Что пишут в блогах
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| Автоматический перезапуск теста: хорошо или плохо? |
| 22.09.2021 00:00 |
|
Что происходит, если тест падает? Если тест запускается вручную, его поставят на паузу и будут копаться рядом, чтобы выяснить о проблеме больше. Однако при падении автотеста остальные тесты в наборе продолжают прогоняться. Тестировщики не узнают о результатах, пока прогон не завершится, и автоматизация не будет проводить дополнительное исследование после падения. Вместо этого тестировщики должны просмотреть логи и другие собранные в ходе тестирования артефакты, и упавший тест может понадобиться перепрогнать, чтобы убедиться, что проблема стабильно воспроизводится. Так как тестировщики, как правило, повторяют упавшие тесты в ходе исследования проблемы, то почему бы не сделать так, чтобы упавшие тесты повторяли прогон автоматически? С первого взгляда это кажется логичным: автоматический перезапуск устранит еще одно ручное действие. К сожалению, автоматический перезапуск может также повлечь за собой плохие практики – например, игнорирование реальных проблем. Так хорошо это или плохо – автоматический перезапуск? Это довольно противоречивая тема. Многие приговаривают его к расстрелу как антипаттерн (см. тут, тут и тут). Я согласен, что автоматический перезапуск можно использовать во вред, но тем не менее уверен, что он может принести автоматизации пользу. Более глубокое понимание вопроса требует знания нюансов. Как работает автоматический перезапуск? Чтобы избежать разночтений, четко определимся, что мы имеем в виду под "автоматическим перезапуском теста". Допустим, у меня есть набор из сотни автотестов. При прогоне этих тестов фреймворк индивидуально запускает каждый тест и выдает результат – пройден тест или упал. В конце набора фреймворк агрегирует все результаты в один отчет. В наилучшем случае все тесты пройдены: 100/100. Однако предположим, что один из тестов упал. При падении фреймворк поймает все ошибки, выполнит рутины по очистке, занесет падение в лог, и безопасно перейдет к следующему тесту. В конце набора тестов отчет покажет 99/100, с одним падением. По умолчанию большая часть фреймворков прогоняет каждый тест один раз. Некоторые фреймворки, однако, дают возможность автоматически перепрогнать упавшие тесты. Фреймворк может даже позволять задавать количество повторных попыток. Допустим, мы установили 2 повторных попытки для прогона нашего набора из сотни тестов. Когда наш тест упадет, фреймворк поставит его в очередь, чтобы прогнать еще дважды, прежде чем перейти к следующему тесту. Он также добавит информацию в отчет о тестировании. К примеру, если одна повторная попытка удалась, а вторая провалилась, то отчет покажет 99/100 прошедших тестов с коэффициентом прохождения 1/3 для упавшего теста. В этой статье мы сконцентрируемся на автоматических перезапусках для тест-кейсов. Тестировщики могут задавать и другие типы повторных попыток для автоматизации – повторные загрузки страниц в браузере, повторные REST-запросы. Повторные попытки на уровне взаимодействия требуют сложной, контекстно-зависимой логики, а логика повторных попыток на уровне тестов одинаково работает с любыми кейсами (повторные попытки на уровне взаимодействия требуют отдельной статьи). Автоматизированные перезапуски могут быть жутким антипаттерном Разберемся, как автоматизированный перезапуск может стать злом. Джереми – член команды, еженощно прогоняющей набор из 300 автотестов для веб-приложения. К сожалению, тесты ужасно нестабильны. Каждую ночь падает около дюжины разных тестов, и каждое утро Джереми тратит много времени на разбор падений. Если он перепрогоняет упавшие тесты по отдельности с ноутбука, они практически всегда срабатывают. Чтобы сэкономить время, Джереми добавляет автоматический перезапуск в тест-набор. При падении теста фреймворк автоматически пробует запустить его повторно. Джереми разбирается только с теми тестами, у которых провалилась повторная попытка. Если повторная попытка удалась, он полагает, что исходное падение произошло из-за нестабильности теста. Упс! Тут сразу несколько проблем. Во-первых, Джереми использует перезапуск, чтобы скрыть информацию, а не обнаружить информацию. Если тест упал, но повторная попытка прошла, тест все равно сигнализирует о проблеме! В этом случае первопричина – нестабильное поведение. Джереми использует перезапуски, чтобы переделать нестабильные падения в нестабильные срабатывания. Вместо этого он должен разобраться, почему тест нестабилен. Возможно, автоматизированные взаимодействия находятся в состоянии гонки и нуждаются в более тщательных ожиданиях. Или, возможно, функции веб-приложения ведут себя неожиданным образом. Падения тестов говорят о проблеме – или это проблема тест-кода, или кода продукта, или инфраструктуры. Во-вторых, Джереми использует автоматизированный перезапуск, чтобы увековечить плохие практики. Прежде чем добавить перезапуски в тест-набор, Джереми уже перезапускал тесты вручную и игнорировал нестабильные падения. Добавление перезапусков в тест-набор просто ускорило этот процесс, упростив игнорирование падений. В-третьих, способ применения автоматизированного перезапуска у Джереми говорит о том, что команда не очень-то ценит свои автотесты. Хорошая тест-автоматизация требует усилий и затрат. Постоянная нестабильность – знак пренебрежения, и провоцирует низкий уровень доверия к тестированию. Использование перезапуска – это просто наклеенный на падение тестов и отношение команды к автоматизации пластырь. В этом примере автоматизированный перезапуск – это, безусловно, ужасный антипаттерн. Он позволяет Джереми и его команде игнорировать реально существующие проблемы. По сути, перезапуск поощряет команду игнорировать падения, упрочая практику замены красных крестиков на зеленые галочки. Команда должна избавиться от перезапуска и заняться первопричинами нестабильности.
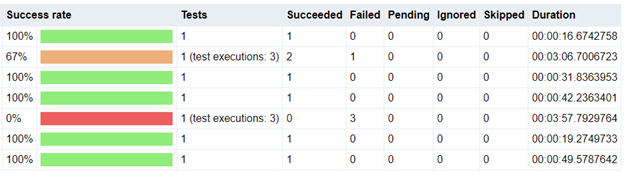
Тестировщики не должны скрывать падения, переписывая их как успехи. Автоматизированный перезапуск – это не основная проблема К сожалению, игнорирование нестабильных падений – чересчур распространенная проблема разработки. Должен признать, что когда я начинал, то тоже прогонял тесты повторно, чтобы заставить их сработать. Зачем люди это делают? Ответ прост: нестабильные падения тяжело исправить. Тестировщики обожают находить уверенные, воспроизводимые падения, потому что их легко объяснить. Разработчики не могут ничего противопоставить таким солидным доказательствам. Однако изоляция нестабильных падений занимает куда больше времени. Первопричины могут быть мозговыносящими головоломками. Их может спровоцировать фактор окружения или неподходящее время. Иногда у команд так и не выходит докопаться до первопричин. По моему опыту, баг-репорты нестабильных падений движутся куда меньше, чем баг-репорты стабильных падений. Все эти факторы поощряют людей закрывать глаза на нестабильные падения при любом удобном случае. Автоматизированные перезапуски – это просто инструмент и техника. Они могут повлечь за собой плохие практики, но сами по себе они не являются чем-то плохим. Основная проблема – в умышленном игнорировании определенных тест-результатов. Автоматизированный перезапуск может быть неимоверно полезным Итак, как же использовать автоматизированный перезапуск с умом? Используйте его, чтобы получить от теста больше информации. Тест-результаты – это просто артефакты обратной связи. Они демонстрируют, как продукт повел себя в определенных условиях и после определенного стимула. Бинарная природа утверждений упрощает тест-результаты на верхнем уровне отчета, чтобы привлечь внимание к падениям. Однако отчеты могут дать куда больше информации, нежели простое "пройдено или упало". Автоматизированные перезапуски дают серию результатов для упавшего теста, описывающих коэффициент успешности. К примеру, в SpecFlow и SpecFlow+ Runner легко использовать автоматизированный перезапуск правильным образом. Тестировщикам просто нужно добавить настройку retryFor в профиль SpecFlow+ Runner, чтобы задать количество повторных попыток. В финальном отчете SpecFlow фиксирует коэффициент успешности каждого теста при помощи цветных подсчетов. Результаты выявлены, а не скрыты. Вот скриншот отчета SpecFlow+ Report, демонстрирующий нестабильные падения (оранжевые) и стабильные падения (красные): Эта информация дает пищу для анализа. Как тестировщик, в первую очередь я спрошу себя, "Всопроизводимо ли падение?" Без автоматизированных перезапусков мне пришлось бы запускать тест вручную, чтобы найти ответ на этот вопрос – возможно, намного позже и в другом контексте. При наличии автоматического перезапуска этот шаг выполнен автоматически в том же самом контексте. Дальше анализ идет по одному из двух путей:
Я не игнорирую падения. Вместо этого я использую автоматизированный перезапуск для сбора информации о природе падений. В моменте эта информация помогает мне ускорить сортировку проблем. Со временем тенденции, вскрытые при помощи этой информации, помогают выявлять слабые места как в тестируемом продукте, так и в автоматизации. Автоматизированный перезапуск приносит наибольшую пользу в крупном масштабе Автоматизированный перезапуск может пригодиться тест-автоматизации любого масштаба, если он правильно применяется. Однако по большому счету они наиболее полезны для крупных проектов с масштабными тестами, а не для маленьких проектов. Почему? По двум причинам – из-за сложности и приоритетов. Крупномасштабные тест-проекты состоят из множества движущихся частей. К примеру, мы в PrecisionLender сейчас запускаем от 4 до десяти тысяч end-to-end-тестов нашего веб-приложения каждый день (мы также запускаем около 100 тысяч юнит-тестов ежедневно). Наши тесты запускаются из TeamCity в рамках нашей системы непрерывной интеграции, и используют домашние копии Selenium Grid для параллельного запуска 50-100 тестов. Само приложение PrecisionLender тоже огромно. Нестабильные падения неизбежны в крупномасштабных проектов, и тому есть ряд различных причин. Возможно, проблемы есть в коде тестов, но это не единственная возможная проблема. В PrecisionLender Boa Constrictor уже защищает нас от условий гонки, поэтому наши нестабильные падения редко вызваны проблемами кода автоматизации. Другие причины нестабильности – это
Многие из этих проблем вызваны инфраструктурой и процессами. Их нелегко исправить, особенно в общем окружении. Я не могу в одно лицо переписать весь CI-пайплайн компании, чтобы "улучшить" его. Я не могу изменить архитектуру всего процесса поставки приложения, чтобы избежать всех столкновений. Я не могу твердо гарантировать, что все мои облачные ресурсы или тест-инструменты вроде Selenium Grid будут работать 100% времени. Некоторые из этих моментов – хорошие инициативы для воплощения, но диктат одного тестировщика не становится реальностью по мановению руки. Во множестве случаев приходится работать с тем, что имеем. Односложные команды "просто исправить тесты" – это схоластика. Автоматизированные перезапуски тестов дают крайне полезную информацию для выявления природы этих нестабильных падений. К примеру, мы в PrecisionLender часто сталкиваемся с проблемами Selenium Grid. Примерно в 1/10000 случаев браузерная сессия Selenium Grid неожиданно зависает посреди теста. Мы не знаем, почему это происходит, и наши исследования ни к чему не привели. Мы списываем это на минорную нестабильность. Если это 1/10000 падение случается, наш тест-набор автоматически перезапускает тест, и тест срабатывает. Просматривая тест-отчет, мы видим нестабильное падение вместе с методом исключения. На основании его подписи мы сразу понимаем, что с тестом все в порядке. Нам не нужно тратить время на исследование или ручные перезапуски. Автоматизированный перезапуск дает нам всю необходимую информацию.
Selenium Grid – большой кластер с множеством потенциальных точек падения Еще один тип распространенного падения – это нестабильно низкая производительность приложения PrecisionLender. Иногда приложение зависает на пару минут, а затем восстанавливает работу. когда это происходит, мы видим "кирпичную стену" падений в отчете: все тесты за этот период упали. Затем срабатывает автоматический перезапуск, и после восстановления приложения тесты проходят. Автоматический перезапуск доказывает, что приложение в какой-то момент зависло, но с конкретными поведениями все в порядке. Это демонстрирует функциональную корректность поведений во время падения производительности приложения. Наша команда неоднократно использовала такие результаты для выявления багов производительности приложения, сверяя системные логи и запросы к базе данных во время этих нестабильных падений. Автоматизированный перезапуск вновь дал нам дополнительную информацию для выявления глубинных проблем. Автоматизированный перезапуск очерчивает приоритеты падений Это отвечает на вопрос о сложности, но что насчет приоритетов? К сожалению, в больших проектах всегда больше работы, чем команда может переварить. Ей приходится принимать непростые решения, что делать сейчас, что потом, и что не делать. Это бизнес. Тест-решения – часть этих приоритетов. Практически во всех случаях стабильные падения имеют приоритет выше нестабильных, потому что сильнее влияют на конечных пользователей. Если функция падает каждый раз при запуске, ей нельзя пользоваться, и пользователи не могут получить от нее пользу. Однако если функция то работает, то нет, то она может пригодиться пользователю. Более того, чем реже нестабильность, тем ниже эффект, и, следовательно, приоритет. Нестабильные падения все равно важны, но приоритезировать их надо по отношению к другим рабочим задачам. Автоматизированный перезапуск автоматизирует эту первичную приоритезацию. Когда я разбираю тесты PrecisionLender, то сначала смотрю на стабильные "красные" падения. Наши SpecFlow-отчеты делают их очевидными. Я знаю, что эти падения легко воспроизвести, объяснить, и, надеюсь, исправить. Затем я смотрю на нестабильные "оранжевые" падения. Они занимают больше времени. Я могу быстро выявить проблемы вроде обрыва связи Selenium Grid, но другие странности могут быть неочевидными (вроде системных прерываний) или требуют контекста (вроде падения производительности). Иногда нужно дать тестам покрутиться несколько дней, чтобы получить больше информации. Если в ходе разбора тестов меня призывают для выполнения более важной задачи, то я как минимум успеваю разобраться со стабильными падениями. Классическое правило 80/20: исследование стабильных падений, как правило, дает больше выхлопа при меньших затратах, а исследование нестабильных падений дает меньше выхлопа при больших затратах. Единственная ситуация, когда я ставлю нестабильное падение выше стабильного – это когда нестабильное падение вызывает катастрофический или необратимый урон – например, полностью стирает всю систему, повреждает данные, приводит к потере денег. Однако такой тип падений – большая редкость. По моему опыту практически все нестабильные падения вызваны или плохим тест-кодом, или таймаутами автоматизации из-за плохой производительности приложения, или глюками инфраструктуры. Контекст важен Автоматизированный перезапуск тестов может быть благом или проклятием, все зависит от того, как тестировщики им пользуются. Если тестировщики используют его, чтобы получить больше информации о падениях, то перезапуск – большое подспорье в анализе результатов. В прочих случаях, если тестировщики используют его для скрытия нестабильных падений, они отлынивают от собственной работы. Нельзя рубить с плеча, называя перезапуски антипаттерном. Без перезапусков мы бы не добились такого масштаба тестирования в PrecisionLender. Контекст важен. |