


Что пишут в блогах
- Мои 12 недель в году. Часть 26 (Лицензия на ИП и 3-я книжка!)
- Как войти в новый проект: взаимоотношения с командой и пользователями, тестовая лаборатория
- Баги - отдельные задачи или комментарии?
- Митап от Тинькофф “Техтолк инженеров по тестированию” 20 марта 2024
- Опрос: поделитесь мнением про техдолг
- Если вы стали QA-менеджером
- Книга "Баг-трекинг: локализация и оформление дефектов" уже в продаже!
- Топ 30 вопросов на собеседовании на тестировщика ПО (Junior QA)
- Идеальный час
- Обратная связь и самомотивация

Что пишут в блогах (EN)
- Five for Friday – April 5, 2024
- The Possible and Impossible: Mathematical Thinking for Planning
- Looking back at Agile Testing, 15 years on
- Does Test Automation Necessarily Make Our Jobs Easier?
- 10 Bad Reasons Why Companies Don’t Hire Testers
- Judging Developers by GitHub Contributions
- Five for Friday – March 29, 2024
- Translating Agile Testing Condensed the unconvential way – part 3
- From Head of QA to Freelancing – Interview with Leonardo
- Five for Friday – March 22, 2024
Онлайн-тренинги
-
Английский для тестировщиковНачало: 22 апреля 2024
-
Школа Тест-АналитикаНачало: 24 апреля 2024
-
Python для начинающихНачало: 25 апреля 2024
-
Автоматизация тестов для REST API при помощи PostmanНачало: 25 апреля 2024
-
Азбука ITНачало: 25 апреля 2024
-
Школа для начинающих тестировщиковНачало: 25 апреля 2024
-
Тестирование производительности: JMeter 5Начало: 26 апреля 2024
-
Логи как инструмент тестировщикаНачало: 29 апреля 2024
-
Тестирование REST APIНачало: 29 апреля 2024
-
Автоматизация тестирования REST API на JavaНачало: 1 мая 2024
-
Тестирование безопасностиНачало: 1 мая 2024
-
Автоматизатор мобильных приложенийНачало: 1 мая 2024
-
Тестирование мобильных приложенийНачало: 1 мая 2024
-
Автоматизация тестирования REST API на PythonНачало: 1 мая 2024
-
Инженер по тестированию программного обеспеченияНачало: 2 мая 2024
-
Техники локализации плавающих дефектовНачало: 6 мая 2024
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 13 мая 2024
-
Тестировщик ПО: интенсивный курс со стажировкой (ПОИНТ)Начало: 14 мая 2024
-
Тестирование юзабилити (usability)Начало: 15 мая 2024
-
Git: инструменты тестировщикаНачало: 16 мая 2024
-
Docker: инструменты тестировщикаНачало: 16 мая 2024
-
Регулярные выражения в тестированииНачало: 16 мая 2024
-
SQL: Инструменты тестировщикаНачало: 16 мая 2024
-
Bash: инструменты тестировщикаНачало: 16 мая 2024
-
Консольные утилиты Android: инструменты тестировщикаНачало: 16 мая 2024
-
Chrome DevTools: Инструменты тестировщикаНачало: 16 мая 2024
-
Charles Proxy как инструмент тестировщикаНачало: 16 мая 2024
-
Тестирование веб-приложений 2.0Начало: 17 мая 2024
-
Организация автоматизированного тестированияНачало: 17 мая 2024
-
Школа тест-менеджеров v. 2.0Начало: 22 мая 2024
-
Создание и управление командой тестированияНачало: 23 мая 2024
-
Автоматизация функционального тестированияНачало: 24 мая 2024
-
SQL для тестировщиковНачало: 27 мая 2024
-
Программирование на Java для тестировщиковНачало: 31 мая 2024
-
Selenium IDE 3: стартовый уровеньНачало: 31 мая 2024
-
Погружение в тестирование. Jedi pointНачало: 3 июня 2024
-
Программирование на C# для тестировщиковНачало: 7 июня 2024
-
Аудит и оптимизация QA-процессовНачало: 7 июня 2024
-
Комплексная система подготовки тестировщиков по программе ISTQB FLНачало: 17 июня 2024
-
Selenium WebDriver: полное руководствоНачало: 28 июня 2024
| Введение в непрерывную интеграцию или каша из топора |
| 24.10.2008 10:12 |
|
Автор: Андрей Сатарин Использование непрерывной интеграции в процессе разработки программного обеспечения обещает много преимуществ: быстрое обнаружение ошибок, устранение проблем интеграции, меньшее число дефектов [1,2]. При более подробном рассмотрении, оказывается, что эта практика сильно зависит от других, таких как модульное тестирование, стандарт кодирования и т.д. Множество ожидаемых преимуществ не реализуются без использования этих дополнительных практик. Складывается парадоксальная ситуация, когда не ясно, имеет ли непрерывная интеграция независимую ценность или вся ценность обусловлена только «сторонними» методиками. Нет ли здесь обмана, когда под предлогом внедрения непрерывной интеграции пытаются использовать преимущества других инженерных практик? Возможно, непрерывная интеграция представляет собой «кашу из топора», все ингредиенты которой давно известны, но теперь поданы вместе под другим названием. В данной статье мы пытаемся показать, что это не так, и непрерывная интеграция имеет свою ценность. Эта ценность существенно ниже, чем синергетический эффект от нескольких практик, но и затраты на внедрение и использование существенно ниже. К тому же, внедрение «голой» непрерывной интеграции может служить и первым шагом к многим другим технологиям эффективной разработки. 1. ВведениеНепрерывная интеграция (continuous integration, далее НИ) первоначально была создана как одна из практик экстремального программирования. Моментом создания считается приблизительно 2000 г., когда была написана первая версия статьи Мартина Фаулера [1]. С того времени она развивалась и изменялось понимание того, как она должна взаимодействовать с другими практиками гибкой разработки. Образцом современного понимания НИ можно считать недавновышедшую книгу Пола Дюваля [2]. В этом достаточно большом и подробном труде выделяется несколько составных частей НИ:
Все эти части подробно описаны и показано как они влияют на процесс разработки. В таком понимании практики НИ можно указать один недостаток — она не является самостоятельной и основная часть выгод получаемых от нее происходит не из нее самой. Выгоды появляются от удачного комбинирования данной практики с другими, такими как: модульное тестирование, автоматическое приемочное тестирование, автоматизированные инспекции кода (рис. 1). С одной стороны хорошо, когда много разнообразных практик вместе дают синергетический эффект, но с другой стороны, это поднимает входной порог использования этой технологии. Т.е. для использования НИ нужно уже иметь модульные тесты, стандарт кодирования и систему его автоматической проверки и т.д. Эта ситуация схожа с описанной в русской народной сказке «Каша из топора» [3]. Постулируется огромная польза от внедрения и использования НИ в проектах разработки ПО, но не уточняется, что большая часть этой пользы происходит не из самой практики, а из ее удачной комбинации с другими сильными методиками. На самом деле, описанные выше условия не являются необходимыми для использования НИ, можно получить выгоду от самостоятельного внедрения НИ, с минимальным привлечением сторонних активностей. В данной статье обсуждается именно такой «упрощенный» способ. 2. Зачем это нужно?Может показаться что «урезанный» вариант НИ, не соответствующий последним достижениям в данной области, бесполезен и только будет отнимать время на внедрение и поддержку. Но это не так, есть круг проблем, которых можно просто и эффективно решить при помощи НИ, не отягощенной другими практиками. Также внедрение НИ, отдельно от других практик, может быть приемлемо для организаций, процесс разработки которых далек от гибких (agile) методологий или для организаций, которые только встают на этот путь. Проблемы, которые на наш взгляд, можно решить внедрением «голой» НИ, описаны в следующем разделе. 2.1. ПроблемыВ целом эти проблемы можно разделить на два вида, те, с которыми сталкиваются тестировщики и те, с которыми сталкиваются разработчики. Для других участников процесса разработки практика НИ также является полезной, но это не так явно выражено. Любое тестирование начинается с получения и развертывания одной из версий ПО. Тестировщики, как правило, не могут собрать проект самостоятельно, для этого у них нет знаний, инструментальных средств (IDE), да и просто навыков. Но любое тестирование начинается с получения готовой к использованию бинарной сборки ПО и его развертывания на тестовом стенде. Для разработчиков, наоборот, собрать проект не составляет труда, эту операцию они проделывают часто и много. Кажется, это и есть решение проблемы. Нет. При передаче версии от разработчиков могут возникнуть сомнения в целостности передаваемой сборки:
На эти вопросы ответить не так просто, а проконтролировать каждого разработчика — еще сложнее. Многие скажут, что для сборки, развертывания и передачи ПО в тестирование должна существовать особая роль — инженер по сборке (build engineer), или даже целое подразделение сотрудников, но в небольших проектах такое просто невозможно. Конечно, эту роль может исполнять кто-то из членов команды, и, на первый взгляд, это кажется разумным. На самом деле, это лишь способ скрыть проблемы, но не избавиться от них. Возникнет консервация уникального знания и навыка в голове одного человека и связанные с этим риски:
Можно идти путем регламентов, которые контролируют окружение и процедуру сборки, но такие регламенты сложно исполнять и еще более сложно поддерживать. Программисты не могут заниматься исполнением желаний тестировщиков: собирать проект по требованию, жестко контролировать окружение, в котором происходит сборка. Это тупиковый путь.
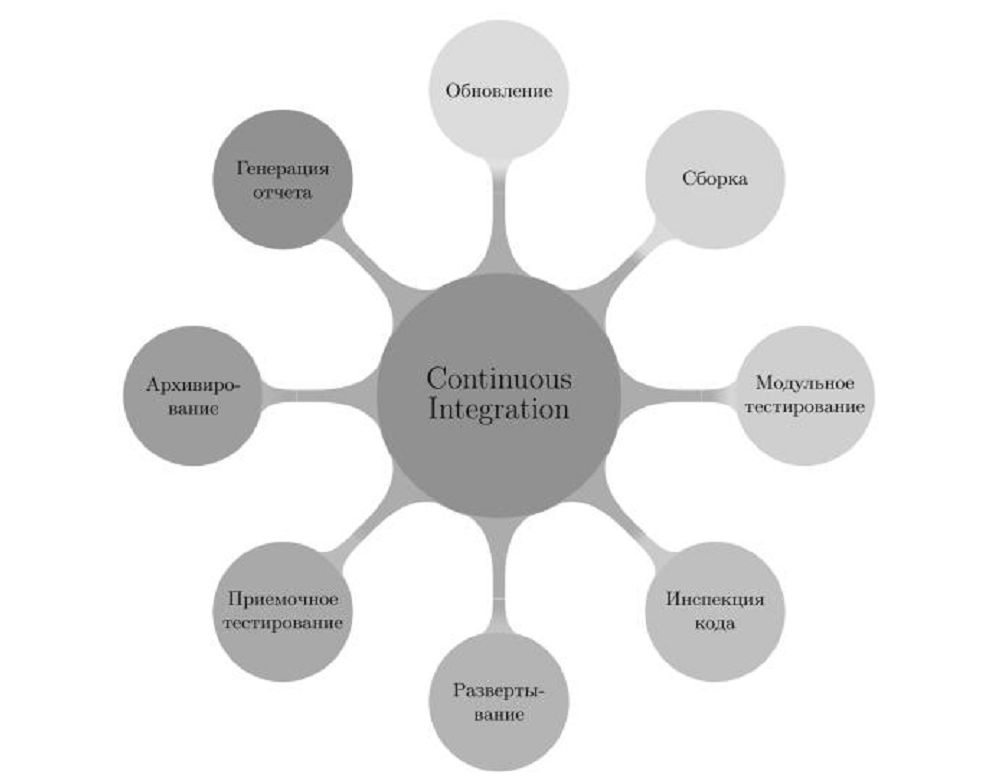
Рисунок 1. Составные части полного процесса непрерывной интеграции. Сами разработчики тоже часто являются источником проблем. Такие проблемы могут быть охарактеризованы следующими фразами:
Особенно хороша первая проблема, вокруг этой фразы («It works on my machine!») даже возникла субкультура [4], но разработчики все равно продолжают повторять ее снова и снова. В борьбе с этим злом НИ особенно хороша. Кому-то эти проблемы могут показаться смешными или надуманными, тем не менее, в разработке такое часто случается. Раннее обнаружение этих проблем экономит много времени и денег. В итоге получается, что есть некий объем работ (сборка, развертывание и т.д.), который должен выполняться для того, чтобы контролировать (в некоторой степени) состоянии производимого ПО. Практика НИ призывает избавиться от этих рутинных операций посредством их автоматизации и передаче машине. 3. РешениеАвтоматизация здесь — это в первую очередь автоматизация сборки, развертывания, обратной связи. Все эти автоматические процедуры связываются воедино на специальной интеграционной машине, а управление процедурами осуществляет сервер интеграции. Базовая схема организации процесса интеграции показана на рис. 2. На схеме выделены следующие этапы:
Это практически минимальный набор этапов, при котором можно говорить о процессе НИ. В некоторых случаях можно убрать этап развертывания, если для программы этого не требуется. Остальные этапы, безусловно, необходимы. Рассмотрим подробно, что происходит на каждом из указанных этапов. Вначале сервер интеграции обновляет дерево исходных кодов проекта до последней свежей версии, это можно делать как по расписанию, так и при каждом изменении исходных кодов. Далее идет сборка. Сборка на интеграционном сервере отличается от сборки на локальной машине разработчика. Чем они отличаются и зачем? Современные сервера интеграции позволяют передавать метку (номер версии) в качестве параметра сборки. Рекомендуется включать этот параметр на видном месте в результирующий продукт, например, в информации о программе, которую может посмотреть пользователь. Кроме того, окружение на сборочной машине контролируется более жестко. После этого, готовый продукт разворачивается в окружении. Важным моментом является, какое именно окружение использовать для развертывания в данном случае. Один из авторов практики НИ Мартин Фаулер советует делать это в промышленном окружении [2]. После развертывания идет этап архивирования, на котором происходит сохранение результатов сборки для дальнейшего использования. Таким использованием может быть тестирование, демонстрация, воспроизведение проблем в ранних версиях. Кроме того на данном этапе может происходить пометка кода тегом в репозитории, для того, чтобы можно было всегда повторить данную сборку. Обычно тег совпадает с номером версии, ранее сгенерированным сборочным сервером. После того, как все сделано, наступает этап генерации отчета и сервер оповещает разработчиков о результатах. Оповещение можно разделить на два типа: активное и пассивное. К первому относится email, системы мгновенных сообщений, мониторы. Второй тип — это публикация на веб или файловом сервере.
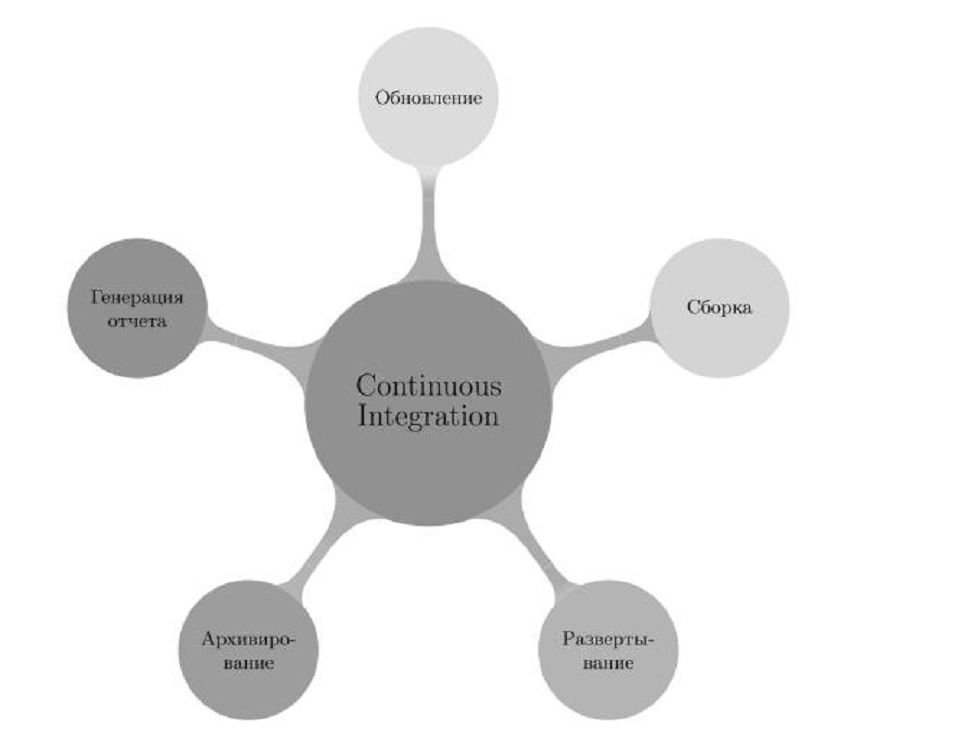
Рисунок 2. Составные части базового процесса непрерывной интеграции. 4. ПримерРассмотрим пример использования описанного подхода «голой» непрерывной интеграции в проекте разработки веб приложения на платформе java. В качестве средства управления версиями использовался Subversion, который поддерживается большинством широко распространенных серверов сборки. Сами средства сборки стандартны для платформы java — это ant и maven. Такая комбинация с одной стороны предоставляют большие возможности при управлении сборкой проекта в целом, а с другой стороны позволяет просто автоматизировать смежные этапы. Более нестандартной является реализация этапа развертывания. В первую очередь из-за того, что стандартного механизма развертывания для различных серверов приложений не существует. Мы, в данном случае, мы выбрали достаточно простой способ. Развертывание происходит на том же сервере, что и сборка, поэтому возможна подмена файлов приложения. После такой подмены сервер приложений (в нашем случае Resin) сам производит развертывание. К сожалению это не все, что нужно сделать для запуска веб приложения, необходимо так же развернуть свежую версию базы данных. Свежую, значит ту, которая находится в репозитории, а где ее еще хранить? Для этой проблемы так же нет стандартного решения. Изначально мы пошли по очень простому и неправильному пути — стали хранить полный дамп базы в репозитории. Недостатки данного подхода очевидны: невозможность простого сравнения версий, неудобство работы с бинарным файлом. Гораздо более прогрессивным оказался метод хранения описания базы в SQL. Все современные средства работы с базой позволяют просто и удобно проводить экспорт таких скриптов. Такой подход к хранению структуры базы оказался существенно более удобным и не имеет указанных выше недостатков. Последние этапы процесса непрерывной интеграции: архивирование и генерация отчета легко реализуются средствами практически любого специализированного сервера. В итоге получилась система, которая производит сборку, развертывание и оповещение в случае каких-либо проблем. Конечно, она не способна отловить все проблемы (а какая система способна?), но даже такой простой «фильтр» умеет вылавливать некоторые из них. Прочие преимущества и недостатки описаны в следующем разделе. 5. Преимущества и недостатки подходаВыгода первая — избавление от рутины. Не надо объяснять, что профессионалы не любят рутину, кроме того, время людей становится все дороже, а время машин все дешевле. Выгода вторая — простота и повторяемость. Кто угодно — любой участник проекта: тестировщик, аналитик и т.д. может собрать и запустить проект, потому что все эти операции автоматизированы. Совершить ошибку при этом невозможно. Выгода третья — незаметность. На первых этапах использования большинству участников разработки нет необходимости что-то менять в их работе. Сравните это с такими «тяжелыми» практиками как разработка через тестирование (TDD), где разработчику надо практически поменять мировоззрение или внедрение автоматического приемочного тестирования, где тестировщику предлагается писать код. Если изменения в работе людей практически отсутствуют, они не будут сопротивляться внедрению и использованию НИ. Как уже отмечалось, при комбинировании НИ с другими практиками получается синергетический эффект, но этот случай за пределами рассмотрения данной статьи. Есть ли недостатки у практики НИ? Безусловно, но они не так значительны как преимущества. Например, к недостаткам относят необходимость иметь выделенный сервер, тратить время на поддержку работы этого сервера. Первый аргумент с каждым днем все слабее и слабее, железо стоит все меньше и меньше по сравнению с временем разработчика. Относительно второго аргумента можно сказать о нашем опыте. Время на поддержание сервера совершенно незначительно по сравнению со временем на обнаружение проблем другим способом и запоздалое их устранение. 6. ЗаключениеПрактика НИ тесно переплетена с другими практиками гибкой (agile) разработки: модульное тестирование, приемочное тестирование, стандарт кодирования, но она может применяться и без них. Мы не отрицаем преимуществ этих практик, особенно в комбинации с НИ, но их внедрение — отдельная задача. Внедрить несколько таких «ресурсоемких» технологий сразу невозможно, как бы ни призывали различные гуру. Это можно сделать только по частям. Например, сначала внедрить «голую» НИ, а затем к ней постепенно присоединять другие методики. При этом необходимо последовательное «наращивание» шагов включаемых в сборку. Т.о. непрерывная интеграция объединит вокруг себя несколько других инженерных практик, и благодаря этому может стать центром вашего процесса разработки. 7. Литература[1] Мартин Фаулер (Martin Fowler) ― Continuous Integration http://www.martinfowler.com/articles/continuousIntegration.html [2] Duvall, Paul and Matyas, Steve and Glover, Andrew ― Continuous Integration. Improving Software Quality and Reducing Risk, Addison-Wesley, 2007. [3] «Каша из топора», русская народная сказка http://www.skazki.org.ru/view.php?id=7073 см. также http://en.wikipedia.org/wiki/Stone_Soup http://www.google.com/search?q=It+works+on+my+machine! (!) Публикуется с разрешения оргкомитета Software Engineering Conference (Russia) 2008
|