе 2 маловероятна. Если такое происходит, то чаще всего из-за длительных отказов API HockeyApp или Jira. Это редкость, но...
С этим нет никаких проблем, так как следующее влитое изменение запустит этот же Job, который захватит и предыдущие изменения. Бета-версия — этап 3 Третий этап — бета. Отдельный Job на Jenkins, ему требуется только название ветки, с которой будет собрана бета-версия. Запускается сборка вручную: хотя бета и запланирована с точностью до дня, она не имеет конкретного времени/периода запуска или триггера. Результат сборки автоматически попадает в HockeyApp и становится доступен команде QA. Тут же запускается Job для релизной версии с той же ветки, сборка загружается в TestFlight и выдается во внутреннее и внешнее тестирование. Релиз — этап 4 Четвертый этап — релиз. Закаленная бета-испытаниями сборка, уже загруженная в iTunesConnect и TestFlight на третьем этапе, выдается в релиз. Сборка приложений Сборки выполняются напрямую xcodebuild’ом. Каждый этап обложен отдельной конфигурацией и аргументами. Например, в самом начале мы полностью отключаем Link-Time Optimizations, чтобы сэкономить время до выхода задачи в тестирование. Также на первом этапе в приложении доступен функционал, активируемый в compile-time, который помогает отслеживать и отлаживать проблемы, а также облегчает QA-команде некоторые задачи:
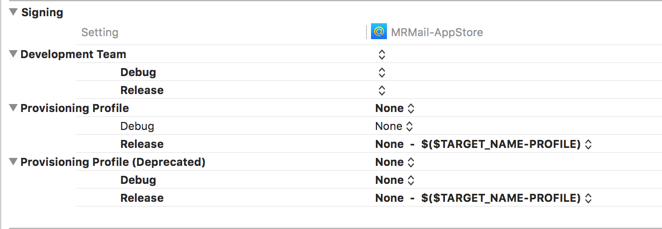
Подпись приложения и provisioning profile На данный момент при автоматизированной сборке мы жестко задаем используемый сертификат и provisioning profile. Перед сборкой проходимся по доступным на узле профилям, выбираем нужный именно под текущую сборку и выставляем в настройках проекта через переменные окружения. Этот шаг, конечно же, выполняется скриптами автоматически. На то были свои причины. Мы стараемся переходить на новые major-версии XCode, как только они появляются, и на одной из бета-версий XCode 7.0 наткнулись на баг в xcodebuild: он не позволял стабильно использовать автоматическое определение provisioning profile. Поэтому мы реализовали на том же Ruby модуль, который находит среди всех доступных профайлов нужные по Bundle Id, а затем добавили в проект на место профайлов env-переменные. В них при сборке кладем идентификаторы профайлов. На XCode 7.0 это не доставляло никаких неудобств. Профайл все так же подставлялся автоматически средой разработки, если env-переменная была пуста. Но с XCode 8.0 и новым режимом Automatic Signing наш метод работать не мог. При Automatic Signing среда автоматически подставляет и в debug-, и в release-версии development-сертификаты и, соответственно, профайлы. Если жестко задавать на release-версию distribution-сертификат, то xcodebuild отказывается работать. То есть предполагается, что при создании xcarchive всегда выходит версия, подписанная на development. А затем следует второй этап — экспортирование IPA, для него теперь можно задать конфигурацию через -exportOptionsPlist и в соответствии с ней переподписать приложение под нужный distribution. Нас такие правила исходно не устроили, поэтому мы отключили режим Automatic Signing и до сих пор подставляем профайлы вручную. Конфигурация выглядит следующим образом:
Нажмите на картинку, чтобы увеличить изображение Проблемы У xcodebuild есть ограничение, которое нам обойти не удалось: без ущерба для длительности выполнения нельзя запускать больше одного процесса. Мы играли различными env-переменным и путями к кешу и данным, но безрезультатно. Где-то он все же упирается в разделяемые ресурсы. При одновременных сборках сильно заметна поочередная работа каждого процесса. Итоговая длительность при двух параллельных xcodebuild увеличивается почти в два раза. Поэтому мы устанавливаем по одному executor’у на каждый слейв Jenkins’а. Это позволяет исключить помехи двух задач без дополнительных плагинов, которые далеко не всегда адекватно работают в Jenkins. При этом все наши Job’ы по максимуму используют выделенный executor, особого смысла запускать несколько задач параллельно нет, они будут только мешать друг другу. Проверки и тесты Для проверок и тестов есть соответствующие Rake-задачи — на каждую проверку отдельная. Конкретнее о цели и реализации проверок далее, а пока — высокоуровневое описание работы. В Jenkins используется плагин BuildFlow, который позволяет запускать параллельные задачи, объединять их, создавать цепочки и т. д. Любые автоматизированные проверки и тесты идут в рамках BuildFlow-задачи. В полном варианте параллельно запускаются:
Первые три задачи выполняются в один Jenkins Job, но система UI-тестов слегка сложнее, чем запуск тестов через xcodebuild. Это отдельная цепочка, ее первый шаг — prebuild — заключается в следующем:
Нажмите на картинку, чтобы увеличить изображение Затем на основе результатов распределения BuildFlow запускает необходимое количество задач в Jenkins, у каждой — своя группа тестов. Каждый Job получает UI-тесты, конфигурацию, сборку и скрипты из артефактов Prebuild Job’а в виде одного архива. После BuildFlow приступает к следующей задаче, суть которой — создать итоговый общий отчет и выполнить оповещения в Jira, HipChat, Gerrit. За результатами работы каждого из путей эта задача обращается в артефакты. BuildFlow конфигурируется, любой из путей можно при необходимости выключить. UI-тесты Каким должен быть фреймворк Мы считаем, что фреймворку для UI-тестирования нужны:
MonkeyTalk (на данный момент куплен компанией Oracle, дальнейший его путь пока неизвестен) подошел по нашим критериям и значительно обогнал остальных претендентов. Он обладает собственным элементарным синтаксисом, простым, который позволяет выносить общие фрагменты тестов в отдельные скрипты и переиспользовать их. Чтобы написать тест на этом языке, можно вообще не разбираться в программировании, нужно только выяснить Accessibility Identifier — извлечь его утилитой вроде Reveal, Accessibility Inspector или Flex, а в крайнем случае узнать у разработчика. Итоговый скрипт почти полностью повторяет тест-кейс, описанный командой QA. При этом MonkeyTalk поддерживает JavaScript. Тут простор действий позволяет реализовать ту самую прослойку поверх стандартных команд и идентификаторов элементов. Постепенно было создано что-то очень похожее на Page Object. Каждый экран, диалог и элемент приложения со временем получил собственный модуль в JavaScript, что значительно ускорило разработку UI-тестов. При этом доступны все преимущества программирования (циклы, условия, функции), хоть мы и против этого. Тест должен быть простым, прямолинейным, и пусть получится слегка многословно. Если тест падает, иногда приходится обращаться к скрипту, и нужна возможность ясно и точно сказать, что не прошла проверка названия письма после удаления через Edit-режим. А сделать это при наличии цикла по режимам с тремя условными разделениями по командам и парой лямбд в аргументах может быть весьма сложно и крайне неприятно. Однако в некоторых тестах мы все же используем (но в меру) циклы, что действительно здорово сокращает длину скрипта теста. У MonkeyTalk есть еще одно крупное преимущество, которое очень пригодилось в дальнейшем при оптимизации и ускорении выполнения сильно увеличившейся базы UI-тестов. Модификации MonkeyTalk MonkeyTalk не зависит от XCTest. Благодаря этой ключевой особенности нам удалось реализовать распределенную систему выполнения UI-тестов. Другие фреймворки (KIF, EarlGrey, да и официальный XCUITest) запускаются через xcodebuild. С XCUITest все совсем тяжело. Если обратить внимание на процессы, работающие при выполнении тестов, то можно заметить testmanagerd. Он полностью занят одним текущим тестированием. Если запустить параллельно еще одну сессию, то именно из-за testmanagerd ничего не выйдет: тесты даже не стартуют. KIF и EarlGrey работают на базе XCTest. Когда мы только стали думать о параллельном запуске в рамках одного узла, наработок было не так много. Начинал развиваться FBSimulatorControl, только потом появился pxctest. Собственные попытки ни к чему более-менее юзабельному не привели. Вариант с MonkeyTalk был проще и доступнее. MonkeyTalk никак не зависит ни от XCTest, ни от XCUITest. Он имеет отдельную систему запуска и выполнения теста. В приложение встраивается агент с http-сервером. На стороне скриптов используется runner, который парсит скрипт UI-теста, отправляет команды по заданному адресу и ожидает ответа с результатом выполнения команды. В итоге нам необходимо только запустить на симуляторе приложение, дождаться запуска, после чего запустить runner и обработать результаты. Со временем и очередными обновлениями iOS мы столкнулись с некоторыми сложностями, для их решения модифицировали MonkeyTalk под себя и реализовали:
Также мы переписали взаимодействие с некоторыми элементами UIKit и часть сетевого взаимодействия, значительно ускорив весь фреймворк. UI-тесты должны работать как можно ближе к реальным условиям и сохранять принципы черного ящика. Тапы и жесты в реальных условиях выполняются рукой пользователя. Самое близкое, чего мы можем достичь при автоматизации, — это имитация нажатий на уровне событий в приложении. Исходно MonkeyTalk напрямую отправлял сообщения UIControl’ам и UIGestureRecognizer’ам, что нас совсем не устраивало, а порой просто не давало возможности покрыть кейс. Также мы можем контролировать все сетевое взаимодействие через скрипт теста, включая/отключая стабы, в том числе при запуске приложения; об этом чуть позже. Дополнительное преимущество — абсолютно аналогичный процесс для реального девайса, если вдруг мы решим на них перейти. Управление UI-тестами через скрипты Так как у MonkeyTalk особый способ запуска, пришлось реализовать дополнительные управляющие скрипты. Их задачи:
Для самого скрипта UI-теста мы ввели заголовок, о котором детально поговорим далее. Сейчас стоит указать, что именно в заголовке задается тип девайса и версия iOS, на которой тест должен выполняться. Если задано несколько аргументов, то будет взято декартово произведение. Также есть возможность передавать в приложение различные аргументы для настройки приложения перед началом тестирования. Все это достаточно просто реализовать, но UI-тестирование — процесс длительный, а наша цель — проверять каждое изменение в проекте. Масштабирование — параллельный запуск Первая версия Исходно наша самописная система выполнения UI-тестов отличалась низкой утилизацией ресурсов. Мы разбивали 70 тестов по папкам. Каждая папка соответствовала категории UI-теста (например, авторизация). При запуске папки распределялись на доступные нам Mac Mini. На каждом из них одновременно работал только один симулятор, который перезапускался и полностью затирался под новый UI-тест. Очевидные недостатки:
Затем, слегка расширив базу тестов, покрыв самое необходимое и базовое, мы начали искать способы максимально утилизировать ресурсы. И нашли. Текущая версия
Нажмите на картинку, чтобы увеличить изображение Если коротко, то мы научились запускать и контролировать несколько симуляторов на одной машине и реализовали систему распределения тестов по группам машин. Теперь в системе две точки гибкого распределения тестов по доступным узлам:
Пул симуляторов на каждом узле Из-за пула симуляторов и параллельного запуска нескольких экземпляров приложения HTTP-серверы от MonkeyTalk должны слушать на разных портах. Исходно такого функционала в MonkeyTalk не было, поэтому мы его добавили. Порт конфигурируется при запуске приложения через environment variable или launch argument. Мы можем полностью утилизировать мощность каждого узла, увеличивая пул хоть до обморочного состояния слейва. На новых узлах с i7, 16 Гб ОЗУ и SSD обычно ставим четыре-пять симуляторов. Но есть и старые узлы, на которых стабильно держится не больше двух симуляторов. В итоге все слейвы делятся на группы по размеру пула. Они отмечаются, помимо env-переменных, отдельными лейблами. И именно на эти группы узлов по размерам пулов распределяются UI-тесты. Все данные для распределения получаются от Jenkins через API. Размер пула выставляет в env-переменной каждого узла. Можно взять очередь задач, отфильтровать ее, выяснить, на какой пул рассчитывает каждая задача. Занятость узла также запросто проверяется через API. Другое дело — статистика по времени выполнения тестов. Чтобы избежать дополнительной точки отказа в системе, мы исключили дополнительные сервисы. Как я уже упоминал ранее, во время тестов мы пишем достаточно много полезных данных, в том числе для самой системы выполнения. В данном случае полезны тайминги выполнения, которые в итоге сохраняются в артефактах Jenkins. Далее нужно скриптом для поиска и извлечения таймингов из артефактов:
В результате получаем большой json со статистикой по всем UI-тестам. В том числе рассчитана средняя продолжительность UI-теста на случай, если для выполняемого теста нет статистики. Файл хранится в репозитории и периодически обновляется при изменениях UI-тестов. В итоге алгоритм распределения и группировки отрабатывает так:
Группы UI-тестов формируются в два шага:
Узлы выделяются по счетчикам. Например, прогоняем все UI-тесты на семи узлах. Ориентируемся на счетчики пулов, которые сформировались ранее. В цикле семь раз берем пул с максимальным счетчиком, уменьшая его на один. Так мы учитываем количество узлов по размеру пула, очередь и их занятость. Далее выделенные партишены заполняем UI-тестами максимально равномерно с учетом размера пула. Проходимся по всем тестам, добавляя каждый в наименее заполненный партишен. В итоге получаем большой конфиг с информацией, необходимой для запуска и выполнения партишенов:
Вместо огромного json намного приятнее смотреть логи, в которые мы пишем все для последующей отладки и проверки: INFO IOSMail::UITestsGrouper : Getting all available tests... INFO IOSMail::UITestsGrouper : Found 506 available tests. Took 0.8894939422607422 secs. INFO IOSMail::UITestsGrouper : Reading stats json from ./ui-tests/uitests_stats.json... INFO IOSMail::UITestsGrouper : Gluing available tests and stats... WARN IOSMail::UITestsGrouper : No statistics for ScrollToFirstLetterInListFromMiddle.mt_iPhone5s. Using mean tests time. INFO IOSMail::UITestsGrouper : Statistical total duration = 33603.8670472377 INFO IOSMail::UITestsGrouper : Computing capacities counters... INFO IOSMail::UITestsGrouper : Capacities counters received and computed. Took 3.4377992153167725 secs. INFO IOSMail::UITestsGrouper : Partitioning for 7 parts... INFO IOSMail::UITestsGrouper : Allocated partitions = [{:capacity=>4, :label=>"4sim", :tests=>[]}, {:capacity=>4, :label=>"4sim", :tests=>[]}, {:capacity=>5, :label=>"5sim", :tests=>[]}, {:capacity=>4, :label=>"4sim", :tests=>[]}, {:capacity=>5, :label=>"5sim", :tests=>[]}, {:capacity=>3, :label=>"3sim", :tests=>[]}, {:capacity=>4, :label=>"4sim", :tests=>[]}] INFO IOSMail::UITestsGrouper : Partitions constructed, took 0.039823055267333984 secs. INFO IOSMail::UITestsGrouper : Partitions sizes = [72, 70, 87, 73, 83, 46, 75] INFO IOSMail::UITestsGrouper : Partitions durations = [1157.0547642111776, 1160.5415018200872, 1157.1358834599146, 1159.2893925905228, 1158.044078969956, 1161.813697735469, 1158.7458768486974] Выше показано разбиение всех доступных тестов на семь групп. Вся операция обычно занимает не больше 4—5 секунд, но может зависеть от API Jenkins. Итоговые длительности партишенов учитывают только время выполнения самих UI-тестов, без времени оркестрации симуляторами. Статистика по действиям с симуляторами у нас тоже есть, но мы ее пока не используем. Итоговые длительности групп отличаются между собой менее чем на среднюю длительность UI-теста. Размеры групп значительно отличаются. На мощные узлы с четырьмя симуляторами попадет группа с сотней тестов, а на слабый узел — группа с 40 тестами. При этом выполняться они будут одно и то же время. На практике эти подсчеты подтверждаются, разница в выполнении групп может достигать 5 минут, но, на наш взгляд, это не критично. Бывают и случаи, когда нужно запустить один тег, в котором всего 10—15 UI-тестов. Раздавать их семи машинам крайне расточительно. Поэтому мы добавили оптимизацию: если после распределения появляется группа тестов длительностью меньше 10 минут, мы уменьшаем количество групп на одну и распределяем заново. Изоляция запусков Взаимная изоляция отдельных UI-тестов для нас критична. Каждый тест стартует на абсолютно чистом свежем приложении и проходит один и тот же путь авторизации. За время жизни нашей системы UI-тестирования было реализовано два подхода к решению этой задачи. Каждому по симулятору! Тесты выполняются изолированно, под каждый тест создается отдельный новый симулятор. На ruby мы реализовали wrapper для simctl — стандартной утилиты в xcode для взаимодействия с iOS-симуляторами. В итоге для каждого теста выполнялась приблизительно такая последовательность действий: simulator = Simulators::MRSimulator.new(test_name, type, runtime) simulator.launch simulator.prepare(app) simulator.install_app(app) If access_allowed simulator.enable_access(app) else simulator.disable_access(app) end simulator.run_app(app, arguments, env) # запускаем MonkeyTalk runner simulator.shutdown # собираем артефакты (логи, креш-логи, тайминги, скриншоты, видео) simulator.destroy Из-за проблем, связанных именно с simctl, пришлось реализовать собственные механизмы ожидания завершения таких действий, как запуск симулятора, установка и запуск приложения. Механизмы по бо́льшей части основаны на чтении syslog’а симулятора и ожидании определенных событий. Это позволило нам здорово стабилизировать запуск и функционирование пула симуляторов. Но со временем мы уткнулись в проблемы непосредственно с запуском симуляторов — он отнимал много времени и иногда безосновательно отказывал. Общак симуляторов Время выполнения группы тестов заметно сокращается, если переиспользовать симуляторы. Под этим подразумевается следующий жизненный цикл:
Таким образом удается избежать достаточно длительной операции запуска симулятора, стабильность которой в целом не очень высока. По нашей статистике, она занимала в среднем 20 секунд. Напомню, в предыдущей версии на каждый тест создавался и запускался новый чистый симулятор. Ключом к переиспользованию симуляторов стала возможность чистить keychain. Находить data- и appgroup-контейнеры мы могли и до этого. Стирать их после удаления самого приложения не составляло труда. Но найти keychain было сложнее. Нам приглянулся файл keychain-2-debug.db. Разобраться в содержимом файла не особо получилось, но никто не мешает стереть содержимое какой-нибудь таблицы и проверить, к чему это приведет. Так мы и чистим keychain: def clear_keychain `sqlite3 ~/Library/Developer/CoreSimulator/Devices/#{@id}/data/Library/Keychains/keychain-2-debug.db "delete from genp;"` end Нельзя с полной уверенностью сказать, делаем ли мы это верно (скорее нет, чем да), но текущие манипуляции точно приводят к инвалидации keychain — и дальше все адекватно функционирует. Обходы проблем xcode, simulator и т. д. Cтабильность взаимодействия с iOS-симуляторами оставляет желать лучшего iOS-симулятор в единственном экземпляре работает вполне стабильно, но и при этом бывают ошибки. Если же создавать, запускать, стирать и выключать множество симуляторов, хоть и удаляя их за собой, то непременно возникнут ограничения и неустойчивое поведение. Например, при внедрении пула симуляторов мы столкнулись с тем, что не удается запустить больше семи-восьми симуляторов в системе. Они начинают валиться с крешами в самых разных местах. Также рантайм iOS-симулятора определенной версии иногда просто отказывается работать, ссылаясь на ошибку при dlopen, до полного ребута системы. Самое противное в такой проблеме — автоматически достаточно сложно определить ее, отключить узел от Jenkins и отправить в ребут до того, как часть выполняющего прогона зафейлится. Эта сложность стала появляться значительно реже при введении системы переиспользования симуляторов. Получается, блокировка и баги в рантайме как-то связаны с постоянным созданием и запуском чистых симуляторов. Пул симуляторов и нагрузка С внедрением пула симуляторов ресурсы на узлах стали использоваться более полно, в связи с чем возникли сложности. При долгом запуске приложения из-за, например, высокой активности на диске его автоматически убивал watchdog от springboard. Стандартное время на запуск — приблизительно 20 секунд. С этой проблемой мы справились достаточно быстро, заглянув в исходники FBSimulatorControl от Facebook. Оказалось, что в preferences для springboard при выключенном состоянии симулятора можно добавить словарь, который содержит новые тайм-ауты для заданных Bundle Id. Мы пытались заставить этот метод заработать даже без выключения симулятора, просто убивая и перезапуская springboard, preferences ведь его, верно? Но без толку — симулятор должен быть выключен. Еще одна проблема — долгий первый запуск самого симулятора. При этом в системе бешеный File IO. Если посмотреть на достаточно долго работающий узел CI, то можно наблюдать сотни гигабайт данных, записанных и считанных процессами launchd, kernel_task и сервисом CoreSimulator. Все это связано с созданием и запуском новых симуляторов. У проблемы до определенного момента не было решения. С появлением XCode 8.0 запуск новых симуляторов совсем вышел из-под контроля, очень часто происходили тайм-ауты, запуск иногда с трудом умещался в 160 секунд. Тогда мы решили слегка изменить концепцию и переиспользовать симуляторы по схеме, описанной выше. Асинхронный simctl без признаков завершения действия Еще один неприятный аспект утилиты simctl, которая поставляется вместе с XCode, — это ее асинхронность. Запросив запуск приложения, утилита вернет управление практически мгновенно, но приложение еще даже не отобразит launch screen. Оно может вообще не запуститься (см. выше — ситуация с watchdog). Таких примеров с simctl много, поэтому мы надстроили свой контроль на чтении syslog’а симулятора. Ожидая определенных событий в логе, мы убеждаемся, что:
Системные диалоги в приложении С системными диалогами в приложении все сложно. MonkeyTalk работает в рамках процесса, а из него взаимодействовать с внешними диалогами нельзя. В приложении требуется тестировать доступ к контактам и к фото. Данную проблему мы решаем при помощи модификации sqlite базы TCC.db, об этом детальнее далее. Доступ к фото и контактам Как упоминалось выше, если фреймворк тестирования работает на уровне процесса приложения, то обязательно возникнут трудности с диалогами на доступ к контактам и фото. Нажать на них не будет возможности. Решить проблему нажатия нам не удалось, но мы нашли способ тестировать два итоговых состояния этого диалога. В заголовках тестов мы добавляем дополнительное поле, означающее необходимость состояния доступа к фото/контактам. Перед запуском приложения модифицируем sqlite базу TCC.db, выставляя для соответствующего доступа нужное значение: def self.setup_access(simulator_id, app, disabled, simulator_set_path: "#{ENV['HOME']}/Library/Developer/CoreSimulator/Devices") tcc_path = File.join(simulator_set_path, "#{simulator_id}/data/Library/TCC/TCC.db") Utilities::FileMonitoring.wait_for_file_creation(tcc_path, :max_wait => 30) { raise Simulators::Errors::SimulatorTimeoutError.new("Timed out while waiting for TCC!") } rights = disabled ? '0' : '1' ['kTCCServiceAddressBook', 'kTCCServicePhotos', 'kTCCServiceCalendar'].each do |access_target| `sqlite3 #{tcc_path} "replace into access(service, client, client_type, allowed, prompt_count) values ('#{access_target}','#{app.bundle_id}',0,#{rights},1)" 2>&1` end end Подмена ответов сервера Для UI-тестов используются настоящие почтовые аккаунты. Один тест может одновременно выполняться в нескольких прогонах на CI для разных задач, при этом, естественно, иногда проверяются действия, модифицирующие ящик. От полной симуляции бэкенда прямо в приложении мы отказались в силу необходимости поддержки всех изменений реального бэкенда. Вместо этого в приложении реализован URLProtocol, который есть только в тестовой сборке. Для этого URLProtocol’а можно реализовывать и добавлять FakeResponse. Из скрипта UI-теста эти FakeResponse можно включать, чтобы имитировать результат модификации данных. Так мы стабим все модифицирующее сетевое взаимодействие приложения с сервером на уровне взаимодействия с сетью. Это дает возможность сохранить состояние ящиков и запросто покрыть следующие кейсы:
Репортинг Помимо интеграции Jira с Hipchat наша система UI-тестов также выполняет задачи репортинга. Мы, конечно же, не смотрим результаты в логах Jenkins Job’а. В итоге мы получаем HTML-отчет на каждый UI-тест, UI-сьют, попытку их выполнения, тег UI-тестов и общий отчет. Для дальнейшей разработки системы запуска тестов и для анализа непройденного теста мы сохраняем (помимо результата UI-теста — успех/неудача/креш) множество полезных данных:
Сама система запуска UI-тестов тоже пишет в отдельный лог в debug-режиме. Помимо HTML-представления отчетов есть json-отчеты, которые необходимы для работы распределенной системы, ведь вся эта информация разбросана по N узлам. Итоговый отчет формируется в отдельном Job’е на основе json-отчетов узлов-исполнителей со ссылками на каждый тест, сьют, повтор и артефакты. После генерации HTML-отчетов они сохраняются в артефактах Jenkins, а затем в Jira создается комментарий с результатами следующего вида:
Нажмите на картинку, чтобы увеличить изображение Помимо Jira, если во время проверок возникали ошибки, оповещение будет отправлено в HipChat:
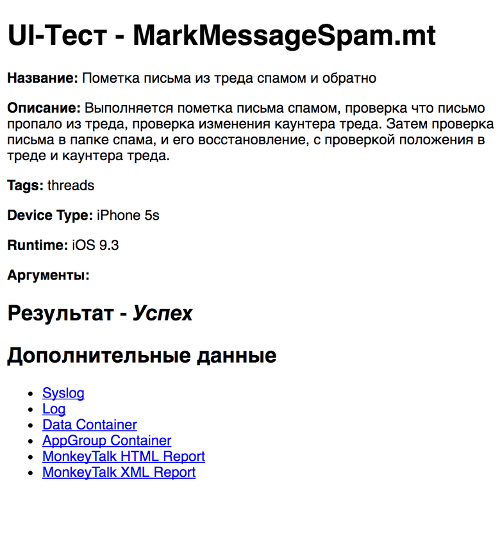
Нажмите на картинку, чтобы увеличить изображение Пример HTML-отчета о конкретном успешно выполненном тесте:
Нажмите на картинку, чтобы увеличить изображение Генерация документации Все тесты имеют обязательный заголовок — коммент-блок, содержащий следующие ключи:
На основе этих заголовков мы собираем HTML-каталог всех тестов. В группе проверок проекта и исходников реализован модуль для проверки заголовков всех UI-тестов. Этот скрипт запускается для каждой задачи в рамках проверки на CI-платформе. Итоговые характеристики системы Самый длительный путь в BuildFlow — UI-тесты. Немного статистики об этом пути на момент написания статьи:
Дополнительное время на этом пути занимает Prebuild, он длится 5—6 минут, в зависимости от узла и занятости Gerrit. То есть в среднем наша система выполнения тестов на пустом CI управляется с 506 UI-тестами примерно за 55 минут. Недостатки У системы есть очевидные недостатки, о которых мы вспоминаем с релизами новых версий XCode. С каждой версией мы полностью перепроверяем работоспособность и надеемся, что ничего не перестанет работать. Многое из вышеописанного — пляски вокруг недокументированного функционала:
Если все же что-то меняется, то всегда можно найти за что зацепиться и вернуть все в работоспособное состояние. Преимущества системы стоят того. Преимущества
Стоит также упомянуть, что в систему заложены точки расширения, что позволяет нам:
Проверки проекта Same Targets Некоторый функционал alpha-версии приложения зачастую не должен попасть в релизную версию. Например, контроль вызовов на главном потоке или трекинг и логирование запросов без вырезания важных данных в файл, который можно достать через iTunes. С точки зрения проекта у нас есть три таргета: Alpha, Beta и AppStore. Код только для Alpha должен быть включен лишь в таргет Alpha-версии. И такие моменты хочется контролировать, чтобы когда-нибудь в будущем по чистой случайности такой код не попал в релиз. Данный модуль проверяет именно этот фактор. При создании класса для конкретной версии (альфа, бета или релиз) разработчик вносит его в специальный файл конфигурации, помечая эксклюзивным для версии. На CI с этого момента всегда будет проверяться его принадлежность к различным таргетам. Если что-то не так, то задачу влить нельзя. Здесь также есть и защита от самого разработчика. Если он забыл добавить новый класс в конфигурацию, то исходно предполагается, что файл должен быть во всех версиях. И если по факту он будет включен только в Alpha-версию, то возникнет конфликт. Файл конфигурации представляет собой json. Приведу его фрагмент для наглядности: { "compare-sets": [ { "targets": ["MRMail-Alpha-Enterprise", "MRMail-Pub-Beta-Enterprise", "MRMail-AppStore", "MRMail-MonkeyTalk"], "exclusive": { "MRMail-Alpha-Enterprise": [ "^pod-packages/Reveal-iOS-SDK/", "^src/infrastructure/MainThreadGuard/UIKitThreadGuard\\.m$", В этом модуле мы работаем с файлом проекта, для его парсинга используем библиотеку xcodeproj, которая здорово облегчает задачу. Локализация Для строк и локализации реализована проверка, покрывающая весь проект. Мы хотим, чтобы каждая строка явно помечалась как локализируемая или нелокализируемая. В этом модуле выполняется проход по всем исходникам в поисках строковых литералов, мы проверяем, чтобы они были обернуты в один из двух макросов:
Такая проверка встроена как Build Phase, т. е. проблему можно отловить даже на этапе отладки. Если же кто-то халатно отправил такой код в ревью, а затем и на CI, то сборка попросту не выполнится, а задача перейдет в состояние Open. Категории С категориями и таргетами у Xcode есть заметная проблема — категория, не включенная в таргет, при использовании из этого таргета успешно компилируется и линкуется, несмотря на то что выполнение окончится крешем. По неизвестной причине во время компиляции и линковки этот факт остается без предупреждения/ошибки. Наше приложение содержит пять таргетов:
У нас есть категории для классов, которые содержатся отдельно в основном приложении, отдельно в экстеншенах и отдельно в общем фреймворке. Порой перестановки или доработки неявно приводят к вызову метода категории, не включенному в текущий таргет, например к вызову из экстеншена в категорию основного приложения. Есть правила для именования категорий, по ним можно ориентироваться, но в данном случае нет никаких жестких проверок, человеческий фактор никак не покрыт. Специально для этого мы реализовали собственную проверку — модуль на Ruby, который:
Если его нет — ошибка, будет креш. Здесь сразу видны несколько исключений:
Для этих случаев у нас есть файл исключений, в котором можно их описать. Реализованы они как элементарные правила. Если по базовому правилу — имплементация категории — результат неудовлетворительный, то смотрим файл исключений, находим проверяемую категорию, берем указанное правило и его аргументы. Далее фрагмент файла конфигурации для проверки включенности категорий: { "rules": [ { "name": "GeneralExternalImplementation", "type": "ExternalImplCheck", "imports": { "AccountEnvironmentImpl+Protected.h": "AccountEnvironmentImpl.m", ……. В данном фрагменте представлено следующее правило — для использования в таргете расширения AccountEnvironmentImpl+Protected.h нужно иметь в этом же таргете AccountEnvironmentImpl.m. Проверка включенности категорий в таргеты входит в набор стандартных проверок проекта и исходников на нашей CI-платформе и обычно занимает не больше двух минут. При реализации этого модуля опять же используем библиотеку xcodeproj. Заголовки тестов Как было описано выше, для UI-тестов у нас есть специальная система документирования — заголовки определенного формата. Проверка обязательных атрибутов этих заголовков также обязательна и входит в набор стандартных проверок проекта и исходников. Каждый реализованный UI-тест должен иметь:
Вот пример заголовка UI-теста: # tasks: IOSMAIL-6020 # name: Перенаправление письма # category: Compose # description: Открываем письмо, нажимаем на «многоточие» в тулбаре, перенаправляем его, проверяем, что оно успешно # отправлено. Репортинг Так как все проверки не занимают много времени, мы отводим для них один Jenkins Job, не распараллеливаем на несколько машин, а последовательно выполняем несколько Rake-тасков. Поэтому каждый модуль такой проверки удовлетворяет определенному интерфейсу, который на выходе дает результат и ошибку, если она есть. Так как информации немного, отдельного HTML-отчета на каждую проверку нет, достаточно встроить эти сведения в итоговый отчет BuildFlow. Выглядит это следующим образом:
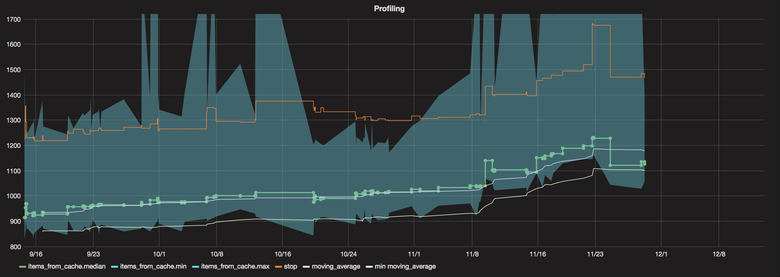
Нажмите на картинку, чтобы увеличить изображение Статический анализ кода scan-build Для статического анализа кода используется scan-build + xcodebuild. Примечательно тут вот что: при сборке мы специально отключаем ассерты. В противном случае scan-build обращает на них внимание и не обрабатывает некоторые кейсы. В релизной версии ассерты отключены, соответственно, в релиз уходит код, кейсы работы которого могут быть не проанализированы и потенциально содержат ошибки. Это и есть основная причина отключения ассертов при статическом анализе — проверка всех кейсов работы кода. Отчет scan-build, как и остальные задачи, встроен в итоговый HTML-отчет. fbinfer Недавно мы встроили в CI анализ кода при помощи утилиты infer. Основная проблема — длительность выполнения. На нашем проекте при чистой сборке весь процесс занимает в среднем 1 час 10 минут. Это объясняется спецификой работы анализатора. Во время компиляции он собирает нужную информацию, чтобы выполнить трансляцию в собственный язык. Трансляция занимает бо́льшую часть времени. Такая длительность никак не вписывается в CI-процесс, который должен быть запущен на каждое изменение, поэтому анализ выполняется отдельно раз в сутки, а ответственному приходит письмо с найденными багами. В целом получилось так, что этот анализатор не вписался в CI, а стал отдельной сторонней профилактической проверкой, потому что мы вливаем изменения с потенциальными багами и только потом их правим. Но пока что практика показывает — то, что находит infer после scan-build, не приводит к проблемам. Профайлинг и тайминги запуска Скорость запуска приложения критически важна. Мы много работали над оптимизацией старта и, чтобы поддерживать достигнутый результат, настроили постоянное профилирование. После каждого мержа и выхода alpha-версии приложения автоматически запускается Downstream Job, чтобы собрать тайминги скорости запуска приложения. Этот Job взаимодействует с реальным девайсом, который всегда работает и доступен. На девайсе выполняется 250 запусков приложения со снятием таймингов. Затем тайминги сохраняются в InfluxDB, после чего визуализируются в Grafana. Таким образом, мы замечаем, если приложение начинает работать медленнее, и знаем, из-за какого изменения это предположительно произошло: каждый тайминг привязан к конкретной сборке, в которую входят известные изменения (обычно одно, но бывает больше).
Нажмите на картинку, чтобы увеличить изображение Unit-тесты С Unit-тестами все достаточно просто — xcodebuild + xcpretty. HTML-отчет xcpretty, как и остальные отчеты, попадает ссылкой в итоговый отчет и сохраняется в артефактах. Unit-тесты — один из параллельных путей нашего BuildFlow. Всего на момент написания статьи у нас был 1451 Unit-тест, тесты выполняются в среднем за 10—11 минут. HipChat и репортинг Репорт о новых задачах Стандартная интеграция Jira + HipChat. За счет этой интеграции мы следим, как меняются состояния задач в проекте, в том числе мы видим создание новых задач и появление багов. Репорт о результатах сборки, тестов, проверок Репортинг — с давних времен нетронутая часть нашей CI-системы. На данный момент выполняется только итоговый репортинг. Это достаточно непросто с учетом распределенности задач. Надо:
У нас есть определенный взгляд на то, куда стремиться. Сейчас полный прогон изменения на CI — Unit-, UI-тесты, статический анализ, проверки проекта — занимает около 55—60 минут без учета очереди. За час ошибка может произойти в любой момент, в том числе в самом начале, на одном из первых тестов/проверок. Но разработчик не узнает о ней, если не будет следить за живыми логами. Чего он, конечно, не делает (и не обязан): логи для тех, кто разрабатывает и отлаживает CI, клиент системы должен видеть только итоговые отчеты и оповещения. Поэтому дальше мы собираемся реализовать Continuous Reporting, чтобы во время прогона держать разработчика в курсе. Чтобы, если ошибки найдутся уже в первые пять минут, можно было начать их исправлять, получив личное оповещение с конкретным описанием и отчетом. Заключение/выводы Мы стараемся проверять самые разные аспекты разработки. Помимо классической автоматизации тестирования и сборки мы реализовали и внедрили в процесс собственные проверки:
Этот комплекс проверок позволяет если не исключить человеческий фактор, то заметно его смягчить, а также иногда выявляет баги в, казалось бы, несвязанных частях. Автоматизация, в свою очередь, сократила длительность ручных проверок, уменьшив интервалы между релизами, и облегчила ручной труд. Тем более что можно выполнять проверки после каждого изменения и обнаруживать проблемы значительно раньше. Даже если после бо́льшей части запусков проблем не обнаруживается, система все равно окупит себя, выявив баг в неочевидном месте. К тому же успешный прогон дает определенную уверенность в каждом изменении в проекте. |
 Автор: Никита Анисимов
Автор: Никита Анисимов