Что пишут в блогах
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Использование MS Excel в качестве унифицированного хранилища данных для автоматизированных тестов |
| 12.12.2008 13:33 |
|
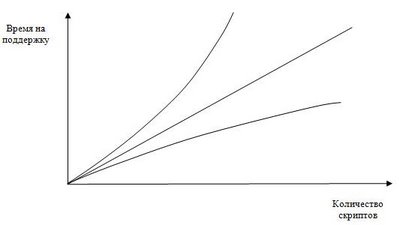
Полная "режиссерская" версия доклада, сделанного SQA Days 2008Автор: Сергей Талалаев Доклад затрагивает проблему выбора унифицированного хранилища тестовых данных для проведения автоматизированных функциональных и нагрузочных тестов. 1. Предыстория1.1 Автоматизация: от эйфории до созерцанияЕсть несколько типичных ошибок, которые допускаются при первых попытках внедрения автоматизации функционального тестирования. Эти ошибки допускаются естественно из-за отсутствия опыта в такого вида разработках и кроме того в некоторой степени ”поощряются” кажущейся легкостью работы в современных тестовых фреймворках при использовании механизмов макрозаписи (трансляции действий пользователя напрямую в тестовый скрипт). К сожалению подход при котором вся тестовая команда записывает килотонны кода, что вызывает невиданный прилив энтузиазма как у самих членов команды так и у руководства, приводит в конце концов к плачевным результатам. Рано или поздно наступает тяжелый момент, когда нужно остановиться, отдышаться и трезвым взглядом посмотреть на дело рук своих, чтобы трезво оценить во что же выльется переделка. В нашем случае ситуация оказалась настолько запущенной, что было принято решении отказаться от существующих скриптов такого вида и написании их с нуля в строгом соответствии с оговоренными правилами которые впоследствии оформились в документ под названием “Test scriprting guideline”. Я сознательно ушел от подробного разбора причин, которые привели к необходимости столь радикальных действий, чтобы детально рассмотреть их в следующей части доклада. 1.2 Проблема больших чиселСформулировать её можно следующим образом: при увеличении масштаба процесса на первый план выходят совершенно неучтенные и казалось бы незначительные факторы. Правило очень актуальное для экспериментальных областей физики и химии оказывается как нельзя кстати и в процессе разработки автоматизированных тестов. Существует много возможностей для применения этого правила с точки зрения оптимизации процесса, но мы остановимся на следующей зависимости: Количество скриптов : Время затрачиваемое на их поддержкуЕсли отобразить эту зависимость в виде графика где по оси Х будет отображаться количество скриптов а по оси Y – время необходимое для поддрежки этого количства скриптов, то мы получим три варианта развития событий. Для того чтобы поддержка скриптов не легла непосильным бременем на тестовую команду при разработке тестов нужно обязательно уделять внимание таким моментам как:
Несомненно все три озвученных практики являются важными, но согласно выбранной тематики доклада детальному разбору подвергнем лишь последнюю из этого списка. 1.3 Идентификация проблемы.Попытаемся сформулировать требования, которым должно удовлетворять внешнее хранилище данных и на основании этих требований оценить возможные варианты реализации. 2. Стандартные решения – достоинства и недостатки2.1 Реализация внутренних хранилищ в семействах продуктов IBM RationalВ качестве встроенного хранилища данных в семействе продуктов Rational используются так называемые Датапулы (Datapools). Они представляют собой некий урезанный вариант таблиц базы данных. Из положительных сторон можно отметить:
Из минусов:
2.2 Реализация внутренних хранилищ в семействах продуктов HP MercuryВ качестве встроенного хранилища данных в семействе продуктов HP Mercury используются стандартные Excel файлы. Из положительных сторон можно отметить:
Из минусов:
2.3 Другие варианты хранения данных
Неудобство работы напрямую в файле. При использовании того же Excel в качестве редактора получаем 2-х проходную работу. Проблемы с группировкой и отсутствием валидации на входе.
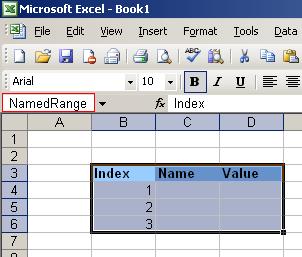
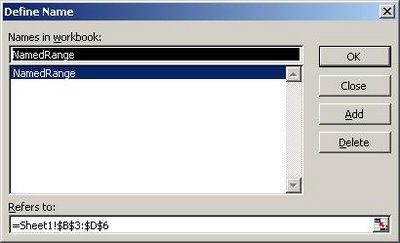
Персонал должен как минимум понимать структуру XML, владеть одним из редакторов для манипуляции с файлами такого вида. Сложно задается валидация входных значений. 3. Поиск компромисса3.1 Почему Excel?При выборе варианта хранилища данных мы в качестве основного критерия выбрали удобство подготовки и редактирования данных. Акцент при выборе был сознательно смещен в эту сторону так как продукт был действительно большим и сложным и без помощи функциональной тестовой команды автоматизаторам было бы нереально подготовить такой объем данных. 3.2 Хитрости и трюкиДля того чтобы получить видимые для ODBC таблицы в Excel- файле вы должны определенным образом разметить интересующие вас подмножества ячеек. Для этой цели служит функциональность называемая Names (именованные диапазоны). Создать именованный диапазон можно через “Define name” диалог (Insert > Name > Define) или через Formulas > Define Name в 2007-ом офисе. После такого выделения ваши имена становятся доступны как таблицы для ODBC драйвера. Для проверки того что диапазон задан верно необходимо выделить помеченные ячейки и в Navigation bar должно отбразиться заданное имя.
3.3 «Ложка дегтя»: ограничения использованияКонечно все это было бы слишком хорошо если бы не было каких-либо ограничивающих факторов и они к сожалению есть:
Но из своей практики могу отметить, что эти ограничения не являются критичными для большинства тестовых проектов. 4. Из личного опыта: «Датадривен – это просто»4.1 Задача: разработать автоматические тесты с возможностью кастомизации без изменения кода.Кастомизация предполагалась следующая:
То есть было необходимо предусмотреть возможность запуска скриптов с разными наборами тестовых данных и также возможность отключения точек проверки для случая заполнения данных. 4.2 Вариант решения
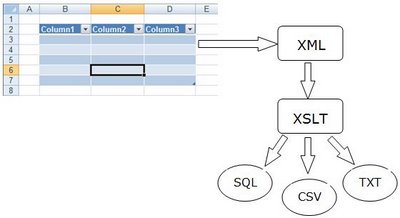
Реализация озвученных механизмов естественно потребовала четкой унификации структуры разрабатываемых скриптов, что было зафиксировано в руководстве по разработке скриптов. 4.3 Анализ полученного результатаВ результате мы получили достаточно гибкую структуру решающую все поставленные задачи. Кроме того строгая унификация подходов к разработке избавляла нас от серьезных временных затрат при вхождении нового человека в команду автоматизации и при отладке скриптов после изменения UI. 5. Непознанный мир Excel5.1 Возможность использования Excel в качестве источника XML-данныхНачиная с 2003-ей версии офиса в Excel появилась возможность интеграции с XML, причем как в сторону загрузки данных в Excel таблицы так и в сторону экспорта табличных данных в XML файл. Эта функциональность (называемая в офисе 2003 Lists а в 2007 – Tables) добавила еще больше гибкости в процедуру подготовки тестовых данных. Теперь появилась возможность оперировать с текстовыми данными практически любого вида. Единственно, что требуется дополнительно реализовать - это XSLT преобразование из полученного в процесе экспорта XML файла к требуемому для приложения виду.
5.2 Варианты примененияЛежащий на поверхности путь преобразования – это подготовка прямых SQL операторов для прямой заливки данных в базу. Кроме того могут понадобиться какие-либо специфичные форматы данных в основе которых лежат табличные данные (например, данные для Web- сервисов). Очевидное преимущество получаемое от такой схемы работы – это простота поддержки и модификации наряду с гибкостью по отношению к выходным форматам. 6. Из личного опыта: «Пойди туда, не знаю куда – найди то, не знаю что»6.1 Задача: протестировать процедуру миграции БДОсобенность задачи состояла в том, что заказчик (очень крупная страховая компания) неохотно шел на предоставление информации о структуре данных в старой БД. Не могу сказать что это было вызвано прямым нежеланием сотрудничать с нами. Вероятнее всего желание сотрудничества терялось где-то в хитросплетениях бюрократических процедур и просто не доходило до конкретного исполнителя. Тем не менее сроки для нас были поставлены достаточно жесткие и аппелировать потом к совести заказчика потрясая кипой грозных писем с нашей стороны особого желания не было. На тот момент функционал по миграции уже более менее был готов к тестированию и для набивки тестовых данных не хватало детализации старой структуры в которую требовалось эти данные загружать. Таким образом мы понимали, что подготовленные нами данные (а они естественно должны были быть в виде скриптов БД) обязательно потребуют модификации после уточнения оставшихся вопросов. 6.2 Вариант решенияВот тут как нельзя кстати пригодилась новая функциональность Excel позволяющая выгружать данные в XML. Мы сначала подготовили данные для понятных нам тестовых случаев и согласно предполагаемой структуре сделали прослойку для генерации скриптов (то есть приготовили набор XSL файлов необходимый для конвертации выгружаемых XML в требуемый нам формат). Имея на руках уже готовые тестовые данные разговаривать с заказчиком стало гораздо проще. Стало очевидным что с нашей стороны были сделаны все шаги и без их активного участия дальше двигаться невозможно. Поэтому началось активное общение с разбором возникающих проблем и постепенное доведение наших скриптов до рабочего состояния. 6.3 Анализ полученного результатаИз несомненных плюсов примененного подхода хочется отметить, что мы смогли начать работу даже не имея на руках полностью разжеванной спецификации по БД, что при любых других вариантах решения привело к большим затратам по модификации готовых сриптов. Нам этого удалось избежать, сохранив по максиму уже подготовленные данные. Из минусов или скажем так из особенностей нужно отметить что на стороне тестовой команды должен был присутствовать человек имеющий опыт работы с XML+XSLT. Но это, я считаю, является очень хорошим стимулом к изучению на практике новых областей не совсем типичных для просто функционального тестирования. 7. Из личного опыта: «Хотели бы помочь, но по-своему»7.1 Задача: получить тестовые данные для проведения UAT от заказчикаВ ходе работ по ”оживлению” старого демо-приложения выяснилось, что мы не можем убедиться в корректности работы функциональности отчетов в восстановленном функционале из-за полного отсутствия документации на эту часть приложения. Заказчик воспринял ситуацию адекватно и предложил свою помощь в разрешении проблемы, а именно предложил нам взять на себя подготовкку тестовых данных для этой части функционала. Наша радость к сожалению была очень недолгой, когда мы увидели в каком виде к нам начали приходить эти данные. Ни о какой организованной струтуре речи ни шло. Данные для полей с ограниченным набором списковых значений например могли отличаться от набора к набору ( как пример в одном наборе период назывался “semi-annual”, а в другом – “Semi annual”). Мы пришли к выводу, что на вычистку таких данных уйдет больше времени, если они не будут жестко следовать предопределенному формату. 7.2 Вариант решенияРешено было на основании уже полученных первых данных от заказчика и дальнейших консультаций подготовить шаблон для ввода данных с жесткими ограничениями на вводимые данные. В качестве оболочки для создания такого шаблона был выбран Excel с его функциональностью по валидации вводимых данных. Использовались такие типы валидаии как
В дальнейшем предполагалось использовать механизм выгрузки подготовленных данных в XML формат и конвертацию полученных XML файлов в последовательность SQL-операторов для загрузки данных напрямую в БД. 7.3 Анализ полученного результатаШаблоны были успешно подготовлены, опробованы и отосланы заказчику для продолжения работы по набивке данных. Но видимо первый порыв альтруизма уже прошел и дальнейшего продолжения эта история увы не получила. Тем не менее мы со своей стороны получили опыт в реализации шаблонов для входных данных, который несомненно пригодится в будущем.
Обсудить в форуме
|