Что пишут в блогах
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Школа для начинающих тестировщиковНачало: 9 июля 2026
-
Азбука ИТНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Python для начинающихНачало: 9 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| 1 тест = 1 проверка. Чем хорош принцип атомарности в автотестах в Postman |
| 30.03.2026 00:00 | ||||
|
Автор: Ольга Назина (Киселёва)
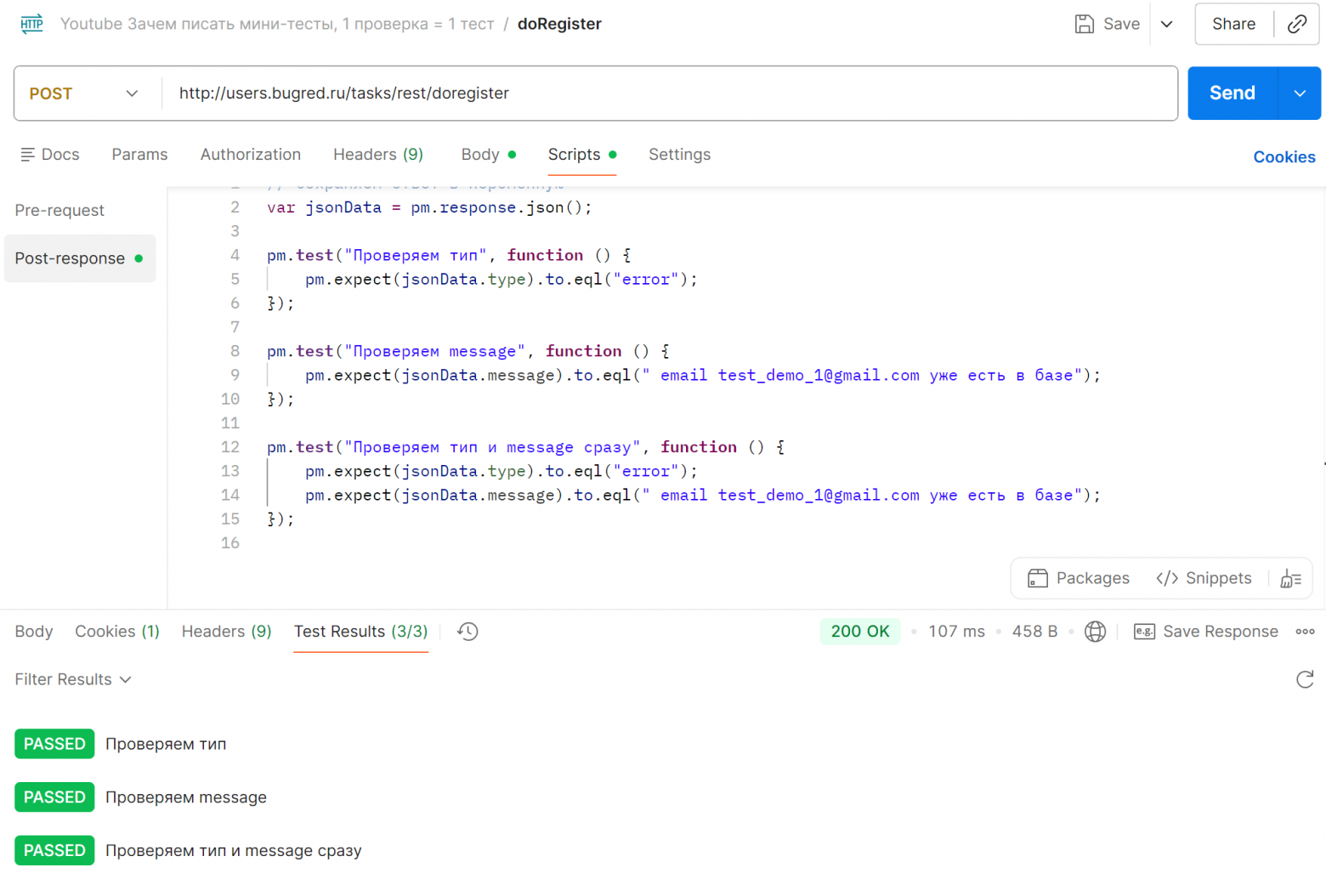
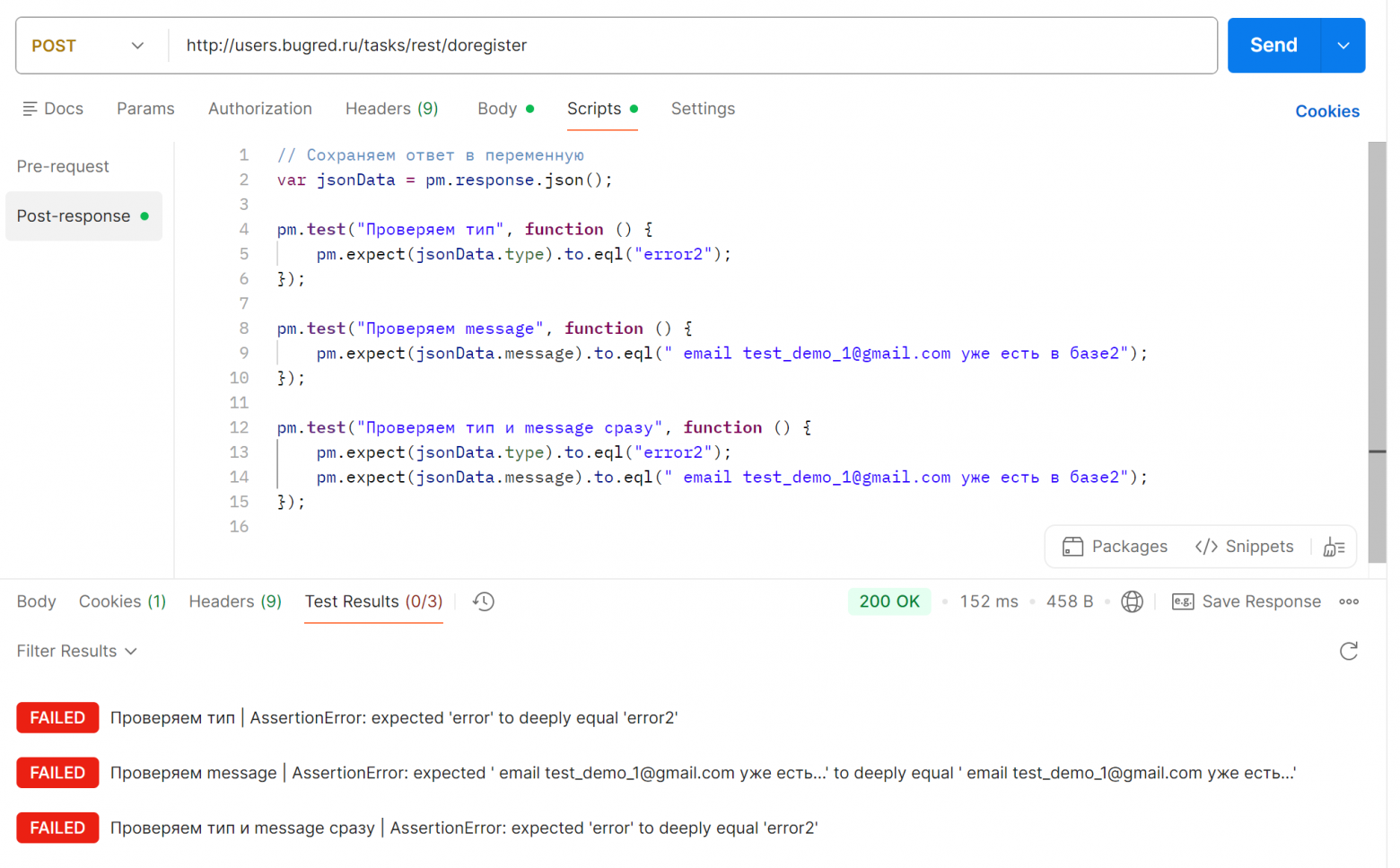
Принцип атомарности (объект или операцию нельзя разделить на части, не нарушив их целостность или смысл) применяется в как в разработке кода ПО, так и в разработке кода автотестов. И в автотестах Postman он особенно хорош! Давайте разберемся на примерах, почему лучше писать небольшие автотестики, «один тест, одна проверка», чем «много проверок в одном тесте». СодержаниеГотовим тесты Запрос будем отправлять в бесплатную систему Users. Метод doRegister: Если с первого раза запрос не упал, отправляем повторно, чтобы получить ошибку в ответе: Напишем автотесты на эти 2 поля. Какие тут есть варианты? Мы можем писать маленькие тесты, одна проверка, один тест: А можем объединить, то есть написать один тест, который проверяет и тип, и message сразу (добавим его в те же скрипты, поэтому переопределять jsonData уже не надо): Отправляем запрос — все 3 теста проходят успешно:
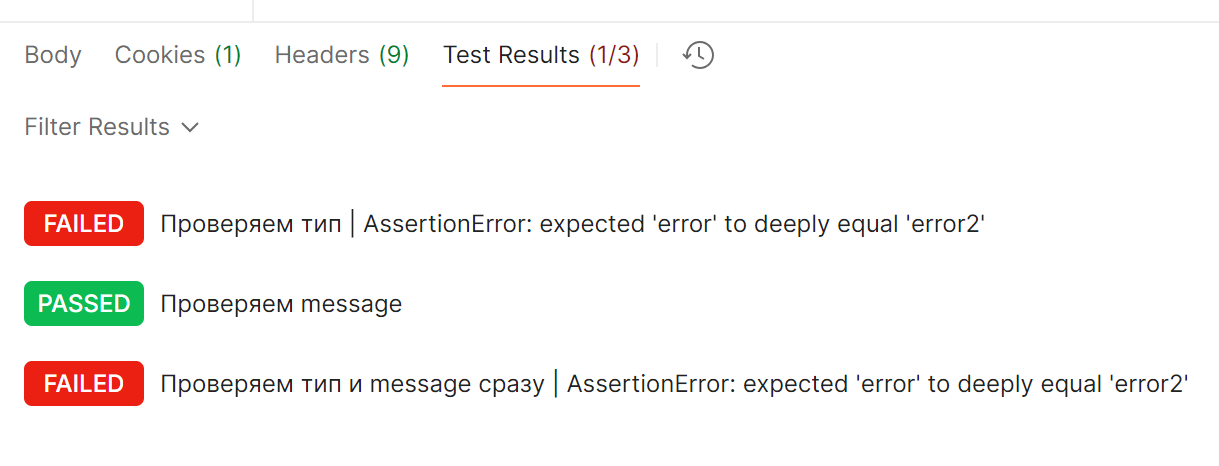
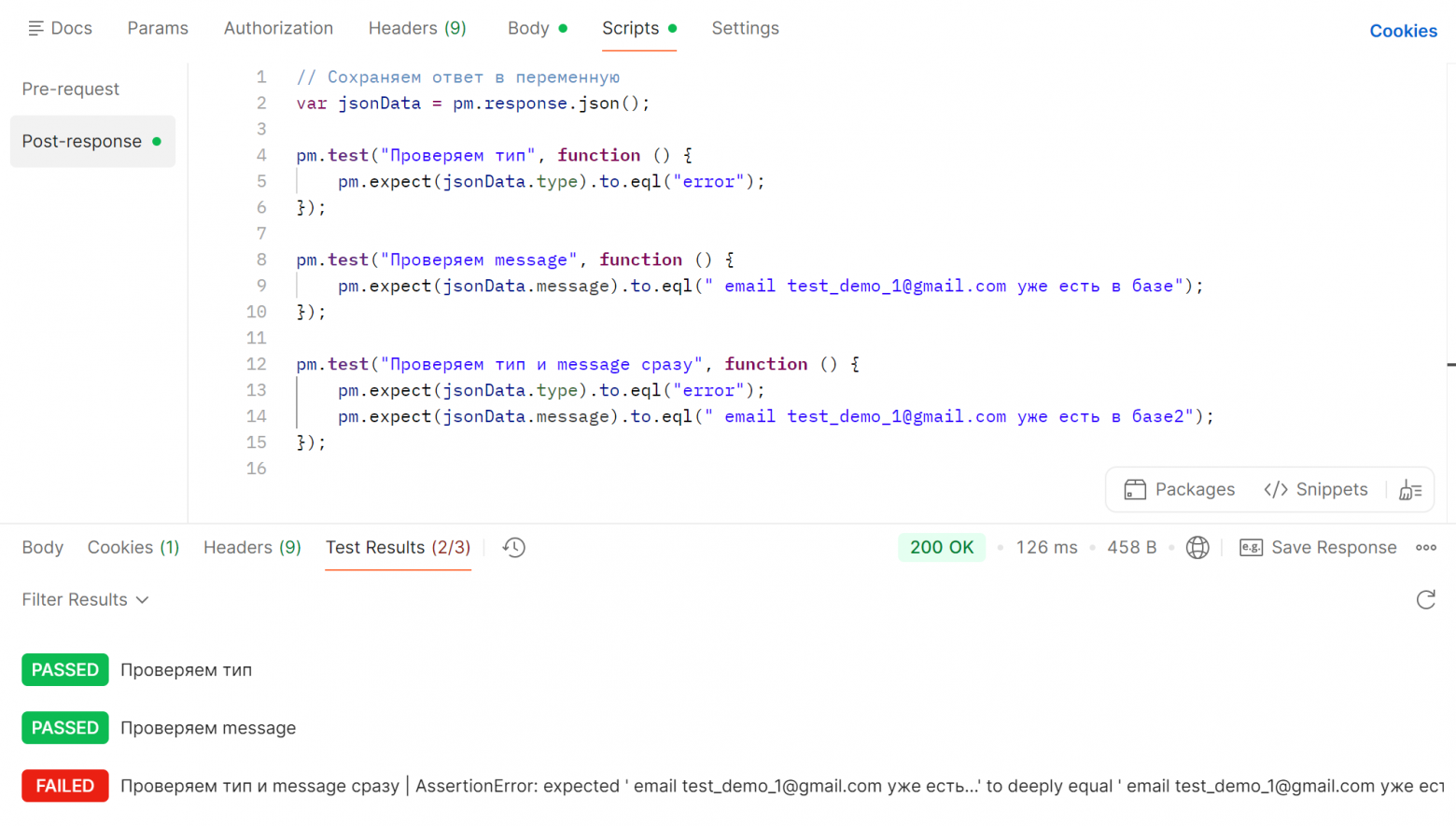
Отлично! Пока выглядит так, что третий тест даже лучше, за один тест дает информацию, что в ответе всё хорошо. Но что будет при падении? Одна проверка упалаСломаем тесты 1 и 3, поменяв «error» на «error2». Автотесты теперь выглядят так: Отправляем запрос, тесты упали. Сообщения об ошибке одинаковые:
Но в первом тесте мы четко понимаем, о каком поле идет речь. Что-то не то в поле «тип». Дальше локализация простая:
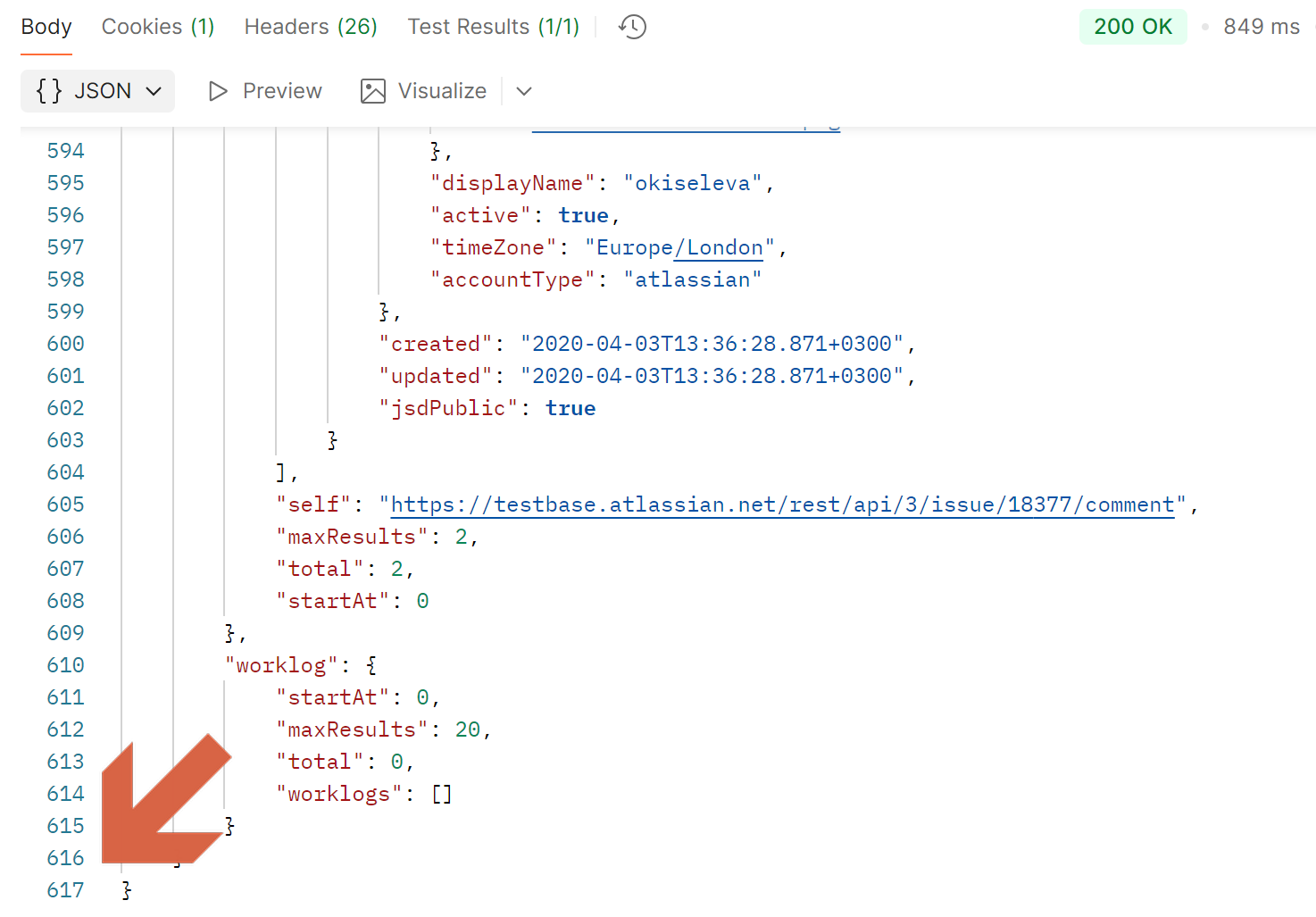
Теперь посмотрим на 3 тест, где несколько проверок сразу. Текст ошибки вроде тот же самый... Но! Мы не знаем, в каком именно поле произошла ошибка. Сейчас у нас небольшой тест на 2 поля, причем очевидно разных (короткий английский текст и длинный русский), поэтому найти сломанное поле не составит труда. Но что, если полей будет больше? Да не беда, можно найти через Ctrl + F! А что, если поля будут похожи между собой? Давайте посмотрим на пример ответа в запросе «get issue» в Jira — получить информацию по задаче в баг-трекере. В ответе 617 строк:
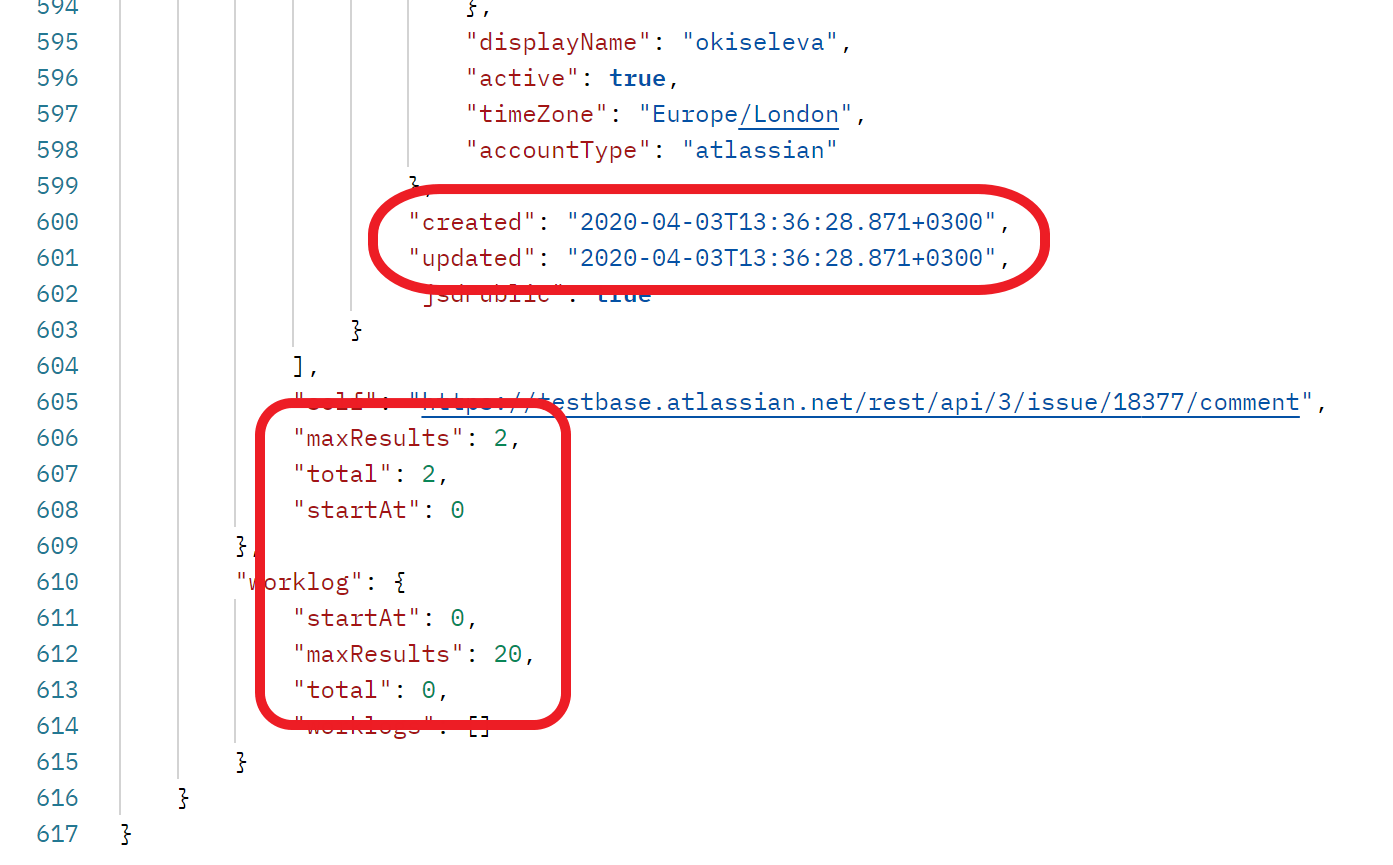
Да, часть из них “пустые”, в которых просто фигурная скобка, но тем не менее, там около 400 строк с данными. А ещё обратите внимание, что некоторые данные похожи — дата со временем или число:
А теперь представим, что у нас один тест, который проверяет работу всех полей. И вот он падает с ошибкой:
Или
Ну и как вам поможет Ctrl + F, если таких дат или нулей в ответе штук 20? А если 50? То есть надо найти все нули, выписать себе куда-то в блокнотик, в каких именно полях они встречаются, открыть Body, пройтись по всем этим полям... Мы тратим время просто на то, чтобы понять, в каком именно поле возникла ошибка! А вот будь у нас атомарные тесты, этой проблемы бы не было. Несколько проверок упалиСломаем теперь тесты на оба поля! В message тоже добавим 2 в конец. Вызываем запрос и смотрим на ошибки:
Да, при атомарных проверках результат выглядит грустно — вроде один запрос, а сразу несколько упавших тестов! Это в нашем случае их 2, но обычно их хотя бы с десяток… Но зато мы можем сразу пройтись по всем упавшим полям и их исправить. Давайте так и сделаем:
Кайф! Запускаем:
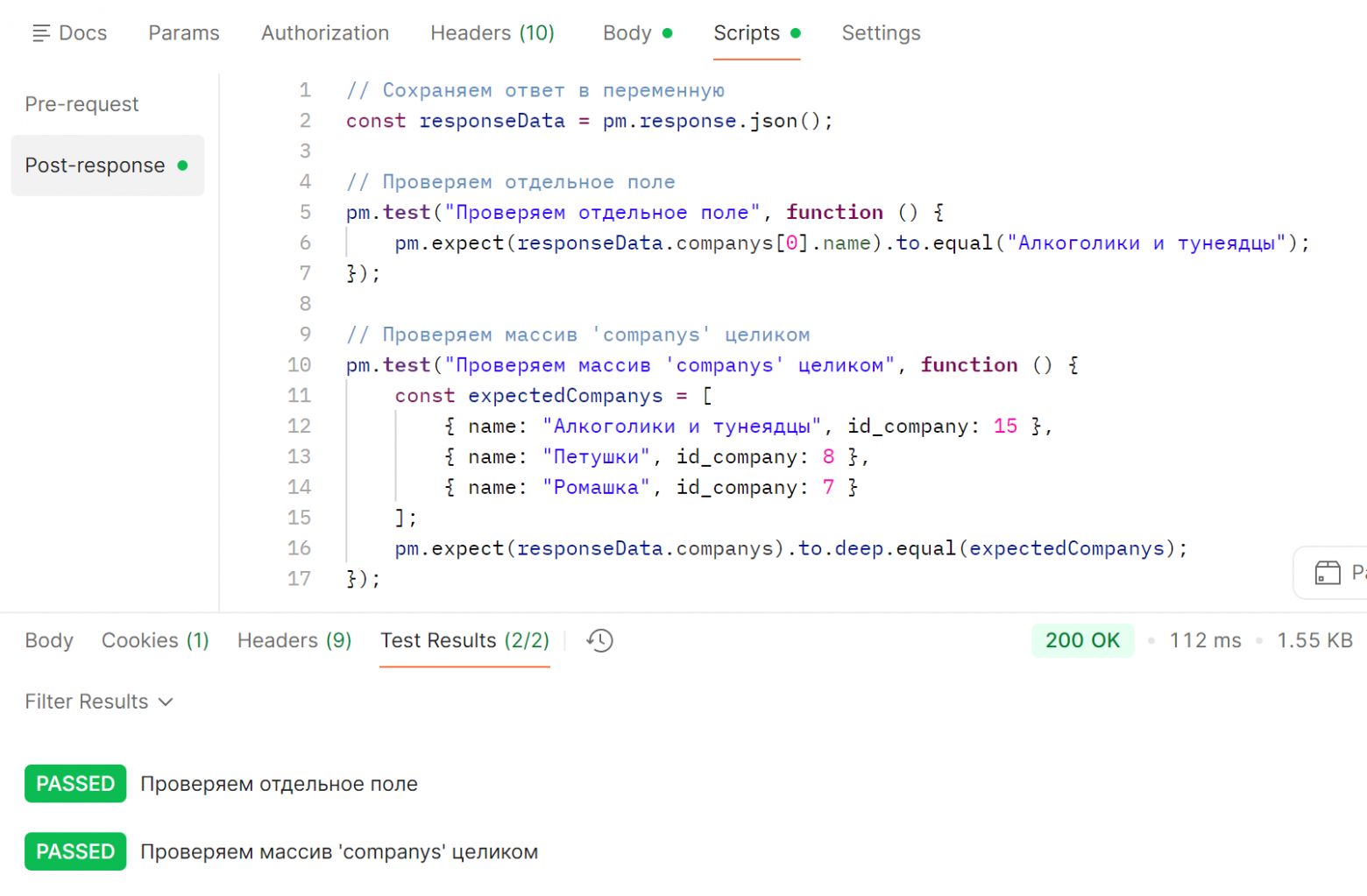
Атомарные тесты позеленели, так как мы прошлись по сообщениям об ошибке, исправили их, и теперь всё хорошо. А вот комплексный тест продолжает падать. Только сообщение об ошибке уже другое. Да, type мы исправили, но в message то тоже проблема! Теперь он подсвечивает нам её. Исправим message, упадет на чем-то ещё... Потом ещё, и ещё... Раздражать начинает уже со второго раза =)) Получается, что мы тратим кучу времени на то, чтобы отладить наш автотест. И мы не видим сразу полную картину, сколько полей рассыпалось. Чтобы это понять, нам надо 10 раз, а то и больше прогнать наш автотест. И это, конечно, не очень удобно. Падение в массивеВ примерах выше падение было в обычном поле на верху дерева json-ответа. И то сообщение не самое лучшее, так как Postman пишет, что сломалось, но не пишет, где. А что будет, если сломается что-то в массиве? Вызовем метод getUserFull в том же Users: В ответе возвращается массив компаний: Снова напишем автотесты в 2 вариантах — атомарные (проверим пока только 1 поле, остальные тесты делаются по аналогии) и тест на проверку массива целиком: Отправляем запрос — всё работает:
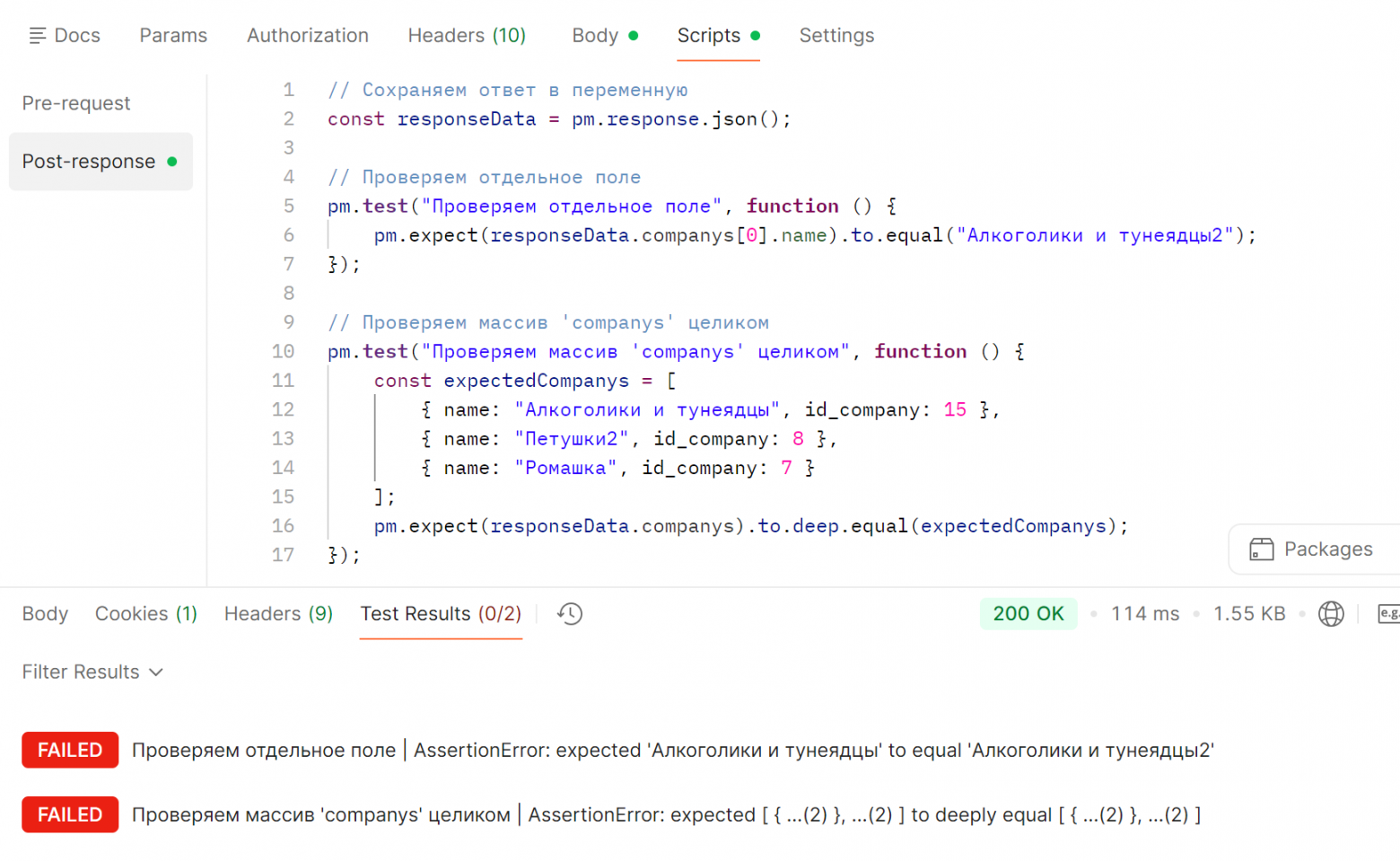
Теперь изменим в тестах название компании и посмотрим на результат:
Атомарный тест — всё понятно. А вот комплексный… Он дает лишь информацию “у тебя что-то сломалось”, увы. Тут даже не поищешь проблемное поле через Ctrl + F, потому что у нас даже сообщения об ошибке толком нет, какое значение ожидалось и какое есть по факту. В итоге надо или глазками сравнивать автотест и ответ от сервера, или использовать ChatGPT, если там нет какой-то NDA-информации. Простые сравнивалки текста не особо помогут, если в тесте нет фигурных скобок на новой строке и прочих “украшалок” текста. А вот чем хорошо скормить ошибку ChatGPT — если у нас несколько проблем в автотесте, он сразу подсветит их все. Зато если ChatGPT использовать нельзя, снова придется страдать, выискивая ошибку, исправляя, отправляя запрос и снова ища ошибку, не зная даже, сколько раз повторится этот цикл… ИтогоАтомарные тесты значительно лучше — они дают больше информации о падении:
Конечно, если писать автотесты не в Postman, а делать свой фреймворк, части проблем можно будет избежать:
Тогда уже можно будет что-то объединять и, например, выверять ответ от сервера сразу весь, а не по отдельным полям. Но если говорить про автотесты в Postman, то тут атомарность однозначно лучше тестов «я надену всё лучшее сразу» «я проверю всё за один присест»! |