Что пишут в блогах
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Школа для начинающих тестировщиковНачало: 9 июля 2026
-
Азбука ИТНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Python для начинающихНачало: 9 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| 50 оттенков нагрузочного тестирования |
| 23.05.2022 00:00 |
|
Автор: Коршунова Александра С нарастающими скоростями и распределёнными системами всё сложнее бывает создать приложение удобным для конечного пользователя. Программы обладают кучей фич. Но выполняют ли они то, что нужно юзерам? А скорость их выполнения достаточная? А производительность при выполнении не хромает? На эти вопросы помогает ответить нагрузочное тестирование (НТ). Меня зовут Саша, я работаю в команде тестирования Ozon Fintech и расскажу про разнообразный спектр вариантов НТ: как именно мы его применяем и какие инструменты используем. Статья будет полезна тем, кто уже что-то слышал про НТ и хочет добавить его в свой проект, но пока страшновато. Давайте разбираться!
Нефункциональное тестирование Основные характеристики качества ПО описаны в стандарте ISO 9126: это функциональность, юзабилити, поддерживаемость, эффективность, масштабируемость, надёжность. НТ относится к тестированию эффективности. Стандарт определяет эффективность как способность ПО обеспечивать достаточную производительность при наличии определённых ресурсов и под определённой нагрузкой. Мне нравится подход Рекса Блэка, американского тестировщика, автора книг и учебников по тестированию. В своё время он был президентом ISTQB и соавтором программ подготовки к этой сертификации. Согласно его учебнику “Advanced Software Testing — Vol. 3”, неэффективность может выражаться по-разному:
Под капотом неэффективности чаще всего прячутся непродуманные дизайн и архитектура, а в них сложно вносить изменения на поздних стадиях разработки. Поэтому лучше приступать к тестированию эффективности ещё на стадии дизайна и программирования — в этом вам поможет ревью и статический анализ. Блэк напоминает, что существует множество мифов о нагрузочном тестировании:
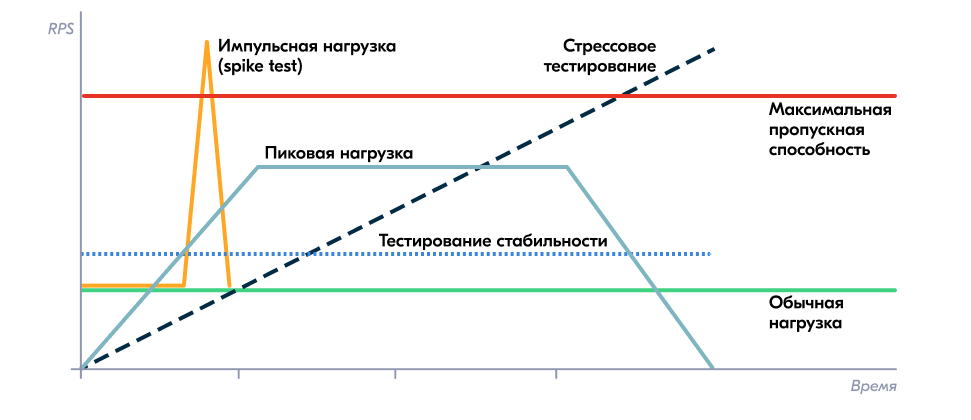
Виды нагрузочного тестированияТак что же это за зверь, это ваше нагрузочное тестирование?
Тестирование эффективности и называют НТ. Согласно терминологии ISTQB, НТ — вид тестирования производительности, проводимый с целью оценить поведение компонента или системы при различных нагрузках, обычно между ожидаемыми условиями низкой, типичной и пиковой нагрузки. Можно ещё сказать, что НТ — это тестирование с целью выяснить, выполняет ли система или компонент свои задачи в условиях ограничений за заданные временные интервалы и с определённой пропускной способностью. Вот некоторые виды тестирования эффективности, которые перечисляет Блэк:
О других типах НТ можно почитать в материалах для подготовки к сертификации (пункт 1.2).
Инструментарий
НТ существует уже не первый год, и за это время накопилось много разных инструментов для его проведения. Мы используем Яндекс.Танк — это удобный инструмент для тестирования бэка. Про него написано немало, не буду повторяться:
Мы в Ozon Fintech пишем на Go и работаем с gRPC, что надо учитывать при выборе пушек для Танка. Кроме того, наши пушки необходимо кастомизировать под свои нужды — выполнение сценариев, создание утилит для автогенерации пушки, автогенерация патронов — поэтому выбор пал именно на Pandora. Она сама написана на Go, обновляется и поддерживается. Создать кастомную пушку на ней довольно просто:
В структуре патрона важную роль играет поле Tag, в зависимости от которого поведение пушки меняется по switch case’у. Пример есть ниже в практической части статьи. Внутри выпавшего метода отправляем запрос по gRPC на ручку, получаем ответ, приводим код ответа на gRPC к HTTP-шному ответу, отдаём этот код агрегатору. Создаём патроны для нашей пушки: в Tag кладём название ручки, а в тело — остальные изменяемые поля запросов, которые нужны для работы. Создаём побольше таких патронов, заполняем конфиг для Pandora. А дальше локально или удалённо запускаем обстрел и смотрим на результаты. Сколько вешать в граммах?Как рассчитать профиль нагрузки? Сколько патронов необходимо создать для проведения тестирования? Для этого нужны требования, которых часто нет, а авторам задачи нужно, «чтобы оно работало». Для каждого случая необходимо выяснять свои требования. В качестве основного можно взять такое: перед каждым релизом удостовериться, что «новая версия работает не хуже предыдущей». Другое типовое требование — проверять, что «сервис выдержит нагрузку в случае планируемого расширения системы, например, в десять раз». Для третьей задачи может понадобиться, чтобы «время ответа конечному пользователю не превышало шести секунд». Остановимся на первом требовании. Как же понять, что «новая версия должна работать не хуже старой»? Для расчёта нагрузки идём в Grafana в описание работы интересующего нас сервиса на проде и смотрим, сколько раз была вызвана та или иная ручка. Например, текущая нагрузка на ручку = 15 RPS, а тест, который я провожу, должен длиться десять минут. Соответственно, количество уникальных патронов, которые необходимо предгенерить, равно 15 RPS * 60s * 10m = 9000 патронов. Что, если у меня нет возможности сделать каждый выстрел уникальным? Например, я в запросах обращаюсь к тестовым пользователям, а их в нужном количестве нет. Тогда патронов можно сделать меньше — и после первого прохода по файлу с ними Яндекс.Танк пойдёт на повтор. Получается, что вообще можно сгенерить по одному патрону на каждый тип запроса и успокоиться? Можно, но это будут нерепрезентативные запросы. Мы обычно рассчитываем минимальное количество запросов с учётом того, что нам необходимо, чтобы каждый запрос отправлялся на сервис не чаще, чем раз в пять секунд. Тогда с нашими условиями получится, что надо создать минимум 15 RPS * 5s = 75 патронов. Профилирование пушкиЧто делать, если у нас не только простая нагрузка «один запрос — один ответ», а целый сценарий? Например, в запрос нужно добавить свежий токен. Или для подтверждения запроса в одной ручке надо дёрнуть вторую ручку. Разберём такой тестовый сервис, обладающий методами MyRegistrationHandle, MyAccountHandle, UpdateBalance и ComplyBalance. На каждую ручку свой кейс:
UpdateBalance — кейс с последовательным выполнением запросов к одному и тому же сервису сначала на UpdateBalance, потом — на ComplyBalance.
Получается, что код shoot() в нашей пушке будет выглядеть так: Под капотом первого кейса всё просто: отправляем запрос к тестовому сервису, получаем ответ, убеждаемся, что ClientID вернулся не пустой. Во втором кейсе сначала нужно выполнить все манипуляции для получения токена, значение которого потом подкладывается в конечный запрос. В моём случае для этого надо совершить только одно действие — получить его из GetToken. Но сколько бы ни требовалось действий, нужно проверять каждый ответ и возвращать уникальный код ошибки, чтобы точно определять место отказа, если что-то пойдёт не так. В третьем случае мы последовательно отправляем запросы к одному и тому же сервису. Запросом к первой ручке создаётся запись в базе в статусе черновика, а вторым запросом эта запись подтверждается. Опять же, критично на каждом из шагов проверять коды ответа и приходящую информацию. Это важно, чтобы знать, на каком именно шаге что сломалось. Также необходимо все кастомные коды ошибок делать уникальными — чтобы было проще определять место поломки. Например, в третьем кейсе в обоих случаях проверяется сумма изменения баланса клиента, но при ошибке в работе ручки UpdateBalance вернётся errorCode4, а в ComplyBalance — errorCode5. Дополнительно можно добавить логи на ошибки. Банальные фразы типа резко повышают читаемость кода. Что сейчас и к чему стремимсяPandora активно используется для проверки эффективности сервисов внутри Ozon Fintech. Сейчас мы активно развиваем качество пушек и увеличиваем их количество. Сервисов много, для каждого нужны уникальные запросы, патроны, поведение, сценарии. Для чего-то требуется предварительная авторизация, для чего-то — нет. Поведение из некоторых UI-тестов копируется в бэкендовых нагрузочных тестах и позволяет проверять пропускную способность сервиса на пользовательских сценариях. Нехитрыми способами, описанными выше, можно покрыть существенную часть тестов. Сервисов много — сначала мы создавали пушки вручную, а теперь делаем это с помощью генератора. Параллельно наша команда работает над концепцией «Нагрузочное тестирование как сервис» — предоставлением полного цикла стрельбы от генерации и загрузки патронов на сервер и сборки пушки до проведения обстрела, сбора метрик и выведения результатов по нажатию на кнопочку в пайплайне CI. Надеюсь, моя статья помогла понять возможности НТ и убедила вас в том, что это полезный и необходимый инструмент для любого проекта. Stay tuned! |