Что пишут в блогах
- Мои 12 недель в году. Часть 26 (Лицензия на ИП и 3-я книжка!)
- Как войти в новый проект: взаимоотношения с командой и пользователями, тестовая лаборатория
- Баги - отдельные задачи или комментарии?
- Митап от Тинькофф “Техтолк инженеров по тестированию” 20 марта 2024
- Опрос: поделитесь мнением про техдолг
- Если вы стали QA-менеджером
- Книга "Баг-трекинг: локализация и оформление дефектов" уже в продаже!
- Топ 30 вопросов на собеседовании на тестировщика ПО (Junior QA)
- Идеальный час
- Обратная связь и самомотивация

Что пишут в блогах (EN)
- Navigating the Future of Software Development: Embracing Collaborative modelling
- In the era of Accessibility Testing
- What If You Are Not Around?
- Five for Friday – April 5, 2024
- The Possible and Impossible: Mathematical Thinking for Planning
- Looking back at Agile Testing, 15 years on
- Does Test Automation Necessarily Make Our Jobs Easier?
- 10 Bad Reasons Why Companies Don’t Hire Testers
- Judging Developers by GitHub Contributions
- Five for Friday – March 29, 2024
Онлайн-тренинги
-
Автоматизация тестов для REST API при помощи PostmanНачало: 25 апреля 2024
-
Школа для начинающих тестировщиковНачало: 25 апреля 2024
-
Python для начинающихНачало: 25 апреля 2024
-
Азбука ITНачало: 25 апреля 2024
-
Тестирование производительности: JMeter 5Начало: 26 апреля 2024
-
Тестирование REST APIНачало: 29 апреля 2024
-
Логи как инструмент тестировщикаНачало: 29 апреля 2024
-
Автоматизатор мобильных приложенийНачало: 1 мая 2024
-
Автоматизация тестирования REST API на PythonНачало: 1 мая 2024
-
Тестирование мобильных приложенийНачало: 1 мая 2024
-
Автоматизация тестирования REST API на JavaНачало: 1 мая 2024
-
Тестирование безопасностиНачало: 1 мая 2024
-
Инженер по тестированию программного обеспеченияНачало: 2 мая 2024
-
Техники локализации плавающих дефектовНачало: 6 мая 2024
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 13 мая 2024
-
Английский для тестировщиковНачало: 13 мая 2024
-
Тестировщик ПО: интенсивный курс со стажировкой (ПОИНТ)Начало: 14 мая 2024
-
Тестирование юзабилити (usability)Начало: 15 мая 2024
-
Регулярные выражения в тестированииНачало: 16 мая 2024
-
Консольные утилиты Android: инструменты тестировщикаНачало: 16 мая 2024
-
SQL: Инструменты тестировщикаНачало: 16 мая 2024
-
Docker: инструменты тестировщикаНачало: 16 мая 2024
-
Git: инструменты тестировщикаНачало: 16 мая 2024
-
Bash: инструменты тестировщикаНачало: 16 мая 2024
-
Charles Proxy как инструмент тестировщикаНачало: 16 мая 2024
-
Chrome DevTools: Инструменты тестировщикаНачало: 16 мая 2024
-
Тестирование веб-приложений 2.0Начало: 17 мая 2024
-
Организация автоматизированного тестированияНачало: 17 мая 2024
-
Школа тест-менеджеров v. 2.0Начало: 22 мая 2024
-
Создание и управление командой тестированияНачало: 23 мая 2024
-
Автоматизация функционального тестированияНачало: 24 мая 2024
-
SQL для тестировщиковНачало: 27 мая 2024
-
Школа Тест-АналитикаНачало: 29 мая 2024
-
Selenium IDE 3: стартовый уровеньНачало: 31 мая 2024
-
Программирование на Java для тестировщиковНачало: 31 мая 2024
-
Погружение в тестирование. Jedi pointНачало: 3 июня 2024
-
Программирование на C# для тестировщиковНачало: 7 июня 2024
-
Аудит и оптимизация QA-процессовНачало: 7 июня 2024
-
Комплексная система подготовки тестировщиков по программе ISTQB FLНачало: 17 июня 2024
-
Selenium WebDriver: полное руководствоНачало: 28 июня 2024
| Тестирование производительности для чайников |
| 05.07.2017 09:53 |
|
Автор: Лукас Розуонек (Łukasz Rosłonek) Перевод: Ольга Алифанова Я заметил, что большинство тестировщиков слабо знакомо с такой областью, как тестирование производительности. В основном мы концентрируем усилия на функциональных аспектах тестирования, оставляя тестирование производительности, масштабируемости и настройки на откуп разработчикам. Но ведь стабильность – важная часть качества продукта, особенно в эпоху распределенных сетей, когда приложения масштабируются независимо и опираются на интеграцию через HTTP-протоколы. Другой аспект качества – способность увеличивать масштаб наших систем. Для того, чтобы справиться с ростом трафика, нужно знать пропускную способность ПО. Инженеры хорошо знакомы с такими инструментами, как JMeter, Gatling, Tsung. Они относительно просты в использовании, но люди зачастую плохо разбираются в анализе выданных ими результатов, и не умеют делать выводы на их основании. Собеседуя кандидатов на должность тест-инженера, я часто встречаю людей, утверждающих, что они имеют опыт тестирования производительности, но не владеющих знаниями о метриках этого вида тестирования, а также о его элементарных положениях. Основная цель нагрузочного тестирования и тестирования производительности – не умение обращаться с соответствующими инструментами, а знания, полученные в результате их использования. Цель этой статьи – осветить основные аспекты этой области.
Тестирование производительности и нагрузочное тестирование Люди зачастую путают нагрузочное тестирование и тестирование производительности. Два этих термина часто используются, как взаимозаменяемые, но это вовсе не так. Цель тестирования производительности – это поиск "бутылочных горлышек" системы или архитектуры. Как говорится, скорость нашей системы – это скорость самого медленного ее компонента. Предположим, что система состоит из нескольких различных микросервисов. У каждого из них есть собственное время отклика и устойчивость к нагрузке. Добавим сюда такие факторы, как тип базы данных, сервера или местоположение дата-центра. Пользователям приложения нужен быстрый отклик системы и ее высокая доступность. Тестируя производительность, мы ищем узкие места в нашей архитектуре и независимо масштабируем и настраиваем микросервисы, чтобы добиться вышеупомянутого быстрого отклика системы целиком. А вот доступность системы оценивается при помощи нагрузочного тестирования. Если в трех словах, тестировать нагрузку – это испытывать нашу систему на прочность при помощи большого количества пользователей или подключений, нагружать ее. Мы постоянно увеличиваем это количество, чтобы определить максимально возможное количество задач, с которым наша система справится. Нагрузочные тесты особенно важны при релизе нового сервиса и проверке, соответствует ли он предположительному трафику. Эти два вида тестирования, хоть и похожие по своей природе и способу проведения тестов, очень различаются в плане анализа результатов и реакции системы. Время ожидания, пропускная способность и ширина канала Как уже говорилось, самое важное в тестировании производительности и нагрузки – это анализ полученных данных. Для его проведения нужно знать основные метрики производительности. В современном мире сетевых коммуникаций очень важно замерять время ожидания, пропускную способность и ширину канала.
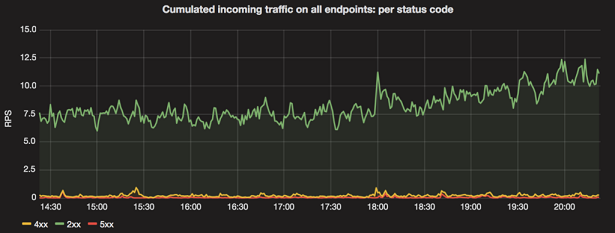
Ширина канала – как правило, величина постоянная (в течение определенного времени). Поэтому очень важно анализировать время ожидания и пропускную способность совместно, потому что эти метрики дают вам ясное представление о производительности системы. Перцентили При измерении времени ожидания одним из первых приходящих в голову сценариев будет расчет среднего времени ожидания за определенное время. Первым измеряемым показателем будет арифметическое среднее, однако здесь есть некоторая проблема: арифметическое среднее очень чувствительно к большому среднеквадратичному отклонению. Так как графики времени ожидания обычно довольно равномерны с небольшими экстремумами, лучше использовать перцентили. Если вы хотите замерить среднее время ожидания вашего сервиса, то можно использовать медиану – 50-й перцентиль (p50). Однако следует помнить, что p50 тоже чувствительно к статистическим флуктуациям. Наиболее распространенная метрика для замера среднего времени ожидания – это 90-й и 99-й перцентили (p90 и p99). К примеру, если время ожидания для p90 составляет 1 мс, то это означает, что в 90% случаев ваш сервис отвечает спустя 1 мс. Частота ошибок Как уже говорилось, мы можем измерить объем полученного трафика, замеряя пропускную способность, однако что насчет исходящего трафика – ответов приложения? Важно знать, какими HTTP-кодами мы отвечаем на запросы – 2хх, 4хх или 5хх. И тут в игру вступает измерение частоты ошибок. Цель этого измерения – узнать, сколько (какой процент) наших ответов успешны, и тому подобные вещи. Какая-то часть исходящего трафика всегда будет с ошибкой (в том числе из-за валидации клиентами – коды 4хх). Однако если в частотности ошибок возникают внезапные пики, это может означать, что в приложении проблемы. Пример графика частоты ошибок приведен на изображении выше. Заключение В последнее время я заметил, что многие тест-инженеры осваивают инструменты тестирования производительности, не имея базовых знаний об этой области тестирования. Чтобы эффективно работать над масштабируемостью и профилированием системы, нужно осознавать, что именно необходимо замерять, и только потом переходить к вопросу, как. |
 Оригинал статьи:
Оригинал статьи: