Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
| Сравнение JMeter и k6 на практике |
| 26.01.2023 00:00 | ||||||||||||||||||||||||
|
Привет! Меня зовут Максим Колесников. Я работаю в центре компетенций нагрузочного тестирования блока обеспечения и контроля качества выпуска изменений в «РСХБ-Интех» — IT-компании АО «Россельхозбанк». У нас молодое подразделение, которое активно развивается, так что вместо инерционного похода «так исторически сложилось», команда задается вопросами «что делаем», «почему делаем» и «как можно сделать лучше» (и надо ли). Когда я в очередной раз прогонял себя по этому списку, возникла крамольная мысль: «А не выкинуть ли нам JMeter и переписать все на k6?». Вскоре уровень моей радикализации вернулся в норму, во многом под давлением аргументов, с которыми сложно спорить: «Нельзя внедрять технологии ради технологий», «Инструмент нужно выбирать под задачу, у всех есть свои плюсы и минусы», «А где будешь искать людей, владеющих инструментом, ты подумал?» и т. д. Но где-то в подсознании зародилась идея, от которой я мог избавиться только одним путем — написав эту статью. На этом закончим с лирической частью, всех заинтересовавшихся разбором инструментов прошу под кат. Решения, проверенные временем Наш текущий инструментарий достаточно распространен и отработан сотнями инженеров в течение многих человеко-лет: JMeter, единственный и неповторимый, для подачи нагрузки, Influx/Prometheus для мониторинга (сейчас мы в процессе выбора чего-то одного, но это тема для отдельной дискуссии), Jenkins для запуска тестов, ну и Grafana, GitLab, Confluence для прочих задач, которых мы здесь не будем касаться. ГипотезаИдея была такова — мы можем взять k6, переписать на нем наши скрипты и получить такие выгоды:
Почему k6 вообще может нам подойти? Если откинуть субъективные симпатии, то по следующим причинам:
О других плюсах решения можно больше узнать на сайте самого k6. Формулировка критериев и выбор операции для тестаИспользуя научный подход, переработаем тезисы, изложенные выше, в более четкие критерии сравнения двух инструментов (подробнее о каждом ниже по тексту):
Сравнивать будем на примере одной операции, реализованной с помощью обоих инструментов. Сама операция представляет собой:
Поскольку, как известно, дьявол кроется в деталях, акцентировать внимание буду на тех моментах, которые лично для меня оказались неожиданными при работе с k6 и которые не описаны в документации или в других статьях. Общие положенияНесмотря на разные классы лицензий, отличий (коммерческое использование, доработка, передача скриптов), которые повлияли бы на выбор в наших условиях, нет. Детальное сравнение лицензий Apache License 2.0 и GNU Affero General Public License v3.0 можно почитать тут или тут. JMeter — мощный инструмент, поддерживающий кучу протоколов и заточенный под работу в собственном GUI. K6 — инструмент заточенный под web и позволяющий придерживаться концепции everything as code. Есть cloud-версия, позволяющая избежать проблем с железом и мониторингом. Опять же, детально тут. Порог входа в JMeter существенно ниже, чем в k6. С одной стороны — заполнение полей в интерфейсе, а с другой — написание кода на JS. И найти инженеров, владеющих k6, пока что существенно сложнее. Настройки окруженияДумаю, большинство из вас знакомы с процессом установки JMeter, тем не менее, верхнеуровнево опишу, как он выглядит у нас:
С k6 сложнее, но без драматической разницы (если вам не нужны плагины, то вместо шагов 1-4 будет только установка бинаря k6):
Если у вас уже настроено проксирование пакетов go (как обычно бывает через Nexus для Java), то разницы нет. Да и пройти этот этап нужно всего раз. Настройки инструментаДалее пункт, который вызывает у меня повышенный интерес и может в определенных случаях склонить выбор на ту или иную чашу весов — возможности настройки инструмента. Если в JMeter практически невозможно найти сущность, для которой нет каких-либо параметров, то k6 не вызовет у вас астенической фрустрации от ассортимента настроек. Да, из всех параметров JMeter большинство из нас слышали хорошо если о десятой части (я сам узнал много нового в процессе подготовки статьи), а реально применяющиеся настройки можно пересчитать по пальцам одной руки. Но все-таки наличие выбора лучше, чем его отсутствие. Также сказывается зрелость инструмента: если у JMeter отличная документация и все параметры детально описаны, то настройки k6 приходится изучать не только по документации на сайте, но зачастую и по тикетам на GitHubе, а то и по исходникам там же. Дабы не быть голословным, приведу пару примеров. Из того, что сразу потребовало вмешательства — k6 безапелляционно пытается использовать HTTP/2. Круто, современно, но у нас клиенты подключаются по HTTP/1.1, так что и грузить нужно им. И вот незадача: в документации ни слова про принудительную версию протокола. Да, через пару минут поиска я нашел, как это побороть (если кому интересно, то нужно установить переменную среды GODEBUG=http2client=0), но осадочек и подозрение, что в следующий раз это может не обойтись малой кровью, остались. Из того, что не пригодилось, но взбрело в голову — настройка HTTP-клиента в JMeter httpclient4.time_to_live. Можете сказать, что притянуто, но все зависит от контекста — мне пару раз приходилось ее подкручивать. Плагины и расширенияПоддерживаемых из коробки протоколов в JMeter в разы больше, чем в k6, но на необходимость использования плагинов это практически не влияет. Самих же плагинов для JMeter ощутимо больше, писать новые или дорабатывать готовые проще в связи с более широким распространением Java среди инженеров по нагрузке. Также за счет зрелости инструмента в плагинах JMeter больше уверенности — еще пол года назад плагин k6 для отправки метрик в Prometheus, который заявляется как одна из фич в официальной документации, выдавал не особо правдоподобные метрики. Вместо этого приходилось применять связку с statsd_exporter. Судя по всему, эта связка еще актуальна — в ходе эксперимента обнаружил, что использование этого плагина вызывает утечку памяти и CPU. Происходит это, вероятно, из-за подсчета средних значений и перцентилей за все время теста. В моем случае утечка составляет всего несколько процентов за сутки и на это можно закрыть глаза, но для кого-то это может быть критичным. Помимо плагинов в JMeter можно использовать любые Java библиотеки. В k6 можно подключать библиотеки JS, но есть нюансы. Согласно документации не все модули будут работать с инструментом, я пробовал только JSLib, проблем не возникло. ФункционалПро функционал k6 уже много сказано и написано, все это в разных видах пересказ документации. Уберем посредников — пользуйтесь https://k6.io/docs/using-k6/. Так что не буду еще раз повторять, что весь функционал по параметризации, корреляции и проверкам, которым вы привыкли пользоваться в JMeter, есть и в k6. Лучше чуть подробнее остановлюсь на отличиях, которые, как мне кажется, важно знать:
Большинство недостатков каждого инструмента можно компенсировать либо выработкой определенного подхода к написанию скриптов, либо использованием дополнительного инструментария, все сводится к контексту применения. Про регулировку нагрузки. Если кратко — удобнее в JMeter, функциональнее в k6. Чуть подробнее: в JMeter наглядно видно какой будет подаваемая нагрузка, хотя при передаче параметров из командной строки тоже придется подключить воображение. В случае k6 придется потратить чуть больше времени, чтобы освоить и отладить регулировку нагрузки. Но в обоих случаях это разовая активность, которую легко скрыть под капотом автоматизации. Например, из всех режимов подачи нагрузки (executors) k6 я вряд ли буду использовать что-то кроме ramping-arrival-rate. И для упрощения запуска написал небольшую функцию, которая принимает параметры уровня нагрузки, количества ступеней и длительности (все как в Concurrency Thread Group) с последующим преобразованием их в параметры k6. Что действительно заметно — k6 умеет более точно регулировать подаваемую нагрузку. Разберем на примере:
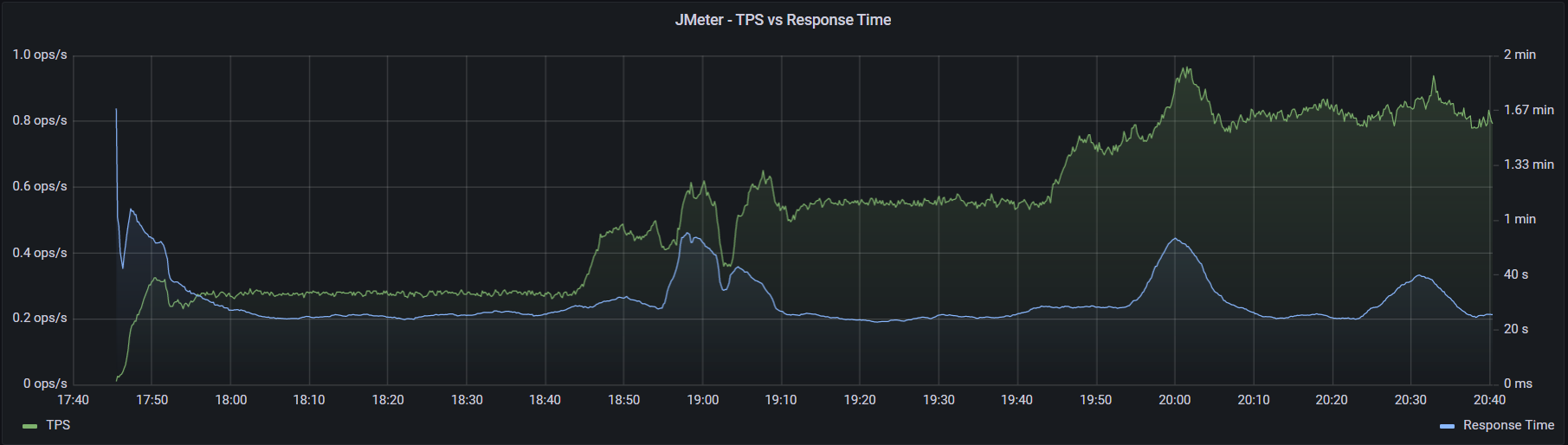
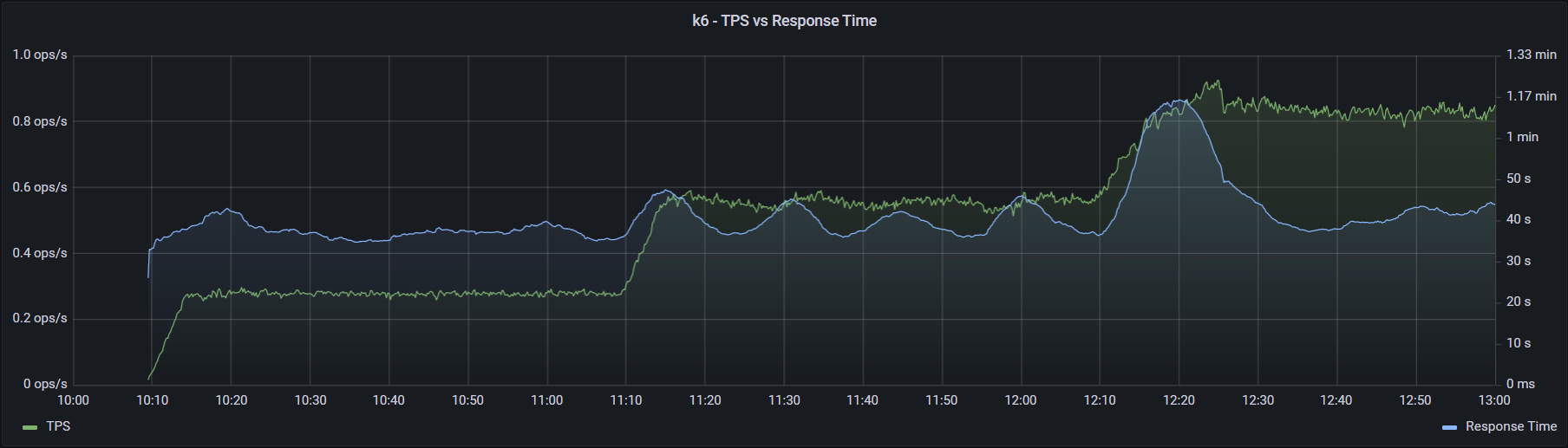
Возьмем этап разгона теста, в течение которого время отклика периодически возрастало. В случае JMeter каждая ступень это 50 потоков, пытающихся подать нагрузку в 1000 операций в час. У k6 preAllocatedVUs = 100 и maxVUs = 500, также по 1000 операций в час на ступень.
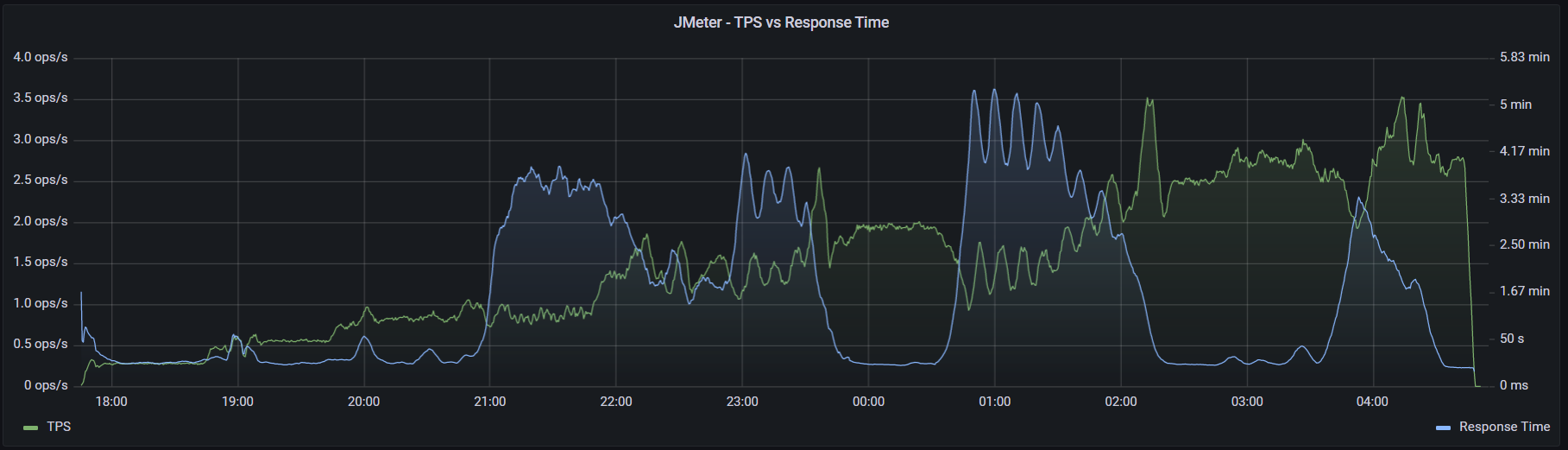
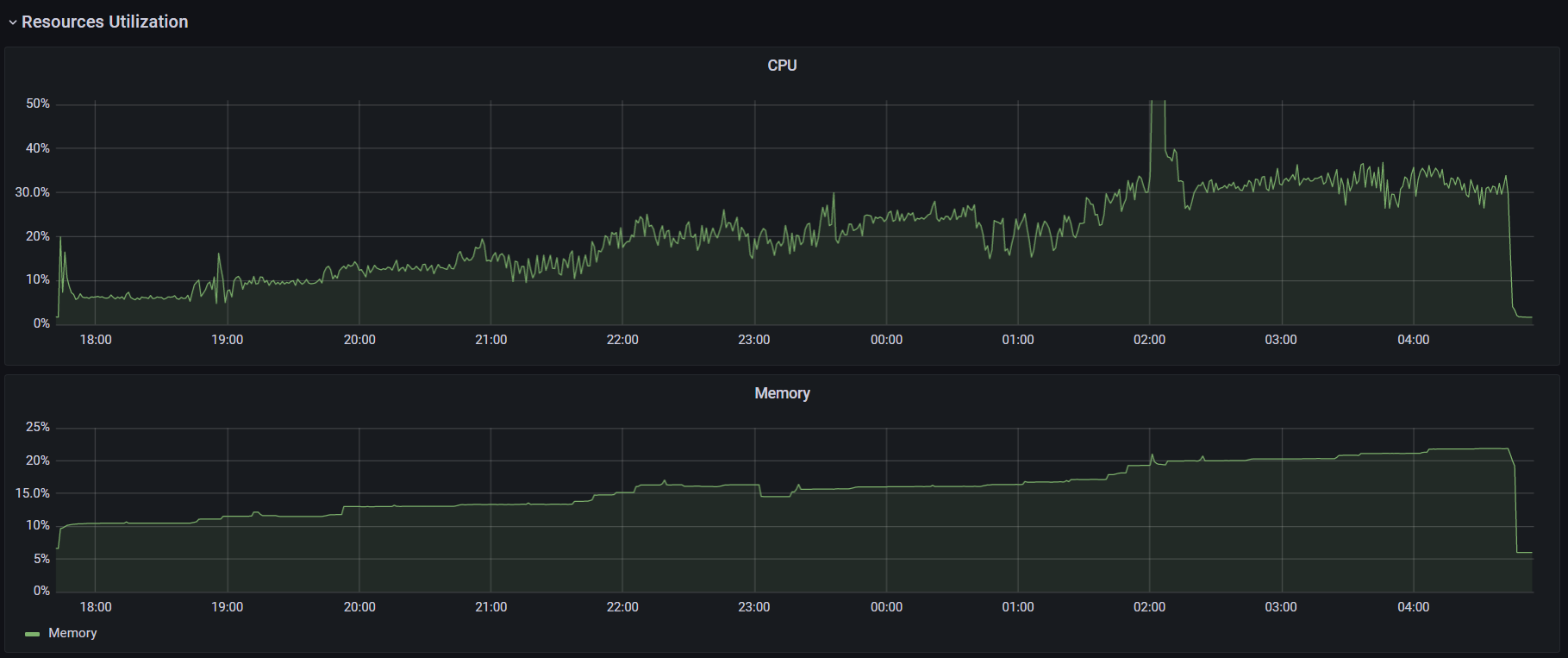
Как видно из графиков выше, k6 немного лучше поддерживает заданный уровень нагрузки, главное инициализировать достаточное количество потоков (параметр preAllocatedVUs). Потребление ресурсовДля сравнения потребления ресурсов каждым инструментом было проведено по два классических теста — максимум и надежность. Немного методики тестирования:
Тесты запускались на генераторе с 4 ядрами CPU и 32 Гб памяти. Версии, на которых экспериментировал:
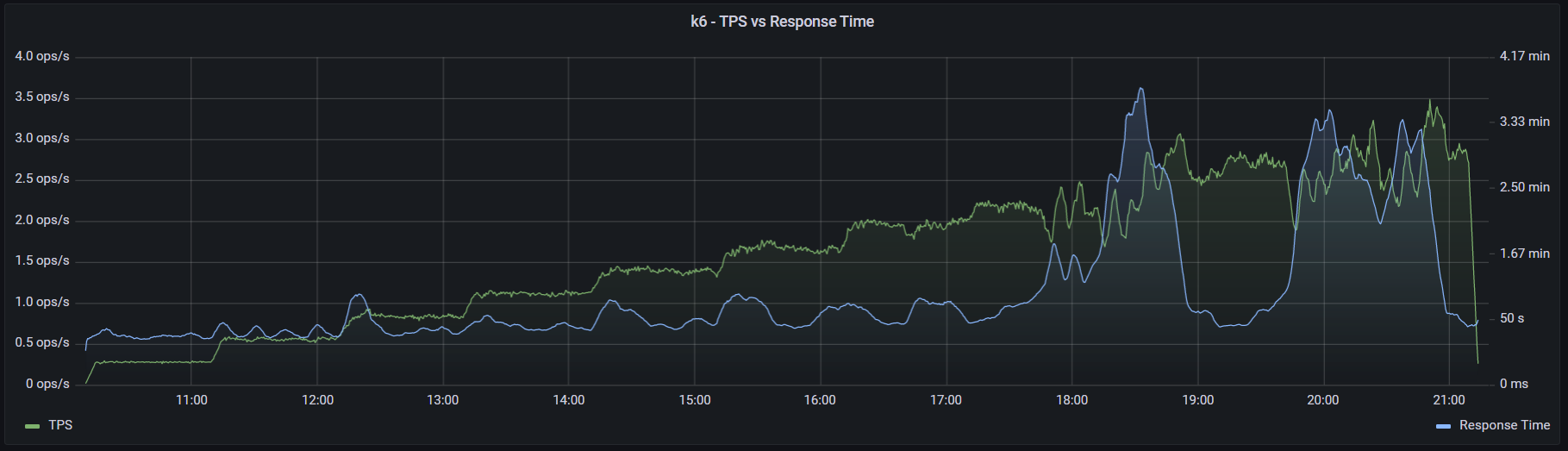
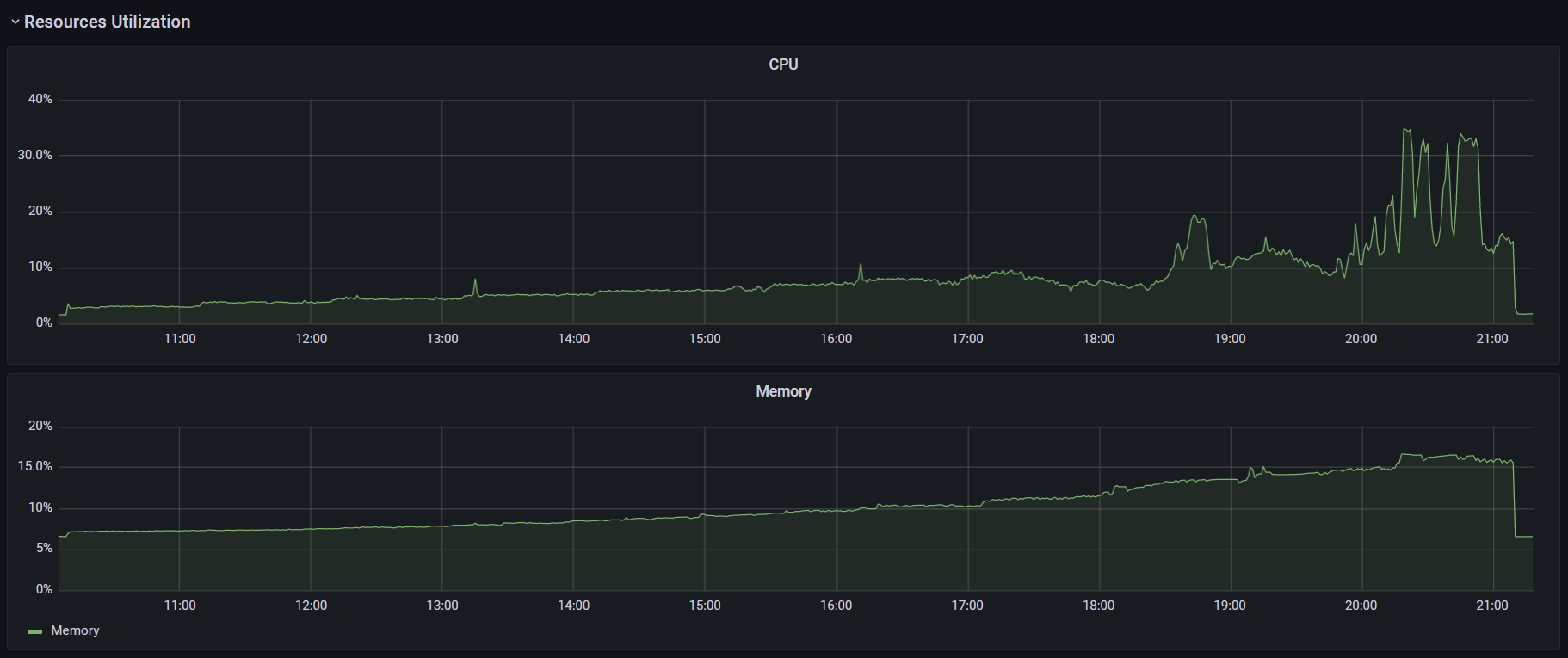
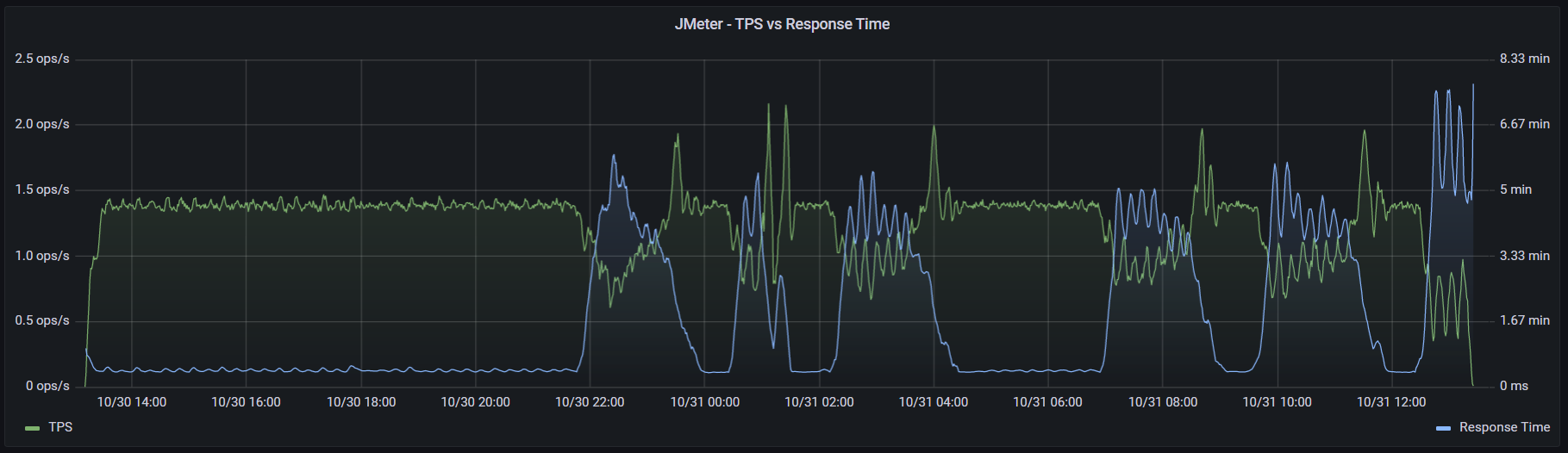
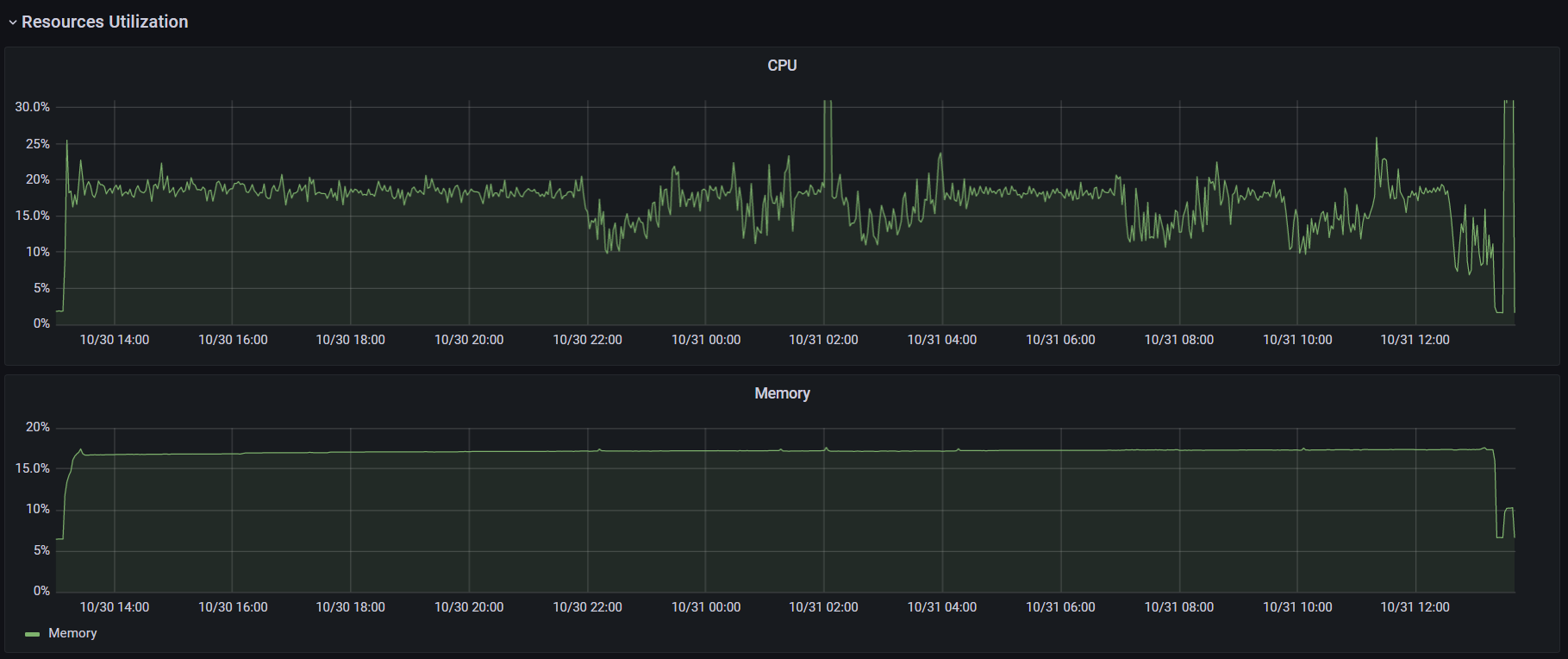
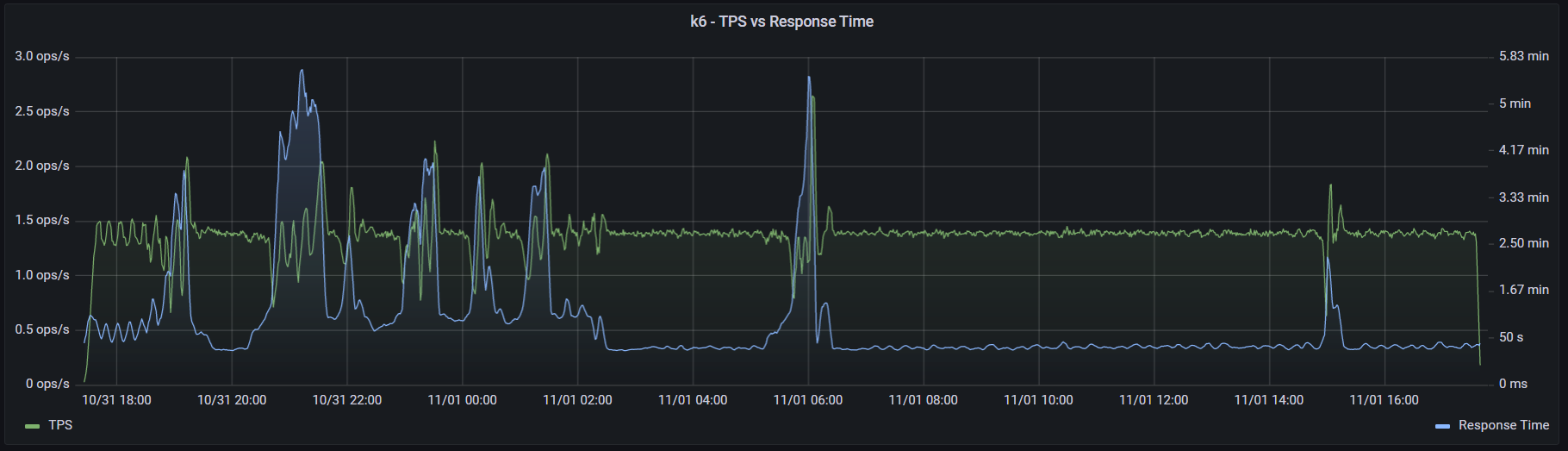
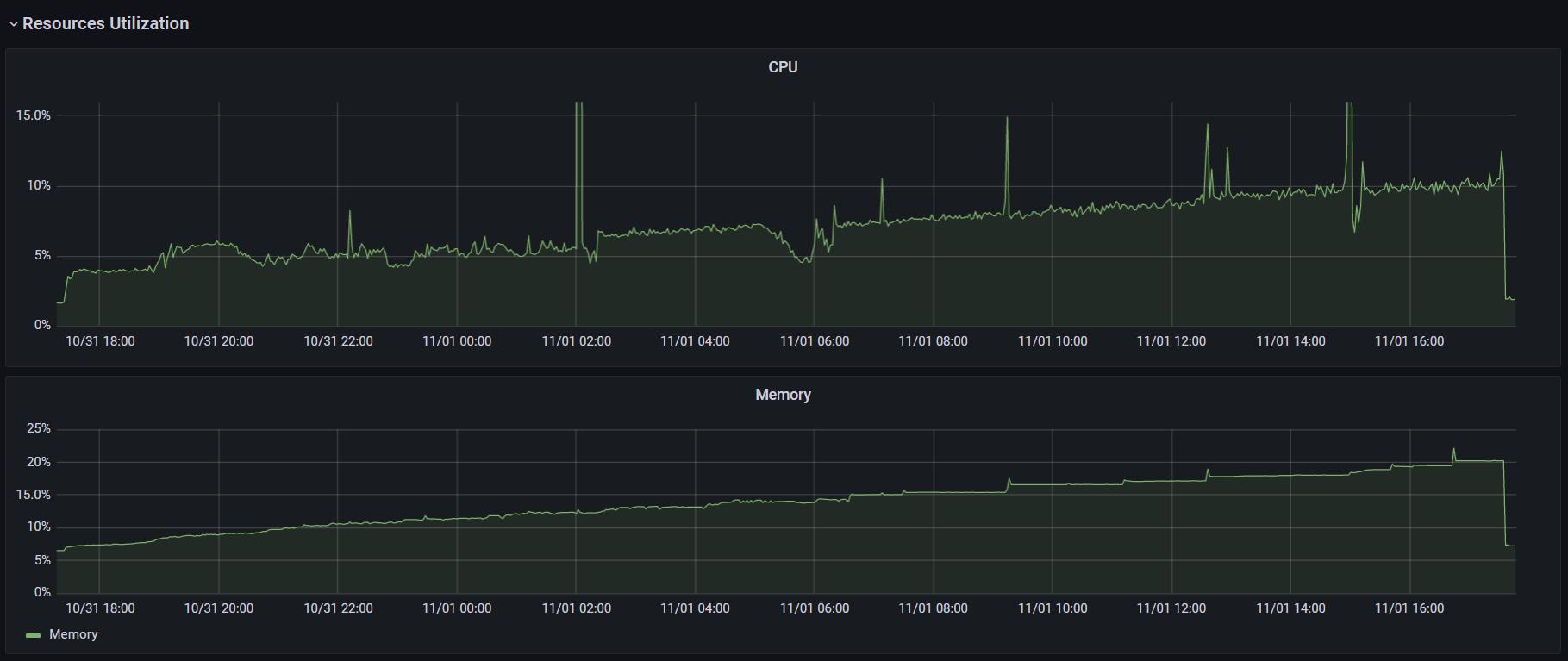
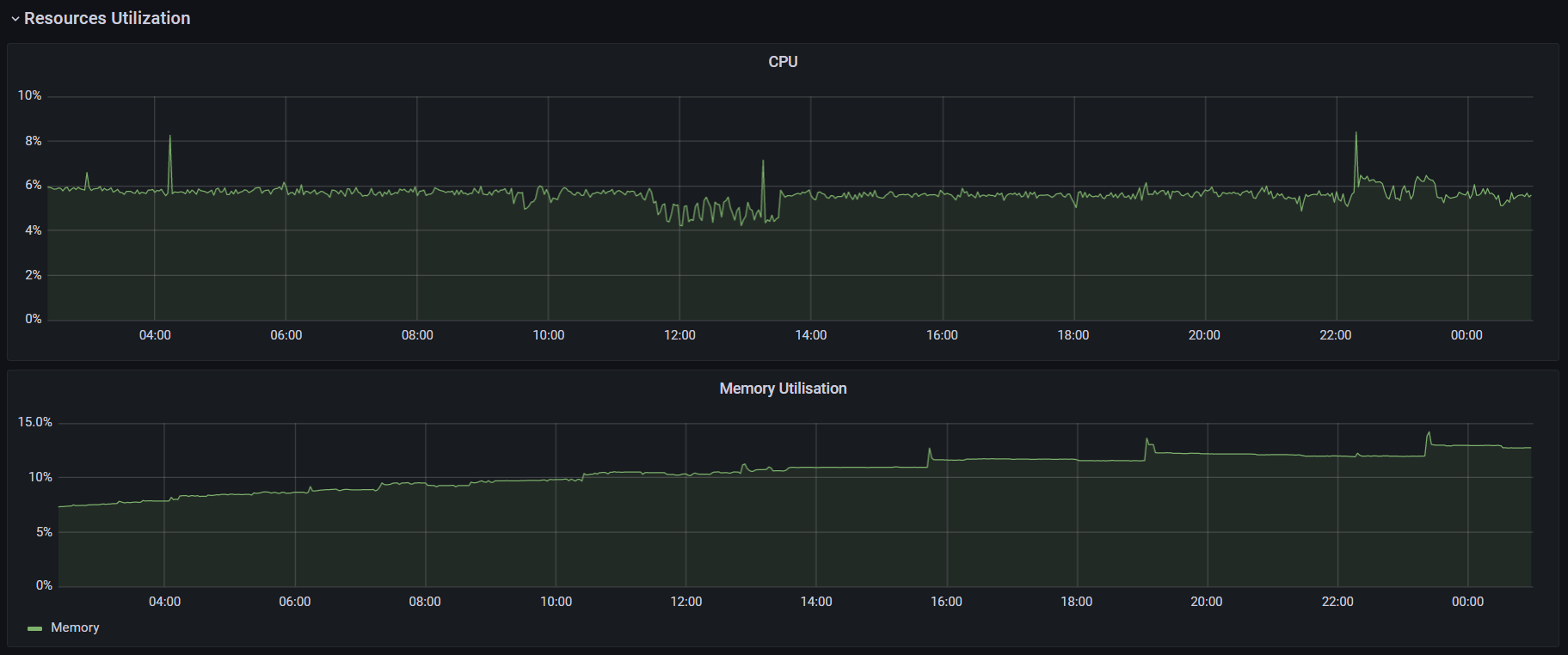
При запуске k6 использовался аргумент --no-summary. Также для улучшения производительности в документации k6 рекомендуют применять параметр --no-thresholds и --compatibility-mode=base. Но первый я не использовал, так как в данном тесте не устанавливал никаких пороговых значений. А при добавлении второго скрипт начал падать на инициализации. Я посчитал нецелесообразным искать очередной костыль и провел оптимизацию процесса настройки k6 в части затрачиваемого времени. К тому же информация о пользе этого параметра весьма противоречива: в документации говорят, что это «the most impactful option to improve k6 performance», а в официальном блоге «unless you have a memory problem it's not worth using this mode when running k6». (Спойлер: исходя из результатов тестов, я склоняюсь ко второму варианту). С другими оптимизациями можно ознакомиться в этой статье. Графики выполнения операций, времени отклика и утилизации ресурсов:
k6 - нагрузка и время отклика
В ходе теста надежности я заметил, что k6 с плагином мониторинга протекает, и запустил тест без него, чтобы избавиться от погрешностей. Утилизация CPU стабилизировалась, но память все еще медленно, но верно куда-то исчезает:
Информация с графиков, сведенная в таблицу:
Результаты тестов k6 у меня вызывают два вопроса: «Чем обусловлен резкий рост утилизации CPU на последней ступени поиска максимума» и «Что происходит с памятью в тесте без плагина мониторинга». Для анализа такого поведения интересно было бы написать плагин для k6, выводящий метрики самого go и позволяющий запустить pprof, но тонкое изучение внутренностей k6 выходит за рамки текущей статьи. АвтоматизацияВ плане автоматизации принципиальных различий нет. Оба инструмента предоставляют достаточный cli для автоматизации всех процессов через Jenkins. Один из первых вопросов, который у вас может возникнуть — а как же распределенный запуск? Да, в JMeter он есть, а в k6 как бы нет, но на практике JMeter мы управляем через Jenkins — просто запускаем несколько инстансов с нужными параметрами нагрузки. Поэтому никаких неудобств при попытке автоматизировать запуск k6 не возникло, скорее даже наоборот — тест показал, что весь наш профиль прекрасно умещается на один генератор и необходимости в распределенном запуске просто нет. Если же у вас все-таки возникнет необходимость запуска нескольких инстансов k6, то сделать это можно аналогично нашему примеру JMeter. Главное — настроить централизованный мониторинг и помнить, что трешхолды будут высчитываться независимо на каждом экземпляре k6 https://k6.io/docs/testing-guides/running-large-tests/#distributed-execution. Открытый финалПоскольку статья не писалась с целью сделать выбор за вас, то ответа какой инструмент использовать, тут не будет. Всегда нужно выбирать исходя из задач и контекста, а не слепо копировать чужой опыт и гнаться за трендами. Но надеюсь, что вы смогли чем-то вдохновиться и стать чуть более готовыми ко встрече с k6, если все же решитесь его попробовать. Однако небольшое резюме я все же выведу. Если ваша нагрузка сводится к web-протоколам, то технически оба инструмента смогут закрыть ваши потребности, и выбор будет зависеть от окружения — процесс НТ, квалификация инженеров и т.д. Если же требуются работа с MQ или БД, то каждый случай стоит рассматривать индивидуально. В JMeter есть плагины, они проверены, но часто приходится писать код. В k6 тоже есть плагины, но они не проверены. Наилучший выход — сравнить. По поводу потребления ресурсов — опять же зависит от того, насколько это для вас важно: если грузите сайт визитку, то с k6 много не выиграете, но в JMeter будет проще войти, а если необходима нагрузка в сотни тысяч RPS, то выигрыш в ресурсах от k6 может быть существенным. В любом случае попробовать k6 для собственного развития и поиска новых идей однозначно советую. |
||||||||||||||||||||||||