Что пишут в блогах
- Как избежать узких мест в тестировании программного обеспечения
- Системы управления требованиями в России: зачем они нужны и что выбрать в 2024
- СДВГ помогает работать в тестировании: разрушаю стереотипы
- Мои 12 недель в году. Часть 28 (няни и курс по GraphQL)
- Тестирование на основе свойств: подход, ускоряющий релиз
- Автоматизированное тестирование — Уровни пирамиды Кона
- Аудит тестирования: как понять, что он нужен?
- Cards — бесплатная песочница с GraphQL API
- Почему мы устанавливаем и тут же удаляем приложения?
- Топ-5 ошибок при проведении функционального тестирования web-приложений

Что пишут в блогах (EN)
- Tester vs Quality Engineer: Which One Are You?
- How To Fail With Software Testing
- Not an ad but a review: Copado Robotic Testing
- Complexity draws us to low-code solutions
- Mobile App Analytic Tools
- The Agile Testing Quadrants
- Five for Friday – October 11, 2024
- Security testing your APIs - Unrestricted Resource Consumption
- Open Security Conference 2024 - A Memorable Beginning
- Once Again: The Created Artifact Isn’t the Point; The Creative Process Is
Онлайн-тренинги
-
Тестирование производительности: JMeter 5Начало: 1 ноября 2024
-
Логи как инструмент тестировщикаНачало: 4 ноября 2024
-
Тестировщик ПО: интенсивный курс со стажировкой (ПОИНТ)Начало: 5 ноября 2024
-
Тестирование юзабилити (usability)Начало: 6 ноября 2024
-
Python для начинающихНачало: 7 ноября 2024
-
Азбука ITНачало: 7 ноября 2024
-
Инженер по тестированию программного обеспеченияНачало: 7 ноября 2024
-
Создание и управление командой тестированияНачало: 7 ноября 2024
-
Регулярные выражения в тестированииНачало: 7 ноября 2024
-
Организация автоматизированного тестированияНачало: 8 ноября 2024
-
Тестирование веб-приложений 2.0Начало: 8 ноября 2024
-
Тестирование REST APIНачало: 11 ноября 2024
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 11 ноября 2024
-
Английский для тестировщиковНачало: 11 ноября 2024
-
Автоматизатор мобильных приложенийНачало: 13 ноября 2024
-
Автоматизация тестирования REST API на JavaНачало: 13 ноября 2024
-
Автоматизация тестирования REST API на PythonНачало: 13 ноября 2024
-
Тестирование мобильных приложений 2.0Начало: 13 ноября 2024
-
Тестирование безопасностиНачало: 13 ноября 2024
-
Школа для начинающих тестировщиковНачало: 14 ноября 2024
-
Тестирование GraphQL APIНачало: 14 ноября 2024
-
Программирование на Java для тестировщиковНачало: 15 ноября 2024
-
Автоматизация функционального тестированияНачало: 15 ноября 2024
-
SQL для тестировщиковНачало: 18 ноября 2024
-
Техники локализации плавающих дефектовНачало: 18 ноября 2024
-
Школа тест-менеджеров v. 2.0Начало: 20 ноября 2024
-
Charles Proxy как инструмент тестировщикаНачало: 21 ноября 2024
-
CSS и Xpath: инструменты тестировщикаНачало: 21 ноября 2024
-
Автоматизация тестов для REST API при помощи PostmanНачало: 21 ноября 2024
-
Программирование на C# для тестировщиковНачало: 22 ноября 2024
-
Погружение в тестирование. Jedi pointНачало: 25 ноября 2024
-
Школа Тест-АналитикаНачало: 27 ноября 2024
-
Bash: инструменты тестировщикаНачало: 28 ноября 2024
-
Docker: инструменты тестировщикаНачало: 28 ноября 2024
-
SQL: Инструменты тестировщикаНачало: 28 ноября 2024
-
Chrome DevTools: Инструменты тестировщикаНачало: 28 ноября 2024
-
Git: инструменты тестировщикаНачало: 28 ноября 2024
-
Selenium IDE 3: стартовый уровеньНачало: 29 ноября 2024
-
Программирование на Python для тестировщиковНачало: 29 ноября 2024
-
Аудит и оптимизация QA-процессовНачало: 6 декабря 2024
| Модель тест-покрытия "1-2-3" |
| 09.08.2023 00:00 |
|
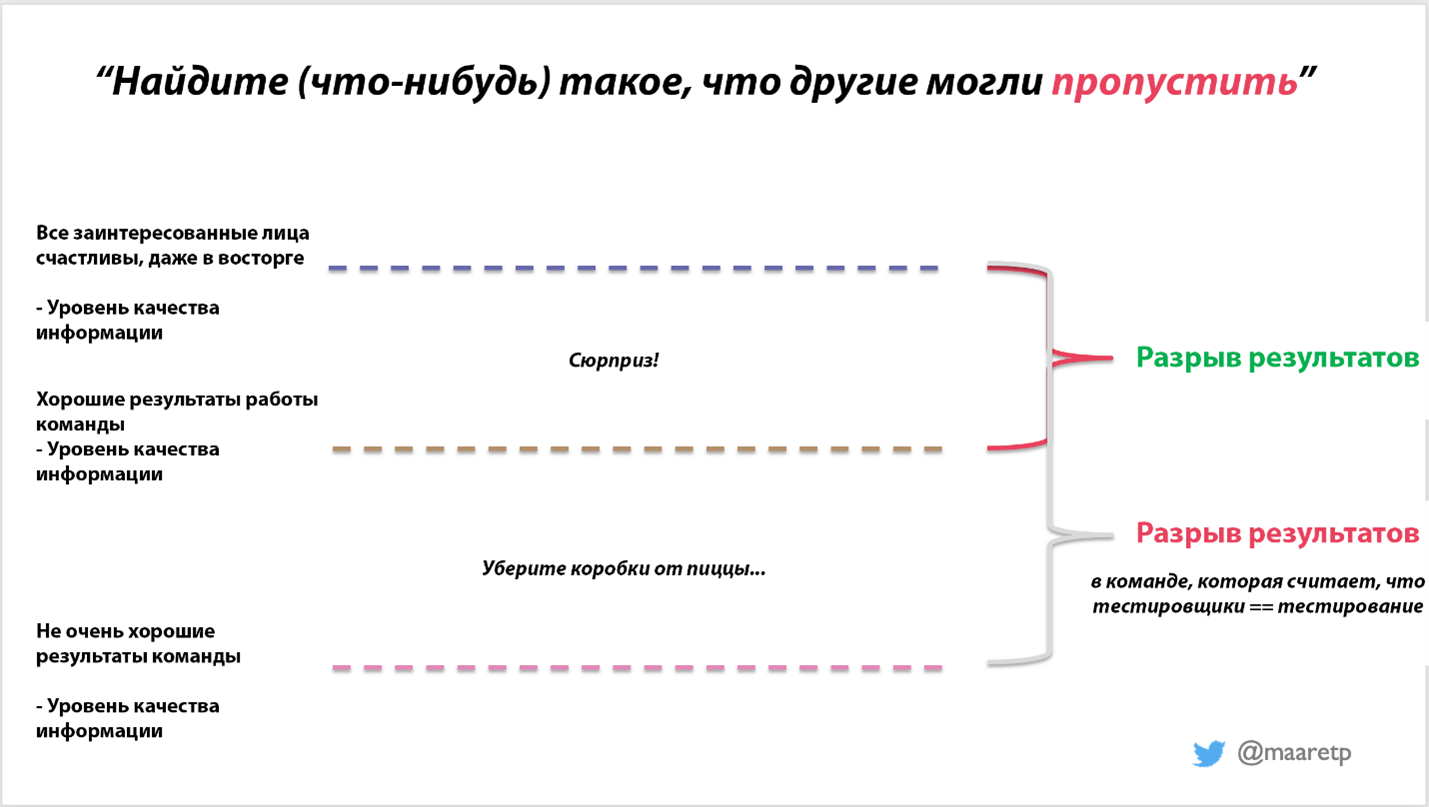
Сегодня я созванивалась с коллегой по профессии. Он отправил мне сообщение в LinkedIn, прося о разговоре про тест-покрытие – до этого мы не особенно-то переписывались. И, как я иногда делаю, я согласилась поговорить. Я благодарна, что этот созвон состоялся – как за осознание, что объясняю тест-покрытие через модель «1-2-3», так и за канал коммуникации, позволяющий мне приходить к пониманию, вне зависимости от того, кто где находится. Модель 1-2-3 предполагает, что тест-покрытие можно измерить одной истинной мерой. Так как это недостижимо, на старте мы обычно используем две. А так как две – это очень плохо, нужно помнить еще о трех, чтобы объяснять вопрос людям, не разбирающимся в измерениях тестирования. ОднаДля измерения покрытия действительно есть одна истинная мера – измерение рисков/результатов. Представьте себе список из всей релевантной и на данный момент истинной информации о продукте, которую нужно обсудить, зафиксированный на бумаге – вот это вам нужно покрыть. Проблема в том, что вы получили пустой лист. Хорошего способа создать список всех релевантных рисков и результатов не существует. Но это покрытие надо обсудить, и вот как это сделать. Если вы счастливчик и работаете в компании, где разработчики действительно тестируют и пекутся о качестве, уровень покрытия в этом смысле будет находиться где-то по центру картинки ниже. Это уровень качества информации, предоставленной Хорошей Командой. Чтобы определить, действительно ли у нас Хорошая Команда, нужно натравить на них кого-то Очень Компетентного в тестировании. Этот Очень Компетентный может быть тестировщиком, но с моей точки зрения, большинству тестировщиков в хороших командах нечем заняться – планка очень высокая. Очень Компетентная Личность может также быть комбинацией всех ваших пользователей – но тут придется мириться с задержками обратной связи и ее искажениями. Я называю разницу между результатами работы Хорошей Команды и качеством, при котором наши заинтересованные лица действительно счастливы, разрывом первичных результатов. Множество компаний не пытается ничего с этим сделать, оставляя эту задачу пользователям. Это возможно, так как природа проблем, найденных людьми при разрыве первичных результатов – это неожиданность. Я знаю, если работаю с такой командой – проблемы меня удивляют. Иногда я даже восклицаю «Это настолько интересный баг, что его просто невозможно было создать специально!». Если вы работаете с такой командой, и это сохраняется длительное время – вы счастливчик. В конце концов, местоположение на этой карте динамично по отношению к неизменно хорошей работе с любыми типами изменений.
Есть еще и вторичный разрыв результатов. Иногда уровень, достигнутый командами разработки – это уровень ниже, чем у Хорошей Команды. Зачастую это встречается в организациях, где менеджеры нанимают тестировщиков, чтобы те тестировали, даже если тестировщик находится в той же команде. Тестирование – это слишком важно, чтобы полностью перекладывать его на тестировщиков. Его нужно разделять между всеми членами команды. Иногда работа тестировщика в такой команде ощущается, как необходимость сообщить, что посреди гостиной валяются коробки от пиццы, и их нужно убрать. Лично я, обнаруживая вторичный разрыв результатов, считаю лучшим решением убрать тестировщика и реорганизовать обязанности, связанные с качеством, между оставшимися разработчиками. Задача тестировщика в такой команде – двигать ее к первичному разрыву результатов, а не разбираться с коробками от пиццы – разве что временно, в целях защиты репутации организации. Это длинное объяснение единственно верного измерения покрытия – рисков/результатов. Все остальное – следствия. Это помогает понять, с какой командой мы имеем дело – с первичным или вторичным разрывом результатов. Чем ниже мы начнем, тем меньше шанс, что мы когда-либо разберемся с разрывом полностью. ДвеДве меры покрытия, которые мы часто используем, и которые поэтому все должны понимать – это покрытие кода и покрытие требований/спецификации. Все это тест-покрытия, но их природа сильно разнится. Покрытие кода может только сообщить нам, что находится в коде, и затрагивали ли это тесты. Если у нас есть обещанная к внедрению функциональность, которую ожидают пользователи, но которую мы не сделали, покрытие кода этого не обнаружит. Покрытие кода фокусируется на том, что уже там есть. У Кема Кейнера есть старая статья про 101 критерий покрытия кода, поэтому нужно помнить, что это не что-то единичное. На код можно смотреть множеством способов, как и обсуждать его работу. Можно рассматривать каждую строку, каждое направление на каждом перекрестке, а также обращать внимание на сложные критерии для этих перекрестков. Инструменты способны только на очень простенькие способы оценки покрытия кода. Высокий процент не означает «хорошо протестировано». Он значит «хорошо затронуто». Смотрели ли мы на нужные вещи, и проверяли ли правильные детали – это уже другой вопрос. Повышение покрытия кода, как правило, не означает хорошего тестирования. Внимание к покрытию кода, стремление поддерживать его на том же уровне даже при добавлении новой функциональности, и выделение времени на вдумчивое тестирование на основании покрытия кода – вот то, что позволяет хорошим командам оставаться хорошими. Покрытие требований/спецификации связано с покрытием заявлений в официальных документах. Иногда требования нужно переписать как заявления, иногда мы разбираемся с каждым найденным нами заявлением, а иногда тщательно линкуем каждое требование к одному или нескольким тестам, но какая-то форма этого покрытия обычно существует. В случае с покрытием требований/спецификации нужно осознавать, что есть вещи, не попавшие в спецификацию, которые тоже нуждаются в тестировании. Нельзя верить, что какой бы то ни было материал будет исчерпывающим, тестирование – это, в частности, поиск упущений. Упущения могут быть обещанным в спецификации кодом или деталями, которые в спецификации не упомянуты, но которые считаются особенно проблематичными среди пользователей и заказчиков. Как правило, одного теста на одно заявление недостаточно. Нет никакого четкого лимита тестов, необходимых для каждого заявления. Я предпочитаю думать о них, как о «нет – один – достаточно». Достаточно – это про риски/результаты. И это меняется от проекта к проекту и требует понимания, что мы тестируем, чтобы тестировать хорошо. ТриК этому моменту вас уже раздражают Одна и Две, а есть еще Три. Эти три измерения покрытия мне приходится снова и снова пояснять, чтобы помочь обратить внимание на риски. Покрытие окружения начинается с идеи, что пользовательские окружения различаются, и тестирование только на одном может не покрывать все возможные варианты. О главных различиях между окружениями можно говорить часами, но в контексте покрытия просто поверьте мне – иногда они кардинально отличаются, а иногда нет. Если у нас есть десять функциональностей, которые надо покрыть тестами из расчета «один тест на одну функцию», и у нас три окружения – нам может понадобиться тридцать тестов. Простой пример – это браузеры. Firefox на Linux – это не то же самое, что Firefox на Mac и Firefox на Windows. Safari доступен только на Mac, а Edge – только на Windows. Chrome доступен на Mac, Windows, Linux. Только этот небольшой список дает нам восемь окружений. Объем тестирования, если мы хотим проводить его регулярно, легко может достичь поднебесных высот. С этим можно справиться при помощи различных стратегий – назначать разных людей на разные окружения, менять окружения поочередно, применять кросс-браузерную автоматизацию. Выбор зависит от рисков, а риски – от природы того, что мы создаем. Покрытие данных начинается с идеи, что каждая обрабатывающая данные функциональность покрывается одним типом данных, но этого может быть и недостаточно. Скажем, последние три года меня удивляют встроенные устройства – зачастую покрытие такой простой вещи, как положительная и отрицательная температура, необходимо для технологий манипулирования реестром. Покрывая данные, мы сильно опираемся на выборку, которая должна быть гибкой и подстраиваться под каждый тест требований, чтобы мы понимали, какого процента покрытия достигли. Она должна быть хотя бы достаточной, чтобы понимать, что проценты – в целом бессмысленная метрика покрытия. Парафункциональное покрытие – напоминание о других измерениях продукта, дающих позитивные результаты. Безопасность – это наличие функциональности, которая в плохих руках будет использована во вред. Производительность – учет скорости и эффективного использования ресурсов, особенно сейчас, в эпоху «зеленого» кода. Надежность – испытание одних и тех же функций длительное время. И так далее. Плюс однаСегодняшний созвон закончился обсуждением покрытия автоматизации. Обычно то, что мы перекладываем на автоматизацию – это подмножество всего, что мы делаем, то, что мы собираемся повторять. Отличная автоматизация не создается путем перечисления и внедрения тест-кейсов – для хорошей автоматизации нужна декомпозиция необходимой обратной связи другим образом, хотя в сумме результат будет похожим. Покрытие автоматизации – это соотношение того, что мы уже автоматизировали, к тому, что нас беспокоит. Некоторым необходимы документированные кейсы, но не мне. Если мне это и нужно, я говорю о покрытии автоматизации в ключе планов на ее развитие, и как могу избегаю таких разговоров. В одном из проектов мы покрывали его автотестами, присваивая значения «ноль, один, достаточно» к требованиям, проставив на автотестах метки, идентифицирующие требования. Для этого потребовалось много сил и хорошая коммуникация, включая планирование того, что нам еще понадобится, но процент был примерно равен тому, который я бы прикинула «с потолка». Возможно, у вас нет получаса, чтобы обсудить модель 1-2-3, созвонившись, как мы, но знание, как говорить о покрытии – неоценимый навык. Если вы занимаетесь тестированием, то у вас будет так же много шансов попрактиковаться в этом разговоре, как и у меня. |