Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Тестируйте не числом, а умением |
| 21.07.2010 23:47 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Автор: Scott Sehlhorst Эта статья о комбинаторных методах построения тестов первоначально была написана для developer.* в марте 2006 года. Недавняя статья на Dailytech обращает внимание на одно очень интересное исследование о новых методах генерации многомерных комбинаций (четверок и более), выполненное Лабораторией информационных технологий Национального института стандартов и технологий США (NIST, the National Institute of Standards and Technology). Данная переработанная и дополненная версия статьи учитывает эти результаты. ВведениеВ первой части исследуется проблема обеспечения хорошего покрытия тестами входных данных сложного программного обеспечения. Во второй части обсуждаются подходы к решению этой проблемы (включая выявленные в исследовании NIST). В третьей части анализируются подходы к улучшению «лучшего» решения, описанного во второй части. Мы поговорим о способах снижения цены, которую приходится платить за обеспечение высокого качества тестирования. Более конкретно, мы обсудим техники, удешевляющие создание и поддержку набора регрессионных тестов. Мы начнем с обсуждения проблемы, а затем обсудим подходы к построению тестов, дающие все большую эффективность по более низкой цене. Надеемся, что вам понравится статья и будем рады услышать от вас отзывы и дополнения. Часть 1ПроблемыВот краткое описание проблемной ситуации, с которой мы будем иметь дело:
Aut Caesar aut nililМы должны рассмотреть два крайних решения: ничего не тестировать или тестировать абсолютно все. Все остальные решения будут где-то между этими двумя полюсами. Да, иногда бывают случаи, когда лучше вообще ничего не тестировать. К противоположному полюсу склоняются люди, которые недостаточно хорошо осознают сложность тестирования вообще, и особенно сложность и ограничения автоматизированного тестирования. Слово «автоматизация» вызывает у них желание протестировать все подряд. Однако это легче сказать, чем сделать. Мы не можем позволить себе тестировать этоНесколько лет назад я смог посетить тренинг Кента Бека (Kent Beck). Вечером после занятий я имел удовольствие поужинать и выпить с ним пива. Когда я спросил его, как он отвечает людям, жалующимся на высокую цену хорошего качества, Кент дал очень простой ответ: «если тестировать стоит дороже, чем НЕ тестировать, то НЕ тестируйте». И я согласен с ним. Существует несколько ситуаций, когда стоимость высокого качества превышает стоимость плохого качества. Бывает так, что требуемая инфраструктура, время разработки тестов, стоимость поддержки тестов превышают ожидаемую стоимость возможных ошибок. Ожидаемая стоимость – это вероятность возникновения ошибки, умноженная на стоимость этой ошибки. Методы, описанные в данной статье, предназначены как раз для снижения стоимости тестирования, и их использование снизит вероятность того, что придется следовать совету, который дал Кент Бек. Просто тестируйте все подряд – ведь это автоматизированоВсе мы бывали хоть раз в проекте, менеджер которого говорил: «Я требую полного покрытия программы тестами. Наша политика – ноль ошибок. В моем проекте не будет плохого качества». В этом случае приходится бороться с непониманием того, что означает иметь полное покрытие или другую гарантию определенной частоты возникновения ошибок. В достаточно сложной системе абсолютные значения недостижимы – и это нормально. Есть статистика, уровни доверия, планы управления рисками. Наш ум инженеров и программистов привык обращаться с ожидаемым, вероятным и возможным будущим. И мы должны помочь нашим менее подкованным технически собратьям понять эти вещи – если не сейчас, то хотя бы в перспективе. Нас могут спросить: «Почему вы не можете просто протестировать каждую комбинацию входных параметров, чтобы убедиться, что на них на всех программа выдает корректные результаты? У вас есть набор автоматических тестов – просто заполните и запустите его!». И нам приходится сдерживаться, чтобы не ответить: «Раньше обезьяны напечатают всего Шекспира, прежде чем этот запуск завершится!». Сложность – причина тщетности усилийРассмотрим веб-страницу, позволяющую уточнить параметры покупаемого ноутбука. Если вы никогда не выбирали ноутбук в онлайне, то взгляните, к примеру, на страничку Dell для ноутбуков начального уровня – выберите какой-нибудь ноутбук, и на страничке с описанием его характеристик нажмите кнопку «Personalize». На странице пользователю даны одиннадцать вопросов, каждый из которых имееет от двух до семи вариантов ответов. Точнее говоря, у нас есть (2,2,2,2,2,3,2,2,3,4,7) вариантов, которые может выбрать пользователь. Число вариантов, которые может выбрать пользователь, это произведение этих чисел. В нашем случае имеется 32 256 вариантов. Страница для конфигурирования профессиональных ноутбуков Dell на момент написания этой статьи имела похожий набор элементов с большим количеством вариантов - (3,3,3,2,4,2,4,2,2,3,7,4,4). Посетитель этой страницы может сформировать 2 322 432 различные конфигурации ноутбука! Если бы Dell добавил еще один управляющий элемент с пятью вариантами выбора, то мы бы имели более десяти миллионов возможных комбинаций! Разумеется, набор тестов, перебирающий все два миллиона комбинаций для профессионального ноутбука, можно автоматизировать, но даже если бы каждый тест занимал одну секунду, весь набор работал бы более 640 часов! Это почти целый месяц. Dell чаще изменяет свой набор продуктов. Если бы мы использовали группу серверов, распределив набор тестов между десятью машинами, мы смогли бы провести тестирование за 64 часа. Игнорируя тот факт, что такой тест придется делать для каждой модели ноутбука, которая есть у Dell, это время выглядит уже не столь нелогичным. Но всё равно Dell иногда изменяет свой набор продуктов ещё быстрее J Впрочем, это ещё цветочки. Проверка двух миллионов результатов – вот где ожидает нас по-настоящему большая проблема. Мы не можем положиться на ручную проверку – это было бы слишком дорого и долго. Мы могли бы написать другую программу, которая проверяет эти результаты и оценивает их, используя систему правил («если пользователь выбирает 1Гб оперативной памяти, то конфигурация должна включать в себя 1Гб памяти и итоговая цена должна стать больше базовой на стоимость 1Гб памяти»). Существуют хорошие инструменты для проверки на базе правил, однако, это либо специально разработанное ПО, либо настолько универсальное, что требуется большие вложения, которые сделают его применимым для конкретного случая. Кроме того, вместе с системой проверок, основанной на правилах, мы получаем цену поддержки правил. Правила проверки должны регулярно обновляться, поскольку Dell регулярно изменяет способы конфигурации и правила формирования цены на ноутбуки. Поскольку мы – не Dell с его десятками миллиардов долларов выручки, нам нечем обосновать инвестиции такого объема. В общем, следует признать, что мы не можем позволить себе протестировать все до единой комбинации. Часть 2Решаем проблемуСуществует множество приложений, которые имеют миллионы или миллиарды вариантов комбинаций входных параметров. Однако мы только что обсудили, насколько нерационально тестирование полным перебором. Как же они тестируют свое сложное программное обеспечение? Случайная выборкаВполне очевидно, что случайным образом проверяя различные сочетания входных параметров, можно найти ошибки. Однако представим, что программа имеет миллион комбинаций входных параметров (половину от предыдущего примера). Каждый случайный набор параметров дает нам покрытие в 0,000001% всего числа вариантов. Даже запустив 1000 тестов, мы будем иметь всего лишь 0,001-процентное покрытие множества входных данных. К счастью, статистика помогает нам делать определенные утверждения об уровне качества нашего ПО на основании таких выборок. Правда, при этом мы не можем использовать «уровень покрытия» как ключевой показатель качества. Нужно мыслить немного по-другому. Вместо этого мы должны говорить об уровне достоверности достижения некоторого уровня качества. И для заданного уровня достоверности нам необходимо определить размер выборки или количество тестов, которые необходимо запустить, чтобы дать статистическое заключение о качестве приложения. Для начала давайте определим цель по качеству: мы хотим быть уверены, что наше ПО на 99% свободно от ошибок. Это означает, что не более, чем в 1% пользовательских сессий будут возникать ошибки. Чтобы быть на 100% уверенными, что это высказывание истинно, мы должны будем протестировать по меньшей мере 99% от всех возможных пользовательских сессий, то есть выполнить более 990 000 тестов. Добавив в наш анализ доверительную вероятность, мы можем использовать для оценки качества ПО выборки, то есть выбирать подмножество входных данных и экстраполировать результаты на этом подмножестве на все множество. Определим в качестве нашей цели 95% уровень достоверности того, что наше ПО на 99% свободно от ошибок. Уровень достоверности в 95% говорит о том, что если мы будем постоянно проводить эксперименты (то есть в нашем примере – делать случайную выборку определенного размера из множества входных данных и запускать на ней тесты), то в 95% случаев результаты этих экспериментов будут находиться в пределах допустимого (то есть среди них будет не более 1% завершившихся неуспешно). Если у нас есть миллион комбинаций, то сколько из них требуется проверить, чтобы определить уровень качества с уверенностью в 95% и уровнем допустимых ошибок 1%? Алгоритмы расчета легко доступны, в сети есть бесплатные калькуляторы для определения размеров выборки. Требуемый для этого размер выборки – 9 513. То есть, если мы протестируем 9 513 пользовательских сессий со 100%-м успехом, мы тем самым получим 95%-ную уверенность, что наше качество находится как минимум на уровне 99%. Для достижения 99%-ной уверенности нам потребовалась бы выборка несколько большего размера – 16 369. Этот подход масштабируется при увеличении общего числа комбинаций. Взгляните на следующую таблицу, где наша цель – установить 99% уровень достоверности для 99% уровня качества. Каждая следующая строка в таблице соответствует все более сложному программному приложению (под сложностью здесь понимается количество уникальных сочетаний возможных входных параметров).
Вы видите, что несмотря на усложнение программного обеспечения, требуется не так много дополнительных тестов, чтобы достичь того же уровня качества. Если мы имеем умеренные цели по качеству, такие как 99/99 (99% уверенность в 99% качестве), этот подход является очень эффективным. С другой стороны, этот подход не слишком хорошо масштабируется на более высокие уровни качества. Рассмотрим задачу получения «пяти девяток» (кода, свободного от ошибок на 99,999%). С увеличением желаемого уровня качества количество тестов, которые требуется выполнить, возрастает и быстро превращается в тот же самый полный перебор. Строки в данной таблице представляют возрастающие требования по качеству, при этом сложность ПО остается неизменной – миллион возможных комбинаций.
Метод случайной выборки не дает выигрыша перед методом полного перебора, если требования по качеству становятся слишком высокими. Попарное тестирование входных параметровИсследования показывают, что ошибки в программном обеспечении чаще зависят от определенного сочетания значений нескольких переменных, а не от отдельных переменных. Возьмем очень простую страницу конфигурирования ноутбка, имеющую три управляющих элемента с возможностью выбора трех параметров: процессор, память и размер диска. Каждый параметр может принимать одно из трех возможных значений, как показано в таблице ниже.
Мы можем успешно пройти тесты для каждого значения, доступного для параметра «Процессор», а после этого обнаружить, что тест выдает ошибку, если пользователь выбирает «Стандартный» процессор и «Гигантский» размер диска. Это показывает наличие зависимости между параметрами «Процессор» и «Диск». Попарное тестирование (pair-wise testing) предназначено для покрытия всех сочетаний пар переменных без учета всевозможных комбинаций всех остальных переменных. В данном примере имеется 27 различных комбинаций выбора. Следующая таблица показывает первые 9 комбинаций, для остальных вариантов выбора Процессора также требуется по 9 комбинаций.
Полное попарное тестирование гарантирует, что будет проверено каждое уникальное сочетание значений любых двух переменных. Следующая таблица показывает сочетания для приведенного примера.
Всего лишь с помощью 9 тестов мы можем с избытком покрыть любое сочетание пар Процессор и Память, Процессор и Диск, Память и Диск. Попарное тестирование дает нам полное покрытие всех комбинаций каждой пары переменных при минимальном количестве тестов. Попарное тестирование не только дает нам полное покрытие для каждой из пар, но также дает нам полную (избыточную) проверку значений для каждого отдельного параметра. Если мы вернемся к нашему предыдущему примеру с конфигурациией ноутбука, мы сможем посчитать количество тестов, требуемых для полного покрытия всех пар. Для конфигуратора ноутбука начального уровня имеется 32 256 уникальных комбинаций входных данных. Мы можем проверить все уникальные комбинации пар переменных с помощью 31 теста. Для конфигуратора профессиональных ноутбуков имеется 2 322 432 уникальных комбинации. Чтобы проверить все уникальные пары переменных, достаточно выполнить 36 тестов. Тестирование сочетаниями по NКонцепция попарного тестирования может быть расширена до тестирования «сочетаниями по N» – комбинациями по N возможных параметров. Следующая таблица показывает, сколько тестов требуется, чтобы получить полное покрытие сочетаниями по N для экономной и профессиональной конфигураций ноутбуков.
Этот способ гораздо лучше масштабируется. Используя N=3, мы получаем 179 тестов против 2,3 миллионов, требуемых для полного покрытия! Существующие исследования показывают, что N=3 обеспечивает порядка 90% покрытия кода, хотя это значение может меняться от приложения к приложению. Мы будем использовать N=3, поскольку практический опыт показывает, что тесты с N=4 редко обнаруживают ошибки, которые были бы пропущены при N=3. Зависимость от порядка и статистическое тестированиеСледует отметить, что описанный подход работает только тогда, когда пользователи либо должны вводить значения в предписанной последовательности, либо последовательность ввода неважна. То есть этот способ не слишком хорошо подходит для случаев, когда пользователям разрешено делать выбор в произвольном порядке, и при этом сам порядок имеет значение. Имея в пользовательском интерфейсе 5 элементов, мы имеем 5! = 1*2*3*4*5 = 120 возможных последовательностей ввода. И хотя интерфейс может включать в себя динамическую фильтрацию, предохраняющую пользователя от определенных некорректных подмножеств значений аргументов, тестирование сочетаниями по N является «тестированием черного ящика» и не может иметь доступа к подобной информации. Для того чтобы получить полное покрытие для интерфейса с M возможными элементами управления, каждый скрипт, созданный генератором тестирования сочетаниями по N, будет необходимо протестировать M! способами в соответствии с числом способов последовательно выбрать каждый из M элементов. Если элементы разнесены по нескольким экранам, то мы можем уменьшить число этих способов. Например, если на первом экране имеется пять элементов, и пять на втором, то вместо того, чтобы рассматривать 10! (3,6 млн последовательностей), мы можем рассмотреть все последовательности первого экрана в комбинации со всеми последовательностями второго экрана (5! * 5! = 120 * 120 = 14 400 последовательностей). В нашем примере с ноутбуками имеется 11 и 13 элементов управления (все на одной странице) для экономной и профессиональной конфигурации соответственно (примечание: так было на момент написания статьи, сейчас Dell использует многостраничный конфигуратор). Следовательно возникает 11! и 13! возможных последовательностей (40 миллионов и 6 миллиардов). Однако нам не нужно выполнять полное покрытие тестами последовательных перестановок всех параметров. Тестирование сочетаниями по N в особенности помогает анализировать кросс-зависимость между комбинациями из N управляющих элементов, остальные мы сознательно игнорируем, когда используем этот подход. Поэтому в качестве нижней границы нам потребуется запустить только N! наборов входных аргументов для каждого сгенерированного скрипта. Так, наш набор из 179 скриптов для профессиональных ноутбуков с N=3 потребует 3! * 179 = 1074 запуска. Ниже представлена таблица для нижней границы количества запусков при различных значениях N для обеих конфигураций ноутбука.
Это нижняя граница, поскольку она предполагает доступность всех последовательностей в каждой группе из N элементов. Существующие инструменты тестирования сочетаниями по N (насколько знает автор) не принимают в расчет порядок действий. Для N=2 это тривиально – просто сделайте ещё один набор тестов с аргументами в обратной последовательности. Мы можем учесть порядок действий, рассматривая его как дополнительный входной параметр. Он будет принимать столько значений, сколько существует подмножеств заданного размера N. Для вычисления используем соответствующую математическую формулу: M!/(N!*(M-N)!), где M – число входных параметров. Ниже представлена таблица, показывающая число комбинаций для каждого N для обсуждавшихся экранов экономной и профессиональной конфигураций ноутбуков.
В следующей таблице представлены значения для некоторых других значений числа входных параметров.
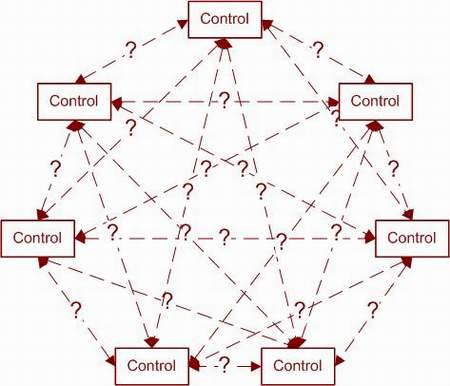
Теперь можно сгенерировать тесты, задав инструменту N+1 параметр, и указав число уникальных последовательностей, как если бы это был элемент ввода. К сожалению, нам не удалось найти элемент, способный работать с параметрами, принимающими больше 52 значений. Это ограничивает наши возможности по созданию тестов для N=3 всего семью параметрами. Чтобы показать влияние последовательности ввода на количество тестов, рассмотрим интерфейс с 7 параметрами, каждый из которых имеет 5 возможных значений. N=3 потребует 236 тестов в случае, если порядок не важен. Затем включим последовательность выбора как параметр (добавив 8-й элемент управления с 35 возможными значениями и N=4). В этом случае инструмент генерирует 8 442 тестов. А теоретическая нижняя граница равна 236 * 35 = 8 260. Часть 3 из 3Как сделать это еще лучшеКогда мы совсем ничего не знаем о структуре тестируемого приложения, или не применяем то, что знаем, к нашей стратегии тестирования, мы получаем слишком много тестов. Используя знания о приложении, мы можем значительно сократить набор тестов. Здесь мы переходим от тестирования методом черного ящика к тестированию методом белого, или прозрачного, ящика. Карта зависимостей элементов управленияВ нашем предыдущем примере мы не использовали никакого знания о взаимодействии элементов управления или взаимодействиях внутри программы при обработке введенных значений параметров. Если представить визуально элементы управления и их возможные взаимодействия, получится нечто похожее на следующую диаграмму:
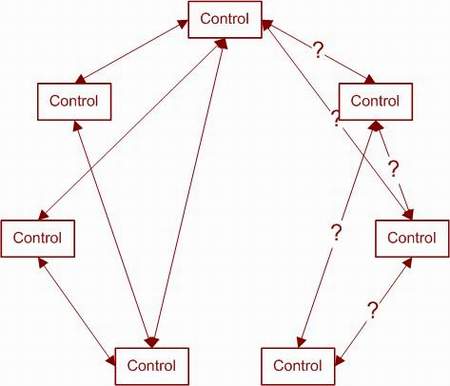
Между некоторыми парами элементов, возможно, имеются значимые зависимости. А между другими нет абсолютно никаких зависимостей. При разработке тестов мы не учитывали ни того, ни другого, что и показано на диаграмме. Возможно, мы сможем выявить и описать некоторые из связей, но нет гарантии, что мы найдем их все. Наш подход должен быть консервативным – убирать только те зависимости, о которых мы точно знаем, что они не существуют. Это знание проистекает из понимания сути работы приложения. Как только мы уберем эти связи, диаграмма станет выглядеть примерно так:
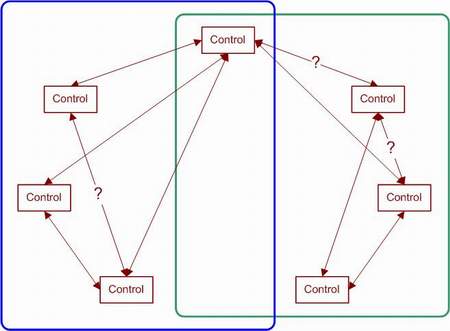
Эта уточненная схема позволяет нам существенно сократить размеры нашего набора тестов, поскольку устанавливает независимость многих элементов. В идеальном случае результатом будут два или несколько несвязных графов, и мы сможем построить набор тестов для каждого отдельного графа. Как видно из диаграммы выше, данные два графа не являются полностью независимыми. Мы можем использовать подход к тестированию, изображенный на следующей диаграмме.
Мы сгруппировали в голубую рамку все элементы управления слева – это элементы, которые будут использованы для создания набора тестов в инструменте генерации сочетаниями по N. Группа справа также будет использована для генерации набора тестов. В этом примере мы значительно уменьшили требуемое число тестов для случая, когда важен порядок.
Обратите внимание: если у нас есть пересекающиеся элементы управления (если графы не могут быть разделены), то число тестов для случая, когда порядок неважен, увеличивается. Если графы могут быть разделены, то это уменьшает количество тестов даже для случая, когда порядок неважен. Разделяя графы, вы должны убедиться, что все элементы соединены только с элементами в своей группе (включая область перекрытия). Эквивалентные значения можно объединитьЕсли мы знаем, как реализован код, или видим требования, то мы можем еще сильнее уменьшить объем тестирования, исключив эквивалентные значения входных параметров. Рассмотрим следующий пример требований к приложению:
Имеются две переменные, которые мы рассматриваем в нашем тестировании – представьте, что они являются элементами управления в пользовательском интерфейсе или величинами, получаемыми из внешней системы.
Для наших целей тестирования мы можем свернуть множества в следующий вид:
Это слияние эквивалентных величин уменьшает количество тестов. Для нашего простого примера количество сочетаний уменьшилось с 18 до 12. Если используется больше элементов управления, и мы выполняем тестирование сочетаниями по N при N=3, сокращение гораздо более значительное. ЗаключениеМы можем тестировать очень сложное программное обеспечение, не выполняя полное покрытие тестами области входных данных. Одна из распространенных техник – случайные выборки, однако, они проигрывают при высоких требованиях к уровню качества – высокое качество требует большого размера выборки. Попарное тестирование позволяет нам тестировать очень сложное программное обеспечение, используя весьма небольшое количество тестов при неплохом (в районе 90%) покрытии кода. Оно также проигрывает при высоких требованиях по качеству, но является очень эффективным при относительно низких ожиданиях. Тестирование сочетаниями по N при N=3 дает высокие по качеству тестовые наборы, но ценой увеличения количества тестов. В случае, когда имеет значение порядок ввода значений, возникает ограничение по числу переменных (менее 10), которое поддерживают современные инструменты генерации тестов. Для улучшения стратегии тестирования мы можем использовать знания о тестируемой программе и требованиях. Предыдущие методы не требовали никакого знания о приложении, обеспечивая покрытие за счет грубой силы. Такой подход неизбежно приводит к избыточным тестовым наборам. Выявляя взаимозависимости между входными параметрами и разделяя тестирование на несколько областей, мы снижаем количество тестов. Удаляя избыточные или эквивалентные величины из набора тестов, мы также уменьшаем количество тестов, не снижая при этом качества тестирования. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||