Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Стратегии упрощения определений шагов BDD |
| 04.06.2025 00:00 | ||||||||||||
|
Как тестировщик, вы, возможно, слышали о разработке через поведение (BDD) и окружающих ее спорах о том, что это, как это использовать и для чего. Вне зависимости от личного мнения о предмете, нельзя отрицать, что инструменты автоматизации тестирования, поддерживающие BDD, уже с нами. Они широко распространены в отрасли, и пока не собираются никуда уходить. В ходе моей карьеры значительная часть моей тест-автоматизации включала применение какого-либо BDD-фреймворка – например, инструменты вроде Cucumber или JBehave. Как человек, который программирует, я всегда интересовался рефакторингом, сокращающим количество стандартного или дублирующего кода – кода становится меньше, и он становится понятнее. Это включает и сокращение стандартного кода в методах определения шагов и прочем связующем коде. Как их упростить? Или вообще от них избавиться? Возможно, вы недоумеваете, что такое связующий код. С одной стороны, он состоит из методов определения шагов – это методы, говорящие BDD-фреймворку автоматизации, что запускать, столкнувшись с шагом Given, When или Then в фича-файле Gherkin. По сути эти методы склеивают части текстовых Gherkin-файлов в выполнимый код тест-автоматизации. С другой стороны, это могут быть хуки – методы, выполняющиеся до или после фич/сценариев Gherkin. В этой статье я расскажу о различных способов упрощения связующего кода и его интеграции в язык ваших автотестов. В примерах я использую Cucumber и Java-код. Стандартные определения шагов CucumberЧтобы погрузить вас в контекст, начну с демонстрации, как обычно выглядит определение шага Cucumber в Java. Используем регулярное выражение, как шаблон шага: @When("^user attempts to log in with (.*) username and (.*) password$")
Или используем выражение Cucumber, как шаблон шага: @When("user attempts to log in with {string} username and {string} password")
Важные части этого метода:
Теперь посмотрим, как это можно упростить или выполнить иным образом. Определения шагов на основании лямбда-выражений Java 8Многое улучшилось и упростилось, когда в Java 8 появились лямбда-выражения. Стали доступными альтернативные способы разработки приложений. Это в том числе включает Cucumber, а также новый способ определения шагов с лямбда-выражениями. Для этого нужно использовать другую зависимость, а именно cucumber-java8. Когда это настроено, нужно внести изменения в классы определения шагов. Класс должен реализовать интерфейс io.cucumber.java8 (или один из его специфичных для языка вариантов). После этого в классе определения шага станут доступны новые методы, специфичные для типа шага (Given(), When() и т. д.) Текущие методы определения шагов (или как минимум те, которые нуждаются в упрощении) нужно сконвертировать и переместить в конструктор класса. То есть такой метод: class LoginStepDefs {
станет таким: class LoginStepDefs implements En {
С точки зрения читабельности:
Идут споры на предмет того, что лучше – обычная форма метода или лямбда-форма. Вопрос как личных предпочтений, так и практических аргументов (например, инъекции зависимостей), и обсуждается даже возможность замены библиотеки Java 8 в Cucumber на альтернативное решение. Бесструктурные аннотации шаговАннотации шагов могут вызывать вопросы:
Давным-давно, в прошлом проекте, у нас было кастомное решение автоматизации и средство запуска тестов, слегка отличавшиеся от Cucumber и других BDD-фреймворков. Это решение пользовалось своими собственными аннотациями @Given, @When и т. д., с одним основным отличием: в них не требовалось задавать паттерн шагов. Вместо этого нужно было сформулировать имя метода определения шага так, чтобы оно использовалось в файлах Gherkin. Пример: @Given Вы наверняка заметили буквы в верхнем регистре - X, Y и Z. Они позволяли пользователям параметризовать эти методы, и работало это так:
^user attempts to log in with (.*) username and (.*) password on (.*)$
Это работает обратным по сравнению с определениями шагов Cucumber образом. Там вы задаете реальный паттерн без имени метода, а тут – имя метода в качестве своеобразного паттерна, не задавая реальный паттерн. Преимущество тут в том, что не нужно задавать паттерн в аннотации – только в имени метода. Кода меньше, он понятнее. Но аннотации шагов все еще предоставляют атрибут для кастомного паттерна, если сгенерированного по умолчанию недостаточно. В этом случае инженеры должны формулировать имена методов определения шагов так, как они будут использоваться в файлах Gherkin, и шаги становятся понятнее. Нет также путаницы, когда паттерн шага используется с другим именем метода без всяких на то причин – например, как в этом случае: @When("user attempts to log in with {string} username and {string} password")
Использование преимуществ кастомной интеграции IDEПрименение кастомного IDE-плагина необязательно снижает количество имеющегося тест-кода, но может как минимум повысить его понятность и качество. Моя идея включает фичу сворачивания кода – она стандартна во многих IDE и текстовых редакторах. Код сворачивается, когда какой-то диапазон текста в документе становится скрытым (по сути, сворачивается и разворачивается), и заменяется кастомным текстом-плейсхолдером, сообщающим вам, что находится в свернутой секции. Такой плейсхолдер может быть просто эллипсисом (символом многоточия). Как правило, это используется, когда содержимое (скажем, тело метода) не относится к делу на данный момент и должно быть скрыто.
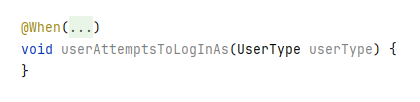
Или же это контекстные данные, дающие ту же или почти ту же информацию, что и развернутый код, но более простым образом. Хороший пример – это сворачивание создания анонимного экземпляра объекта в Java в стиле лямбда-выражений. При таком методе: CredentialsProvider getCredentialsFor(String userType) {
свернутый код будет выглядеть так:
Теперь, когда вы увидели ряд простых примеров сворачивания кода, рассмотрим идеи сворачивания определенных частей методов определения шагов, чтобы они стали понятнее. Использование паттерна шага вместо имени метода определения шагаМой опыт показывает, что, читая и вникая в метод определения шага, люди концентрируются на его понимании, читая паттерн шага, а не имя метода. Почему бы не улучшить этот аспект? Так как имя метода может дублировать паттерн шага, и его нельзя опустить, если задействованы реальные методы, сделаем это понятнее. Тут нужно два действия. Для начала – свернуть паттерн шага в аннотации шага в эллипсис, вот так:
Код становится чище, и у вас все еще есть информация о том, для какого типа шага (Given, When или Then) предназначен этот метод. Затем, если вы предпочитаете читать паттерн шага, и этот паттерн дает больше контекста шагу, чем имя метода, можно пойти дальше. Сверните имя метода, используя паттерн шага в качестве плейсхолдера.
Если есть такая возможность, можно также свернуть ключевые слова public и void, и у вас получится такая «сигнатура» метода:
Конечно, можно при желании пойти еще дальше, или вообще в ином направлении, кастомизируя эту сворачиваемость. Зависит от нужд проекта или личных предпочтений. Динамическое разрешение шаговДопустим, ваши шаги имеют четкий формализуемый формат. Вы не хотите возиться с внедрением отдельных определений шагов для каждого из них, потому что это бессмысленная дупликация. В такой ситуации вы можете сделать вот что – и мы сделали это в прошлом проекте: использовать динамический парсинг и разрешение шагов. Это устраняет нужду во внедрении реальных методов определений шагов. Мы в основном пользовались этим для создания шагов валидации для тест-автоматизации web-UI, как показано ниже (верхний регистр – отсылки к Selenium WebElements и Bys).
Как можно видеть, это работает в обратном порядке. Возьмем последний пример:
Все это возможно благодаря внедрению общей логики парсера. Как только она налажена, код для явного внедрения такого типа шагов Gherkin не нужен. Единственный код в этой области – это исправления багов, улучшения логики парсера или расширение соответствующих page objects. Конечно, можно поспорить о читабельности этих шагов, или возможности заменить их визуальным тестированием. Но в свое время их структура и формат нас устраивали. Можно было также кастомизировать соответствующие элементы страницы, выбирать элементы по индексу, и многое другое. Для нас это был отличный способ внедрения валидации с минимумом кода. Использование фреймворков с предустановленными библиотеками шаговОдин из способов минимизации связующего кода – это полное избавление от него. Этого можно достичь, к примеру, используя библиотеки, которые предлагают предустановленные шаги для распространенных (или не очень) задач. Они также могут содержать различные шаблонные решения и языки выражений для кастомизации шагов и действий с помощью динамического ввода – например, различных типов тел запросов и заголовков для отправки HTTP-запросов в API-тестах. Я лишь вкратце описываю некоторые библиотеки – просто чтобы дать представление, с чего начать, а затем, если интересно, погрузитесь в них самостоятельно.
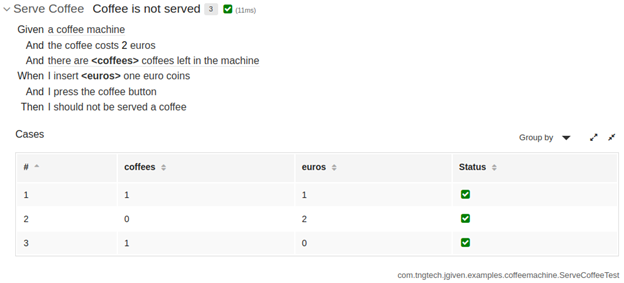
Вывести разработку сценариев на уровень кодаЭтот подход не избавляется от методов определения шагов, но зато упрощает тесты с другой, по сути противоположной стороны по сравнению с предыдущим разделом. Вместо внедрения тестов в Gherkin или аналогичные файлы с необходимостью разбираться с реализацией определения шагов, вы внедряете тесты как реальный код на похожем на Gherkin DSL (доменно-специфичном языке). В этом случае вам не нужно иметь дело с реальными файлами Gherkin. Этого стремится достичь фреймворк JGiven – по крайней мере, в аспектах, затронутых в этой статье. При помощи базовой настройки теста и расширения ряда базовых классов можно внедрить шаги и сценарии «Gherkin» в обычные методы JUnit, TestNG или Spock. Таким образом у вас будет нормальный прямой доступ к используемым библиотекам проверки утверждений, заглушек и т. п., а методы тестов будут похожи на настоящие сценарии Gherkin, как и генерируемые тест-отчеты. Ниже – шаг Given с более гранулярной реализацией (см. соответствующий раздел документации JGiven): @Test Или возьмем более продвинутый сценарий – нижеприведенный тест-метод JUnit 5. Он запускает параметризованный тест с различными входными данными. По сути он имитирует запуск Gherkin Scenario Outline с наборами данных, которые получает его таблица Examples. Этот пример взят из раздела «Параметризованные сценарии» документации JGiven, и слегка изменен для понятности и применения наиболее распространенного подхода JUnit 5 к параметризации тестов. @ParameterizedTest Этот тест-метод сгенерирует следующий отчет – у вас будут нормальные отчеты о тестировании и живая документация, которой можно делиться с заинтересованными лицами.
Можно пойти с этим примером дальше и применить магию плагинов IDE. Используя кастомный код для сворачивания, можно еще больше приблизить тест-код к читабельности реального сценария Gherkin – например, как-то так:
Заметьте, что это сворачивание кода не взято из существующего IDE-плагина. Оно было написано специально для статьи с целью демонстрации возможностей. Вообще не пользоваться BDD-фреймворкамиОтвет на вопрос, стоит ли писать тесты, как BDD-сценарии и использовать соответствующий фреймворк, зависит от проектной области, его ресурсов, типа приложения и других аспектов. Я многократно слышал аргумент, что связующий код добавляет ненужный уровень абстракции, так как должен быть тонким и в идеале только передавать выполнение теста базовому коду тестов. Стоит просто держать в уме, что всегда можно писать тесты, как обычные тесты JUnit или TestNG. Возможные вариантыЯ описал ряд подходов, которые можно применять в тест-наборах и в ходе тест-автоматизации. У них различные кривые обучения, и они требуют различных навыков для внедрения, поэтому я не голосую за какое-то конкретное решение. Я просто надеюсь, что смог показать вам ряд интересных способов и альтернатив и разжечь ваше воображение – теперь вы сможете поразмышлять, как упростить жизнь своей команды, используя BDD-автоматизацию. Если вы считаете, что я упустил какие-то пути упрощения, пожалуйста, дайте мне знать. Ресурсы
Дополнительная информация |