Что пишут в блогах
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026
- Как нагрузочное тестирование защищает бизнес от убытков?
- Исследовательское тестирование и UX‑аудит для интернет-магазина
- Юзабилити‑тестирование без розовых очков: почему идеальный функционал не спасёт от провала?
- А ваши тестировщики защищают ваш продукт и компанию от миллионных штрафов?
- TechWriter Days 3. Как это было

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация функционального тестированияНачало: 19 июня 2026
-
Школа тест-менеджеров v. 2.0Начало: 24 июня 2026
-
Python для начинающихНачало: 25 июня 2026
-
Азбука ИТНачало: 25 июня 2026
-
Школа для начинающих тестировщиковНачало: 25 июня 2026
-
Тестирование веб-приложений 2.0Начало: 26 июня 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 29 июня 2026
-
Тестирование REST APIНачало: 29 июня 2026
-
Школа Тест-АналитикаНачало: 1 июля 2026
-
Bash: инструменты тестировщикаНачало: 2 июля 2026
-
Docker: инструменты тестировщикаНачало: 2 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 2 июля 2026
-
SQL: Инструменты тестировщикаНачало: 2 июля 2026
-
Применение ChatGPT в тестированииНачало: 2 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 2 июля 2026
-
Git: инструменты тестировщикаНачало: 2 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 2 июля 2026
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Техники локализации плавающих дефектовНачало: 6 июля 2026
-
Логи как инструмент тестировщикаНачало: 6 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
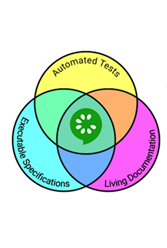
| Переходить на BDD или нет? |
| 11.09.2023 23:59 |
|
BDD как техника существует много лет, но ее до сих пор понимают неправильно. В статье я хочу обсудить и развенчать два таких заблуждения. Заблуждение №1: есть один-единственный правильный подход к BDD Нет, это не так. Я верю, что существует некий «традиционный» процесс BDD, и мы следуем ему в ходе курса, но это не значит, что вам везде и всюду нужно следовать этому процессу побуквенно. Ровно наоборот! Как и ряд других методологий, BDD применима различными способами, в зависимости от структуры вашей компании и команды, опыта работы с BDD, совокупным командным навыкам, и т. п. Мне нравится представлять BDD, как набор инструментов, из которого мы берем то, что нам, в нашем конкретном контексте, сейчас необходимо, и оставляем то, что не требуется. Попытка тщательно следовать традиционному процессу может для вас сработать, но с шансами будет ощущаться чем-то неестественным, навязанным, и «просто каким-то не таким». Это вполне понятно – все команды и контексты уникальны. Поэтому смело экспериментируйте с тем, что работает и что нет, не бойтесь отбрасывать нерабочее. Экспериментируйте, обучайтесь и подстраивайтесь, пока не найдете способ применения BDD, который подходит именно вам. Я снова и снова повторяю, однако, что первая стадия процесса (стадия обнаружения) – самая важная. Даже если вы решите полностью отказаться от BDD как процесса для ваших практик разработки, вам может пригодиться стимулирование обсуждений, необходимых для этой стадии, дабы:
Вы можете полностью отказаться от описания ожидаемого поведения в формате Gherkin «Если – Когда – Тогда», и не создавать автоматизированные приемочные тесты на этом основании, но техники стадии обнаружения пригодятся практически любой команде, вне зависимости от ее процессов специфицирования / очистки / дизайна. Заблуждение №2: BDD – это только автоматизация Последний момент подводит нас ко второму заблуждению о BDD, о котором я хочу поговорить – к идее, что в BDD все крутится вокруг автоматизации. Я сталкивался с множеством команд, утверждающих, что практикуют BDD, хотя на самом деле они просто наклеивают слой абстракции с «Если – Когда – Тогда» поверх своей автоматизации при помощи таких инструментов, как Cucumber и SpecFlow. Превращение примеров и спецификаций в автоматизированные приемочные тесты – это, конечно, важная часть BDD, но она далеко не единственная. Как я говорил ранее, BDD – это в первую и главную очередь техника, упрощающая коммуникацию и нацеленная на единодушное понимание, что именно должно делать наше ПО. Внедряя только автоматизационную часть BDD-процесса, вы пропускаете этот момент, и, следовательно, возможность для команды плыть на одной волне и снизить риски ошибочных интерпретаций, недопониманий и ложных предположений о поведении ПО. К тому же простое добавление слоя Gherkin к коду автотестов зачастую не несет почти никакого смысла, особенно если учитывать потраченные на его создания и поддержку усилия. В этом случае слой Gherkin, внедренный при помощи Cucumber или SpecFlow – просто еще одна абстракция поверх вашего кода. И как и в случае с любым уровнем абстракции, существует он, как правило, за счет гибкости (слой абстракции лишает вас ряда возможностей) в пользу простоты использования (слой абстракции делает код читабельнее и проще в написании). Я уже писал про слои абстракции, и хоть та статья больше концентрировалась на codeless-инструментах, Gherkin, примененный только в фазе автоматизации – просто еще один пример такого слоя абстракции, причем даже не наиболее полезный или мощный. Вообще я полагаю, что практически все «фреймворки тест-автоматизации», использующие Gherkin-инструменты вроде Cucumber и SpecFlow, не поддерживаемые важными для BDD обсуждениями, куда лучше справятся без этого слоя. Иными словами Gherkin – плохой (если честно – ужасный) вариант, если вы хотите применять его в качестве псевдо-языка программирования. Однако, возразите вы, я хочу, чтобы люди понимали, что делают мои приемочные тесты! Отвечу: возможно, этого можно добиться куда более подходящими способами. Вот мои рекомендации:
Вкратце: без основополагающих для BDD обсуждений не беритесь за приделывание Gherkin поверх всего и вся. |