Что пишут в блогах
- Как избежать узких мест в тестировании программного обеспечения
- Системы управления требованиями в России: зачем они нужны и что выбрать в 2024
- СДВГ помогает работать в тестировании: разрушаю стереотипы
- Мои 12 недель в году. Часть 28 (няни и курс по GraphQL)
- Тестирование на основе свойств: подход, ускоряющий релиз
- Автоматизированное тестирование — Уровни пирамиды Кона
- Аудит тестирования: как понять, что он нужен?
- Cards — бесплатная песочница с GraphQL API
- Почему мы устанавливаем и тут же удаляем приложения?
- Топ-5 ошибок при проведении функционального тестирования web-приложений

Что пишут в блогах (EN)
- Tester vs Quality Engineer: Which One Are You?
- How To Fail With Software Testing
- Not an ad but a review: Copado Robotic Testing
- Complexity draws us to low-code solutions
- Mobile App Analytic Tools
- The Agile Testing Quadrants
- Five for Friday – October 11, 2024
- Security testing your APIs - Unrestricted Resource Consumption
- Open Security Conference 2024 - A Memorable Beginning
- Once Again: The Created Artifact Isn’t the Point; The Creative Process Is
Онлайн-тренинги
-
Тестирование производительности: JMeter 5Начало: 1 ноября 2024
-
Логи как инструмент тестировщикаНачало: 4 ноября 2024
-
Тестировщик ПО: интенсивный курс со стажировкой (ПОИНТ)Начало: 5 ноября 2024
-
Тестирование юзабилити (usability)Начало: 6 ноября 2024
-
Python для начинающихНачало: 7 ноября 2024
-
Азбука ITНачало: 7 ноября 2024
-
Инженер по тестированию программного обеспеченияНачало: 7 ноября 2024
-
Создание и управление командой тестированияНачало: 7 ноября 2024
-
Регулярные выражения в тестированииНачало: 7 ноября 2024
-
Организация автоматизированного тестированияНачало: 8 ноября 2024
-
Тестирование веб-приложений 2.0Начало: 8 ноября 2024
-
Тестирование REST APIНачало: 11 ноября 2024
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 11 ноября 2024
-
Английский для тестировщиковНачало: 11 ноября 2024
-
Автоматизатор мобильных приложенийНачало: 13 ноября 2024
-
Автоматизация тестирования REST API на JavaНачало: 13 ноября 2024
-
Автоматизация тестирования REST API на PythonНачало: 13 ноября 2024
-
Тестирование мобильных приложений 2.0Начало: 13 ноября 2024
-
Тестирование безопасностиНачало: 13 ноября 2024
-
Школа для начинающих тестировщиковНачало: 14 ноября 2024
-
Тестирование GraphQL APIНачало: 14 ноября 2024
-
Программирование на Java для тестировщиковНачало: 15 ноября 2024
-
Автоматизация функционального тестированияНачало: 15 ноября 2024
-
SQL для тестировщиковНачало: 18 ноября 2024
-
Техники локализации плавающих дефектовНачало: 18 ноября 2024
-
Школа тест-менеджеров v. 2.0Начало: 20 ноября 2024
-
Charles Proxy как инструмент тестировщикаНачало: 21 ноября 2024
-
CSS и Xpath: инструменты тестировщикаНачало: 21 ноября 2024
-
Автоматизация тестов для REST API при помощи PostmanНачало: 21 ноября 2024
-
Программирование на C# для тестировщиковНачало: 22 ноября 2024
-
Погружение в тестирование. Jedi pointНачало: 25 ноября 2024
-
Школа Тест-АналитикаНачало: 27 ноября 2024
-
Bash: инструменты тестировщикаНачало: 28 ноября 2024
-
Docker: инструменты тестировщикаНачало: 28 ноября 2024
-
SQL: Инструменты тестировщикаНачало: 28 ноября 2024
-
Chrome DevTools: Инструменты тестировщикаНачало: 28 ноября 2024
-
Git: инструменты тестировщикаНачало: 28 ноября 2024
-
Selenium IDE 3: стартовый уровеньНачало: 29 ноября 2024
-
Программирование на Python для тестировщиковНачало: 29 ноября 2024
-
Аудит и оптимизация QA-процессовНачало: 6 декабря 2024
| Новая функциональность без багов, на примере биллинга для мобильного оператора |
| 03.12.2020 00:00 |
|
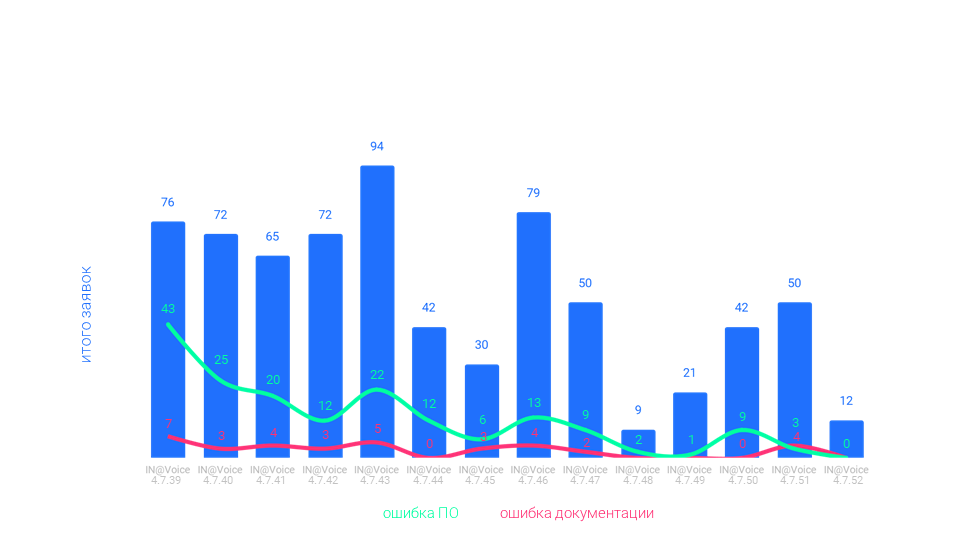
Ноль ошибок по итогам интеграционных тестов – тут речь о тестировании новой функциональности на бизнес-приёмке на стороне оператора. Пара слов о том, как устроено это тестирование. Зона дискомфортаНа момент начала описываемой истории, два года назад, мы имели следующую картину:
Ошибки, которые можно было найти по результатам интеграционных тестов, могли быть минорными («часть сообщения отображается в виде прочерков») или даже критическими («не происходит переход на другой тариф»). Точки ростаГлавный инструмент интеграционного тестирования – тестовый стенд. Там происходит эмуляция деятельности абонента. Общие стендыНа тестовые стенды накатываются дампы с продакшена – чтобы можно было тестировать в условиях, максимально приближенных к боевым. Проверка настроек перед тестированиемКогда мы отдаём новую версию софта оператору, для тестирования на стороне заказчика нужно сделать настройку. Настроить новую функциональность, возможно, дополнительно настроить старую. Дополнительные коммуникации вокруг документацииПроверка настроек перед тестированием вдобавок к описанию этих настроек в мануалах – это один пример дополнительных коммуникаций вокруг документации. Были и другие. Экспертиза по работе со сторонними системамиДля разработки биллинга нам нужно уметь вести учёт трафика. Для этого существуют отдельные PCRF-системы. Учёт звонков происходит в одной базе, СМС там же, а трафика – в другой базе; и есть специальное ПО, которое это всё синхронизирует. Больше стендовЕщё одна особенность в тестировании биллинга мобильных операторов – пользовательские сценарии могут быть растянуты во времени. Полный сценарий, который мы хотим проверить, может занимать несколько дней или даже недель. ВиртуализацияПодготовка стенда – небыстрый процесс. Нужно подключиться к сети оператора, запросить доступы, и это ещё не всё. Полная процедура могла занимать до нескольких недель. Борьба за сокращение времени подготовки стенда была важным направлением в движении к цели в ноль ошибок. ПланированиеОшибки из интеграционных тестов – это ещё и результат просчётов в планировании релиза. Замахнулись на много, на момент фиксированной даты релиза успели не всё. Саппорт и релиз параллельноВ начале нашего пути случалась ситуация, когда “долги” прошлого релиза конфликтовали с релизом следующим. После приёмки на стороне заказчика приезжали баги, все дружно отправлялись их чинить. Главный инструментУлучшение, которое помогло нам больше всего – честные постмортемы.
Приглашаем расширенный состав участников. Разработчиков, тестировщиков, аналитиков, менеджеров, руководителей – всех, у кого есть желание высказаться. Организационно, собрать всех-всех не всегда получается. Это ок, так тоже работает. Речь о том, чтобы не отказывать в участии коллегам с формулировкой “мы тут в своей команде итоги подводим, вы в своей подведите”. Работа со стендами, код, процессы, взаимодействие – стремимся не упустить из виду ни одного аспекта.
Ок, по итогам постмортема мы придумали 30 точек роста. Сколько брать в работу? Может, у нас получится решить все до следующего раза? Для нас лучше всего сработал формат «выбрать 2-3». При таком раскладе есть фокус, и усилия людей в команде не распыляются. Лучше сделать меньше, но полностью, чем много, но не довести до ума.
Существует масса подходов к проведению постмортемов. Фасилитационные практики, приёмы из дизайн-мышления и латерального мышления, техника Голдратта и других уважаемых экспертов. По нашему опыту для старта достаточно здравого смысла. Записали проблемы, сгруппировали, выбрали несколько кластеров, отодвинули в сторону остальное (см. предыдущий пункт), обсудили, зафиксировали план. Когда есть единая цель, найти общий язык не так сложно.
Пожалуй, главный принцип в этом списке. Каким бы перспективным и убедительным ни получился список улучшений по итогам постмортема, если он не идёт в работу, то всё зря. Договорились, значит, делаем. Да, есть другие срочные дела. Но ещё у нас есть цель, и мы хотим к ней приближаться. Самый главный инструментПостмортем позволяет находить средства для достижения цели, но если разобраться, то и его можно назвать следствием более высокоуровневого принципа.
И дальше в том же духе. В движении к цели в ноль ошибок в релизе было ещё много всего. Работа над улучшением документации, повышение скорости и качества реакции на вопросы заказчика – разное. В этот раз я постарался поделиться только некоторыми примерами и рассказать о базовых принципах. |