Что пишут в блогах
- Исследовательское тестирование и UX‑аудит для интернет-магазина
- Юзабилити‑тестирование без розовых очков: почему идеальный функционал не спасёт от провала?
- А ваши тестировщики защищают ваш продукт и компанию от миллионных штрафов?
- TechWriter Days 3. Как это было
- Ричард Румельт. Взлом стратегии.
- Должны ли разработчики тестировать свой код
- Мои 12 недель в году. Часть 33 (вышла книга по SQL, закончила книгу про ИИ)
- Почему SaaS падает при росте нагрузки?
- Как рассчитать реальный предел SaaS
- Эльба: ну вы там как-нибудь сами проверьте, где ошибка произошла

Что пишут в блогах (EN)
- Autonomous Testing has Landed: Welcome BearQ, by SmartBear
- The Autonomous Testing Tipping Point (Part 2)
- Dr. AI Yourself?
- The Autonomous Testing Tipping Point (Part 1)
- Test Automation Days Follow Up
- (Un)Ethical AI
- Rabbit, Meet Unemployment Line
- ATD 2026 – The Great Liberation: Software Testing in the Age of AI
- AI and Testing: Improving Retrieval Quality, Part 3
- AI and Testing: Improving Retrieval Quality, Part 2
Онлайн-тренинги
-
Автоматизация тестирования REST API на PythonНачало: 20 мая 2026
-
Школа тест-менеджеров v. 2.0Начало: 20 мая 2026
-
Тестирование мобильных приложений 2.0Начало: 20 мая 2026
-
Автоматизация тестирования REST API на JavaНачало: 20 мая 2026
-
Тестирование безопасностиНачало: 20 мая 2026
-
Python для начинающихНачало: 21 мая 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 21 мая 2026
-
Инженер по тестированию программного обеспеченияНачало: 21 мая 2026
-
Применение ChatGPT в тестированииНачало: 21 мая 2026
-
Азбука ИТНачало: 21 мая 2026
-
Создание и управление командой тестированияНачало: 21 мая 2026
-
Программирование на Python для тестировщиковНачало: 22 мая 2026
-
Тестирование REST APIНачало: 25 мая 2026
-
Школа Тест-АналитикаНачало: 27 мая 2026
-
Школа для начинающих тестировщиковНачало: 28 мая 2026
-
Тестирование производительности: JMeter 5Начало: 29 мая 2026
-
SQL: Инструменты тестировщикаНачало: 4 июня 2026
-
Docker: инструменты тестировщикаНачало: 4 июня 2026
-
Git: инструменты тестировщикаНачало: 4 июня 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 4 июня 2026
-
Bash: инструменты тестировщикаНачало: 4 июня 2026
-
Аудит и оптимизация процессов тестированияНачало: 5 июня 2026
-
Практикум по тест-дизайну 2.0Начало: 5 июня 2026
-
Логи как инструмент тестировщикаНачало: 8 июня 2026
-
Техники локализации плавающих дефектовНачало: 8 июня 2026
-
Charles Proxy как инструмент тестировщикаНачало: 11 июня 2026
-
Регулярные выражения в тестированииНачало: 11 июня 2026
-
Тестирование GraphQL APIНачало: 11 июня 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 11 июня 2026
-
Программирование на Java для тестировщиковНачало: 12 июня 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 16 июня 2026
-
Автоматизация функционального тестированияНачало: 19 июня 2026
-
Тестирование веб-приложений 2.0Начало: 26 июня 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 29 июня 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
| Метаморфическое тестирование: почему об этой перспективной методике почти никто не знает |
| 26.07.2019 00:00 |
|
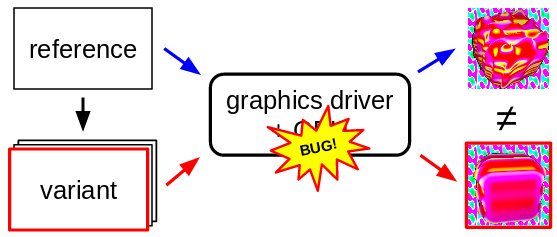
Оригинальная публикация Должен признаться: я читаю ACM Magazine. Это делает меня «ботаником» даже по меркам программистов. Среди прочего, я узнал из этого журнала о «метаморфическом тестировании». Раньше я никогда о нём не слышал, как и все люди, которых я спрашивал. Но научная литература по этой теме на удивление объёмна: есть множество невероятно успешных примеров её применения в совершенно разных областях исследований. Так почему же мы не слышали о нём раньше? Существует только одна статья для людей вне научных кругов. Пусть теперь их будет две. Краткая предысторияВ большинстве письменных тестов используются оракулы. То есть вы знаете ответ и явным образом проверяете, дают ли вычисления правильный ответ. Кроме тестов-оракулов, есть и ручные тесты. Тестер садится за компьютер и сравнивает вводимые данные с результатами. В процессе усложнения систем ручные тесты становятся всё менее полезными. Каждый из них проверяет только одну точку в гораздо большем пространстве состояний, а нам нужно нечто, исследующее всё пространство состояний. Преимущество PBT заключается в покрытии большего пространства. Его недостаток — утеря специфичности. Это уже не оракул-тест! Мы не знаем, каким должен быть ответ, и функция может быть ошибочна, но таким образом, что обладает тем же свойством. Здесь мы полагаемся на эвристики. МотивацияТеперь рассмотрим более сложную задачу. Представьте, что вы хотите написать преобразователь речи в текст (speech-to-text, STT) для английского языка. Он получает звуковой файл, а выводит текст. Как бы вы его тестировали? Метаморфическое тестированиеПри всём этом выходные данные рассматриваются по отдельности. Что если мы встроим их в более широкий контекст? Например, если звуковой клип транскрибируется в выходные данные
Примеры использованияК слову о примерах использования: насколько эффективно метаморфическое тестирование на практике? Одно дело рассуждать о методике абстрактно или приводить искусственные примеры. Изучение примеров использования полезно по трём причинам. Во-первых, оно показывает, работает ли способ на самом деле. Во-вторых, из них можно узнать о потенциальных сложностях при использовании МТ. В-третьих, примеры показывают нам, как мы можем использовать методику. Любую метафорическую связь, применяемую в примере использования, можно попытаться адаптировать под решение наших задач.
Проблема О, так ведь все эти источники в PDF. Дальнейшее изучениеИзобретатель МТ — Ти Чен (Ty Chen). Он же стал движущей силой множества исследований. Другие исследователи в этой области — Ци Цюань Чжоу (Zhi Quan Zhou) и Серхио Сегура (Sergio Segura); оба они выложили все свои препринты в Интернет. Большинство исследовательских работ выполнено кем-то из этих людей. Постскриптум: просьбаНа самом деле неудивительно, что я никогда не слышал раньше об этой методике. Существует множество действительно интересных и полезных техник, которые не смогли покинуть своего крошечного пузыря. Я узнал об МТ скорее благодаря везению, а не активным поискам. 1. Ну ладно, тут могут быть очевидные проблемы: в подкасте может быть музыка, фрагменты речи на других языках и т.д. Но теория надёжна: если мы способны получить сэмплы речи, то можем использовать их как часть тестов без предварительной ручной транскрипции/разметки. |