Что пишут в блогах
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Техники локализации плавающих дефектовНачало: 6 июля 2026
-
Логи как инструмент тестировщикаНачало: 6 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Python для начинающихНачало: 9 июля 2026
-
Азбука ИТНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Школа для начинающих тестировщиковНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| QA за пределами тестирования: надежность через учебные сбои |
| 18.09.2025 00:00 |
|
Привет! Я Леша Севальников, старший QA-инженер в команде, которая занимается разработкой бэкенд-сервисов для хранения, предоставления и актуализации данных о юридических лицах. Почти пять лет работаю в Т-Банке, где с нуля организовал тестирование в своей команде. За это время я успел пройти путь от ручного до автоматизированного тестирования, встроить и автоматизировать нагрузочное тестирование и многое другое. В какой-то момент все эти активности стали работать как единый механизм в текущих процессах, и мы задумались над следующим шагом для развития зрелости команды — повышение надежности. Расскажу о практике, которая поможет повысить надежность систем и команд. Что такое надежность и почему она важнаЧтобы понять, достаточно ли надежна наша система, можно ответить на вопросы:
Эти вопросы помогают понять, насколько команда готова к нештатным ситуациям. Но прежде чем углубляться в детали, давайте разберемся, что такое надежность. Надежность — способность системы работать корректно в условиях сбоев, высокой нагрузки или непредвиденных событий. Если говорить простым языком, надежность — это когда все вокруг горит, а сервис продолжает функционировать. Надежность команды — это способность команды эффективно и оперативно реагировать на инциденты и сбои, минимизируя их влияние на систему и пользователей. Важно понимать, что надежность и качество — это не одно и то же. Качество — это соответствие требованиям в идеальной среде, а надежность — это устойчивость к нештатным условиям, багам и высоким нагрузкам. Чтобы обеспечить и качество, и надежность, нужно подходить к разработке и тестированию систем комплексно. Надежность — это не просто характеристика системы, это залог успешной работы команды, удовлетворенности пользователей и устойчивости бизнеса. Ненадежная система — путь к хаосу, финансовым потерям и утрате доверия. Именно поэтому важно инвестировать в надежность.
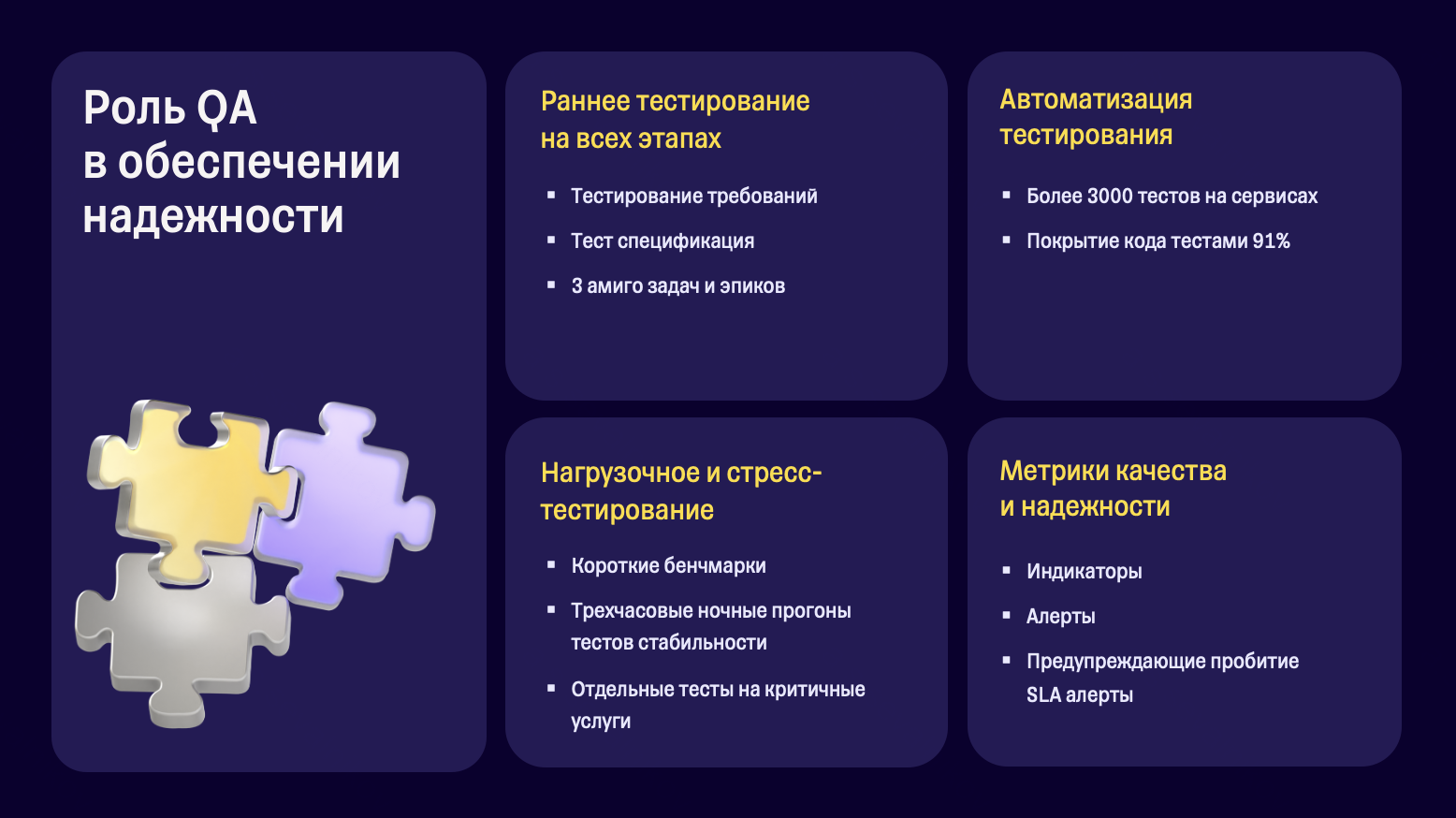
Как мы обеспечиваем надежность системы Для повышения надежности мы внедрили:
На первый взгляд кажется, что мы уже сделали все возможное. Но что происходит, когда сбой случается ночью, да еще и в выходной день? Тогда начинается самое интересное. Инциденты: неизбежность и стрессПредставьте ситуацию: ночью всей команде поступает звонок от системы инцидент-менеджмента. Для команды это первый подобный случай: часть сотрудников не проснулась, часть подумала, что это мошенники, и добавила номер в черный список. Из всей команды подвох ощутили только двое — QA и системный аналитик. Они выжидают, но наступает момент, когда пора что-то делать. Итог: сильный стресс, часовой инцидент и решение проблемы через отключение сервиса на ночь (не лучшая идея). Такие ситуации показывают, что инциденты — это неизбежность. Всегда будет человеческий фактор, невнимательность, баги на стороне других систем или инфраструктуры. Когда мы сталкиваемся с инцидентом, особенно неожиданным, то проходим через пять стадий принятия сбоя. Это не только психологический процесс, но и важный этап, который помогает осознать проблему и начать действовать:
Эти стадии — не просто шутка. Они показывают, как важно быть готовым к инцидентам и уметь быстро переходить к стадии «Принятие». Чтобы минимизировать последствия, мы ввели практику учебных сбоев. Они помогают сократить время прохождения первых четырех стадий и быстрее приступить к решению проблемы. Зачем нужны учебные сбоиУчебные сбои — это тренировки для команды и системы. Проведем аналогию: кто лучше всего справится с пожаром? Конечно, пожарные. А все потому, что они не ждут огня, а тренируются на полигонах. Так и ИТ-системы должны «гореть» на учениях, чтобы не сломаться в бою.
Практика учебных сбоев берет начало из Chaos Engineering. Это подход к тестированию систем, который предполагает создание контролируемых сбоев для проверки устойчивости системы. Основная идея заключается в том, чтобы намеренно создавать хаос в системе и наблюдать, как она справляется с ним. Это позволяет выявить слабые места и подготовиться к реальным инцидентам. Chaos Engineering основывается на четырех принципах:
Как мы проводим учебные сбоиОсновные шаги проведения учебного сбоя:
Для проведения учебных сбоев можно использовать инструменты:
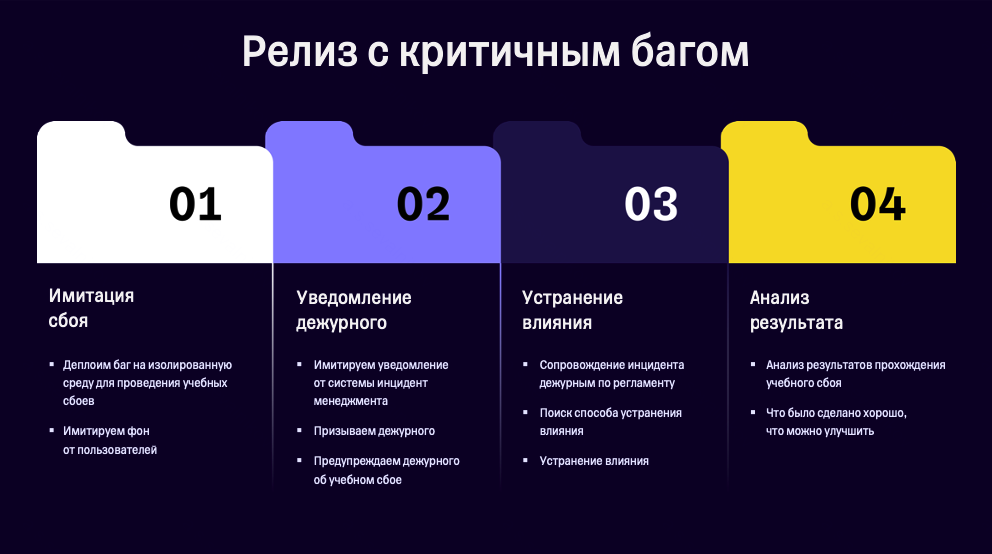
В моей команде в учебных сбоях участвуют все: разработчики, QA и системные аналитики. Обусловлено это тем, что во время дежурства на проде принимает участие вся ИТ-команда. Если команда на начальном уровне зрелости — подключаем только разработчиков. Когда команда становится достаточно зрелой, в учениях участвуют разработчики, QA и системные аналитики. Пример сценария — сценарий релиза сервиса с критичным багом. Гипотеза заключалась в том, что команда сможет оперативно обнаружить и откатить критичный баг в условиях, приближенных к реальным, следуя установленным регламентам и используя доступные инструменты. Мы предполагали, что текущие процессы и инструменты инцидент-менеджмента позволят минимизировать влияние сбоя на пользователей и быстро восстановить работоспособность системы. Имитация сбоя:
Уведомление дежурного:
Устранение влияния:
Анализ результатов:
Поведение команды и системы. Команда:
Система:
Результаты эксперимента. Что получилось хорошо:
Обнаруженные проблемы:
Выводы и рекомендации:
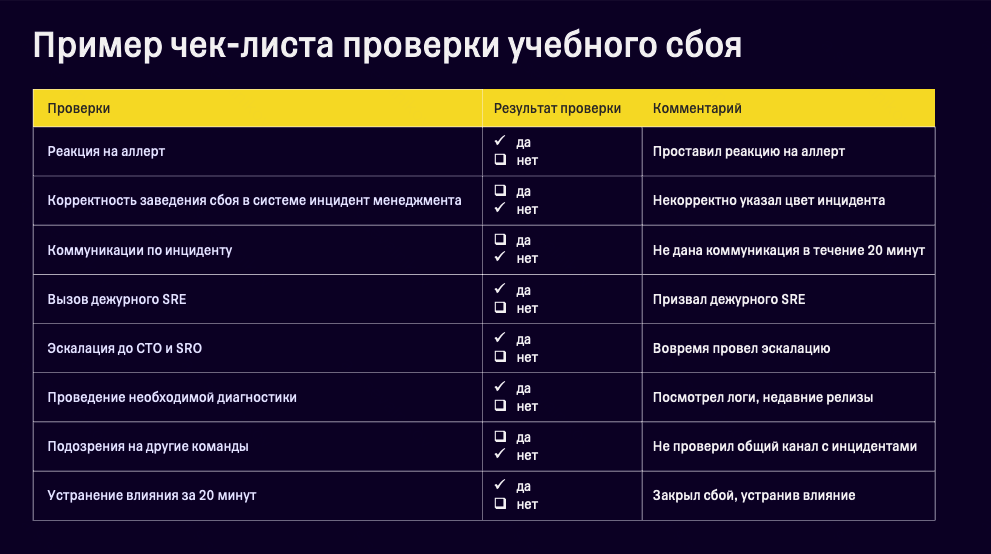
Как оценить эффективностьДля оценки готовности команды к инцидентам мы используем чек-лист, который помогает структурировать процесс и не упустить важные моменты. Вот основные пункты:
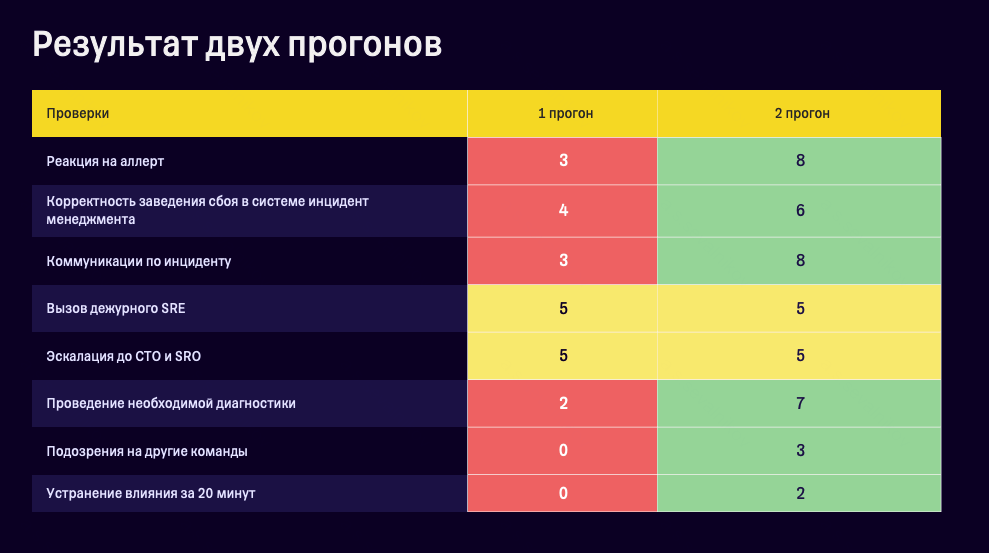
На первых двух учебных сбоях мы видели, как растут показатели команды. Например, из восьми человек успешно прошли проверку сначала трое, а затем все восемь. Это показывает положительную динамику и рост компетенций. Также видны первые победы в виде устранения влияния менее чем за 20 минут.
Частота проведения учебных сбоев играет ключевую роль в их эффективности. Мы проводим сбои еженедельно с участием дежурного инженера. Такой подход позволяет регулярно тренировать навыки реагирования на инциденты и поддерживать команду в состоянии готовности. Каждый дежурный проходит учебный сбой раз в квартал. Это обеспечивает равномерное распределение нагрузки между членами команды и дает возможность каждому сотруднику отработать действия в условиях, приближенных к реальным. Такой график позволяет поддерживать высокий уровень подготовки команды без излишнего отвлечения от основной работы. Что получилось улучшить:
Над чем еще предстоит работать:
ЗаключениеУчебные сбои, основанные на принципах Chaos Engineering, предоставляют множество преимуществ для повышения надежности системы и эффективности команды. Вот основные из них. Уменьшение ущерба от инцидентов. Регулярные тренировки команды на учебных сбоях позволяют сократить время реакции на реальные инциденты, что минимизирует их влияние на пользователей и бизнес. А еще это помогает снизить стресс и нагрузку на команду в критических ситуациях. Информирование бизнеса о потенциальных рисках. Учебные сбои предоставляют ценные данные о возможных рисках и уязвимостях, которые могут быть использованы для информирования бизнеса. Это позволяет принимать обоснованные решения по улучшению инфраструктуры и процессов. Улучшение взаимодействия внутри команды. Совместная работа над устранением учебных сбоев способствует улучшению коммуникации и координации внутри команды. Это повышает общую эффективность и уверенность в действиях сотрудников. Повышение уверенности в системе. Регулярные проверки системы на устойчивость к сбоям повышают доверие команды и бизнеса к ее надежности. Это позволяет более уверенно внедрять новые функции и изменения. Адаптация к изменениям. Учебные сбои помогают команде адаптироваться к изменениям в системе и инфраструктуре, обеспечивая готовность к новым вызовам и условиям. Развитие культуры непрерывного улучшения. Регулярные учебные сбои способствуют развитию культуры непрерывного улучшения, где команда постоянно ищет способы сделать систему более надежной и устойчивой. Учебные сбои — это не просто инструмент для проверки системы, это стратегический подход к повышению ее надежности и устойчивости. Они помогают не только выявлять и устранять слабые места, но и развивать команду, улучшать процессы и информировать бизнес о потенциальных рисках. Внедрение учебных сбоев позволяет создать более надежную и устойчивую систему, готовую к любым вызовам, и обеспечивает уверенность в том, что команда сможет эффективно справляться с любыми инцидентами. |