Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Alien bugs или пришельцы из мира дефектов |
| 13.11.2014 12:22 |
|
Павел Новик, ЗАО «Технологии качества», бренд A1QA Ну что еще нового можно прочесть о дефектах, ошибках в программном обеспечении? Наверняка Вы думаете, что все уже сказано: как описывать дефекты, каков их стандартный жизненный цикл, ну и, конечно же, как их находить и исправлять. Однако, все не так просто, как может показаться на первый взгляд. I. Непроста и неказиста жизнь рядового Для начала давайте порассуждаем о нашей ежедневной работе и вспомним о тех проблемах, с которыми мы постоянно сталкиваемся. Во-первых, представьте, что дефект найден и успешно зарегистрирован в баг-трекерной системе. Вы столкнулись с данным дефектом, читаете его описание и… не понимаете, о чём все это. Вторая, не менее часто встречающаяся проблема, – плохо описанные дефекты, поступающие от пользователей либо заказчиков, а также бета-тестировщиков. Иногда сложно угадать, что именно пользователь имел ввиду под туманными описаниями типа «я нажал кнопку и приложение «упало», или «ваше приложение не устанавливается». Ну и последний по порядку, но не по значимости, ребус – Вы знаете, что дефект есть, но не можете его локализовать (воспроизвести по точным шагам). Что же делать со всеми приведёнными проблемами? Наверняка многие из Вас задумывались о возможном решении или предотвращении каждой из них. II. Правила существуют, для того чтобы их можно было нарушать! Для начала давайте зададимся вопросом, откуда берутся все эти дефекты с непонятным описанием? Почему каждый вносит дефекты по-своему? Причин несколько: самое банальное и очевидное – дефект внесён юным тестировщиком, который не знал всех нюансов, либо наоборот, слишком опытным, который не обращает должного внимания на нюансы. Дефекты также очень любят вносить «неискушенные» в деталях разработчики, ну и, конечно же, менеджеры проектов. Все случаи объединяет одно – дефект описан плохо. Сюда же, помимо плохого описания, можно отнести нарушение процесса работы с жизненным циклом дефекта (дефекты переводятся в некорректный статус или им выставляется неверная резолюция). Одним из лучших способов решения этих проблем является создание регламента по работе с дефектами. По факту, это детальный алгоритм описания и работы с дефектом. Он может быть представлен в любом удобном формате: обычный текстовый документ, таблица, блок-схема и т.д. Наиболее важные пункты, которые следует там прописывать:
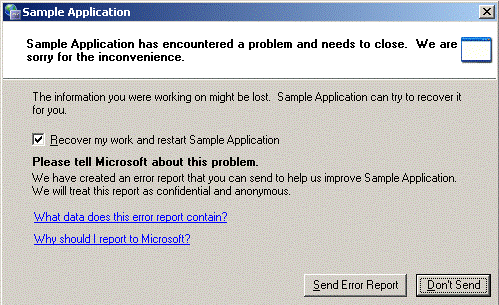
В качестве реального примера регламента, который можно использовать на проекте, можно ознакомиться вот с этим документом. Не бойтесь потратить на составление регламента лишний час, а то и более, пусть даже в нём будет слишком много ненужных, на первый взгляд, деталей, но в будущем это поможет сэкономить не только ваше время при работе с дефектами, но и не раз выручит в спорной ситуации, когда вы не будете знать, как быть с тем или иным непонятным дефектом. Итак, регламент составлен, всё в нём прописано, но как заставить команду ему следовать? Будет здорово, если на старте проекта Вы согласуете регламент со всеми участниками и договоритесь, что все дефекты, не соответствующие регламенту, будут автоматически переводиться в статус «для переформулировки». К сожалению, автоматизировать процесс сопоставления описания дефекта в соответствие с регламентом в данный момент не представляется возможным, поэтому чаще всего в качестве «единоличного судьи», определяющего дальнейший путь дефекта, выступает менеджер проекта. III. А что если дефекты будут регистрироваться в системе сами? Но всегда ли дефекты будут продолжать вноситься по регламенту, даже когда в команде все «подтвердили» регламент и следуют ему? Конечно же нет. Не стоит забывать о категории дефектов от конечных пользователей или заказчиков, а также от бета-тестировщиков. Само собой, научить пользователей или потребовать от заказчика вносить дефекты по регламенту, довольно сложная задача. И здесь есть несколько хитростей, которые помогут «облегчить жизнь». Самый простой – это предоставить пользователям возможность вносить дефекты исключительно по алгоритму, иначе говоря, минимизировать «полёт его фантазии» при заполнении полей. Например, создать форму, где для каждого поля при заполнении будет максимально возможное количество «предустановленных» параметров, которые могут относиться к проблеме. Другой очень действенный способ – создание автоматического баг-репортинга. Образно говоря, при помощи нажатия кнопки пользователь автоматически будет отправлять всю необходимую для воспроизведения дефекта информацию (например, параметры конфигурации, логи, скриншоты или даже видео с изображением последних действий пользователя). Одним из ярких примеров, такого автоматического баг-репортинга является отправка отчётов об ошибке в компанию Microsoft, особенно это было актуально для достаточно «сырых» версий Office или даже операционной системы Windows.
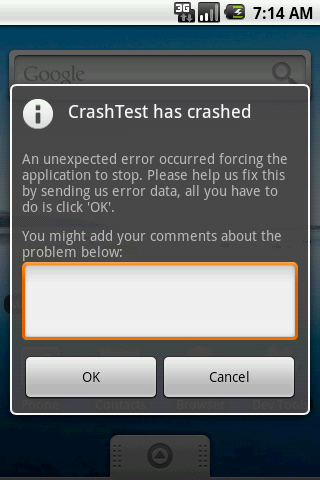
Довольно часто пользователю и не нужно нажимать какую либо кнопку, а достаточно выбрать определённую опцию в настройках приложения либо установить соответствующие параметры при его установке. Заядлые пользователи Android обязательно вспомнят, как после падения того или иного приложения оно просит пользователя отправить отчёт об ошибке.
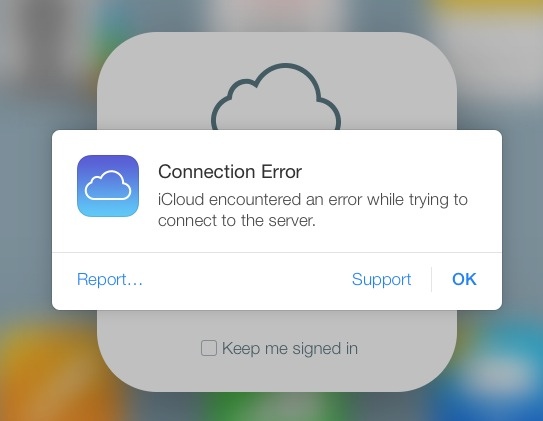
Да и не только пользователи Android, продолжая тему мобильных платформ, для операционной системы от компании Apple также предусмотрена возможность отправки отчёта об ошибке в случае возникновения проблем в работе какого либо приложения.
Кроме того, для тех же мобильных приложений существует неплохие платформы для тестирования, например такие как Ubertesters (о реальном опыте использования оной, можно почитать в данной статье), которая также позволяет автоматизировать и упростить процесс внесения дефектов. Следует помнить, что не всегда уместно размещать кнопку автоматического репортинга в релизном продукте, иначе первой мыслью пользователя может быть «я пользуюсь «забагованным» продуктом», ну и не стоит забывать про ограничения, связанные со сбором конфиденциальной информации о пользователе. Но если возможно обойти «эти острые углы» то автоматический баг-репортинг, весьма эффективное решение. IV. После релиза всё самое интересное только начинается! А теперь представьте, что вы успешно «зарелизили» свой продукт, и в нём нет дефектов! Довольно идеалистическая картина, так бывает не часто. Тем не менее, Вы успели всё проверить и со спокойной душой ушли отдыхать, а утром первый дефект от пользователей выглядит примерно так: «Приложение не устанавливается на iOS7». Как такое может быть? И что делать, когда вы знаете что дефект есть, а воспроизвести его не в состоянии? В подобных ситуациях, очень важно придерживаться определённого алгоритма действий: Для обработки таких дефектов, перво-наперво, нужнопопытаться найти уже существующий схожий дефект, который проявлялся ранее и был задокументирован. При этом не важно в каком состоянии сейчас находится дефект, главное что он есть, и скорее всего он поможет прояснить детали из-за чего мог возникнуть снова. Далее – попробовать воспроизвести дефект и понять в чём была его причина. Если поискать информацию о локализации дефектов на просторах глобальной сети, то чаще всего можно наткнуться на различные методики поиска дефектов в коде или непосредственно на примере определённой системы. Разумеется, локализовать точные шаги воспроизведения дефекта не всегда является тривиальной задачей, и когда тестировщик решает её, то следует определённой последовательности действий. Давайте попробуем разобраться, что же это за действия, и в каком порядке их лучше проводить. 1. Для начала нужно собрать всю информацию которая тем или иным образом может иметь отношение к дефекту. Не стоит при этом сразу отбрасывать на первый взгляд несущественную и малозначимую информацию. Ведь мы знаем, что тестирование программного обеспечения требует внимания к мелочам, ибо в подобных мелочах зачастую и кроется суть проблемы. При этом не стоит забывать и о рамках разумного и здравого рассуждения. Согласитесь, маловероятно что дефект зависит от температуры окружающей среды или результата футбольного матча любимой команды главного разработчика на проекте. 2. Когда вся необходимая на ваш взгляд информация собрана, попробуйте её категорировать по определённым признакам. Проще всего это сделать в виде таблицы, матрицы или блок схемы, с указанием критериев. Разложив всю информацию по полочкам, нужно выделить всё существенное и отбросить лишнее, то что не смогло попасть в какую либо категорию. 3. После выделения и каталогизации информации, сгенерируйте возможные гипотезы о том, по каким шагам воспроизводится дефект. Опять же, при составлении гипотез старайтесь не упускать из вида детали и мелочи. Начните с простых гипотез и двигаясь поочерёдно по «каждой полочке» с собранной ранее информацией переходите к более сложным идеям. Не забывайте и про то, что к одной гипотезе может относится информация из разных категорий. 4. Составив список гипотез, необходимо отсортировать их по степени вероятности. Сортировку можно проводить по разному, например задействовать простейший алгоритм, который используется в программировании. Так или иначе, для начала рекомендуется продумать по какой шкале будет «проставляться» вероятность. Самое очевидное - это процентное соотношение, но можно пользоваться удобным для вас способом. Главная задача – это получить на выходе итоговый список отсортированных гипотез. 5. Когда, казалось бы, самая сложная часть нашего алгоритма позади, наступает, пожалуй, самая трудоёмкая часть – проверка гипотез. Начиная с наиболее вероятных и двигаясь к менее вероятным, необходимо для каждой гипотезы провести два теста:
Оба данных теста могут служить подтверждением того, что вы находитесь на правильном либо ложном пути по локализации дефекта. В случае если вам не удаётся достоверно подтвердить либо опровергнуть гипотезу, возможно она составлена некорректно и требует уточнения и дополнения деталями. Это, в свою очередь, будет является своего рода указателем на то, в каком направлении вам необходимо двигаться. Обязательно фиксируйте результаты тестов для каждой гипотезы. Завершив проверки, внимательно проанализируйте полученную информацию, составьте ещё один список, рассортировав подтверждённые и опровергнутые теории. На данном этапе уже можно сделать заключение о шагах для воспроизведения дефекта. 6. Но что делать если все гипотезы проверены, а ответа на поставленный вопрос по прежнему нет? Слабый духом тестировщик скорее всего сдастся и прекратит попытки определить точные шаги воспроизведения, но более стойким я бы рекомендовал вернуться к шагу 3, а возможно даже и в самое начало пути, и попробовать отыскать новую, неиспользованную ранее информацию, на основании которой сгенерировать новые гипотезы. Отсортировав их по вероятности необходимо снова проверить на подтверждение и опровержение. Если же воспроизвести все же не получилось, обратитесь за помощью коллегам. Возможно, кто-то уже сталкивался с чем-то похожим, либо сможет предположить, в чём проблема. Если нет – «прямой дорогой» к разработчикам. Есть шанс, что они предложат решение. Если и это не помогает, следует обратиться к «автору» проблемы и вместе попробовать разобраться, где же кроется ее корень. Помните, что обращаясь за помощью, вы можете не только попросить выдвинуть теории о шагах воспроизведения дефекта, но и найти информацию, которая поможет снова вернуться к алгоритму действий и сформировать гипотезы, которых у вас раньше не было. V. Пользователь всегда прав, но … Когда мы говорим - обратиться к «автору» проблемы - чаще всего имеется ввиду реальный пользователь. При этом опираться можно на так называемое «правило трёх пинков». Суть его довольно проста: когда не получается воспроизвести дефект от пользователя, вы запрашиваете у него дополнительную информацию, то есть пингуете его. Если после трёх запросов пользователь ничего не отвечает и никак не реагирует на запросы, то дефект автоматически переводится в невоспроизводимый, т.к. можно считать, что на пользователя дефект больше не влияет, либо он также у него не воспроизводится. Важным нюансом во всём этом алгоритме является время, о котором очень важно помнить: когда пользователь присылает дефект, он ждет оперативной реакции. Разумным будет ввести несколько ограничений – во первых ограничить период на обработку дефекта в зависимости от его критичности для пользователя и время на каждую фазу (т.е. на поиск, воспроизведение и т.д.) Но если всё таки, несмотря на обилие приведенных в статье советов, теорий и гипотез, у вас по прежнему ничего не получается, то мой совет прост: Забыть обо всём и начать сначала! :-) Такая «перезагрузка» позволит отметить то, что ранее вы могли не замечать, понять в чём суть и причина дефекта. |