Что пишут в блогах
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Как мы создали новый тестовый фреймворк, адаптируемый к росту проектов |
| 01.06.2026 00:00 |
|
Меня зовут Анатолий Бобунов, и в EXANTE я SDET — Software Development Engineer in Test. В последние несколько лет я развивал тестовую архитектуру для бэкенд‑сервисов компании. Наш тестовый фреймворк изначально создавался как единая платформа для тестирования нескольких backend‑сервисов. По мере роста системы увеличивалось и количество сервисов, каждый из которых приносил свою специфичную логику, требования к клиентам, данным и подготовке окружения. Эти требования не всегда укладывались в существующую архитектуру. В результате появлялись локальные обходные решения, которые решали конкретную задачу, но обходили архитектурные ограничения. Со временем такие решения начали накапливаться. Разные сервисы использовали разные паттерны для HTTP‑клиентов, ретраев, подготовки данных и валидации ответов. Общие абстракции постепенно размывались, а направление зависимостей становилось менее очевидным. Дополнительно ситуацию усиливали срочные задачи, которые требовали быстрых изменений без полноценного архитектурного пересмотра. Это приводило к появлению временных решений, которые затем становились постоянными. Фреймворк продолжал работать и покрывал сценарии тестирования, но его развитие замедлялось. Добавление нового сервиса требовало всё больше исключений, интеграция новых инструментов становилась сложнее, а изменения в базовых компонентах затрагивали несвязанные части системы. В какой‑то момент стало очевидно, что текущая архитектура перестала масштабироваться вместе с количеством сервисов. В этой статье я расскажу, почему мы решили создать новую архитектурную модель, какие принципы легли в её основу и как мы подготовили фреймворк к работе с SDK и AI‑инструментами. Что было не так с тестовым фреймворком Для тестирования всего бэкенда в EXANTE мы используем монолитный репозиторий. С момента основания, компания постепенно увеличивалась, и наш тестовый фреймворк развивался вместе с ней. В разное время разные люди развивали разные блоки фреймворка и вносили в него архитектурные изменения. При этом архитектура фреймворка не всегда развивалась системно и консистентно. Часть изменений были хорошо продуманы, часть вносили как временные с расчетом на то, чтобы позже переписать или убрать их. Но нет ничего более постоянного, чем временные решения. Спустя несколько лет мы начали регулярно сталкиваться с ситуациями, когда стало сложно или невозможно внедрять улучшения во фреймворк для команды автоматизации. Иногда на изменения нужно было потратить столько времени, что проще было отложить их на неопределённый срок. Но технический долг был не единственной проблемой.Постепенно стало очевидно, что архитектура плохо поддерживает дальнейшее развитие и расширение функциональности. Ниже расскажу с чем мы столкнулись. Зоны ответственности были размыты, а компоненты оставались тесно связаннымиВ монолитном репозитории у каждого сервиса, который тестирует команда автоматизаторов, были свои отдельные поддиректории в tests/ и в src/. Раньше это не вызывало серьёзных проблем — чаще всего команда работала внутри связки tests + src и редко пересекалась с другими. Но со временем появилось всё больше кросс‑сервисных задач. Нужно было менять API‑слой, дорабатывать транспорт и внедрять общие механизмы логирования или трассировки. И здесь различия в архитектурных подходах начали ярко проявляться:
Главная проблема была не в отдельных решениях, а в отсутствии четкой архитектурной модели:
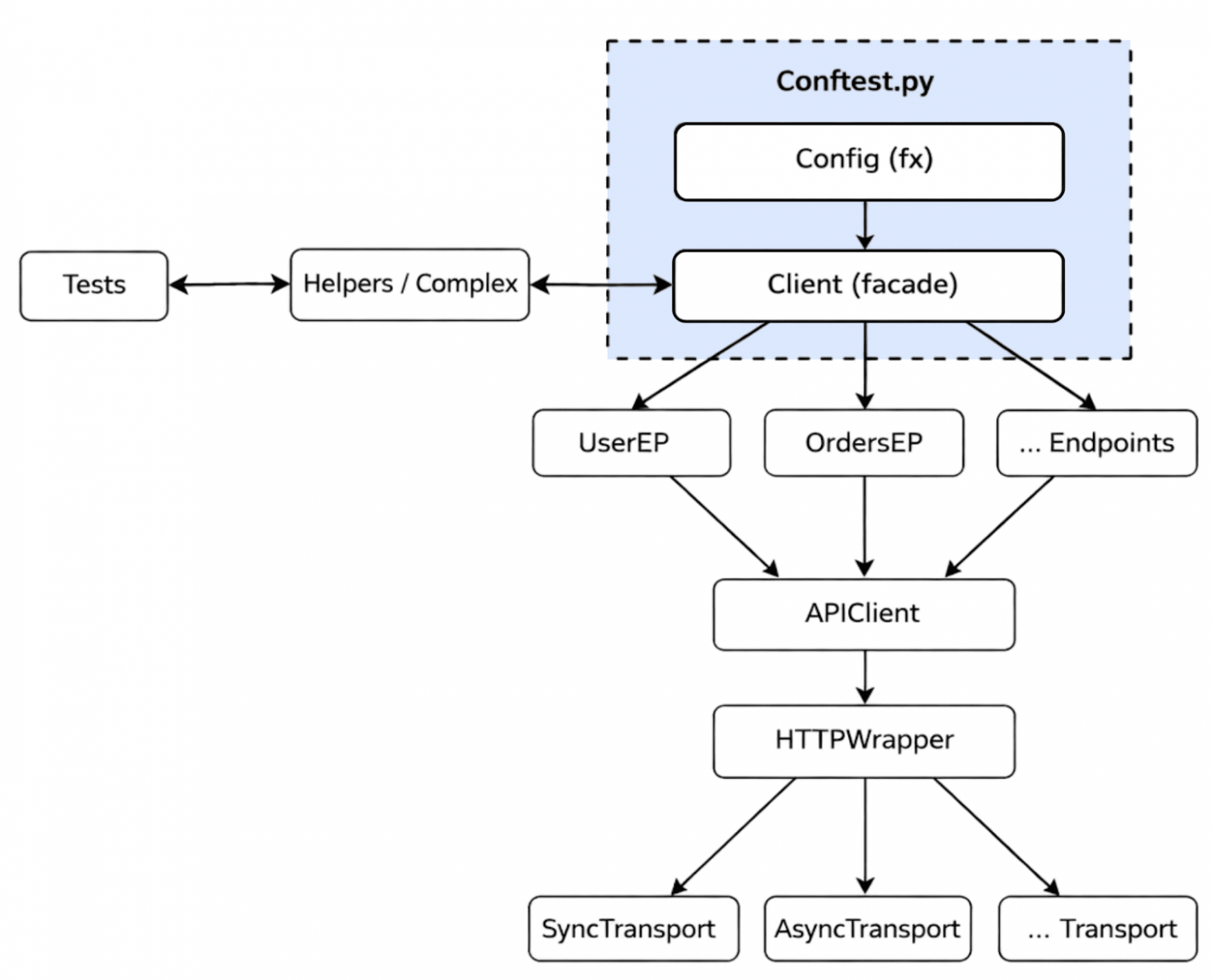
Любое изменение в одном месте могло неожиданно повлиять на другое. Это снижало прозрачность поведения системы, осложняло ревью и замедляло онбординг, что напрямую влияло на скорость выпуска новых фич. Стоимость поддержки росла, а технический долг накапливалсяИз‑за того, что мы откладывали часть задач из‑за ограничений архитектуры или чрезмерно трудоемкой реализации, постепенно накапливался технический долг. Каждый раз, когда архитектура не позволяла расширить функциональность, команды создавали локальные обходные решения. Например, делали собственные обёртки над HTTP‑вызовами или дублировали логику обработки ответов. Формально это помогало решать конкретные задачи, но фактически увеличивало вариативность поведения системы и усложняло её развитие. Это также увеличивало объём регрессионной проверки и повышало стоимость изменений. Проблема заключалась даже не в столько в кастомной реализации, сколько в её неконтролируемом размножении. Одни и те же технические задачи — ретраи, валидация статусов, обработка ошибок — реализовывались в разных частях кода по‑разному. Это приводило к дублированию, расхождению контрактов и постеенному размыванию архитектурных границ. В результате фреймворк становился не просто сложнее, а менее предсказуемым. В качестве показательного примера могу привести нашу попытку внедрить OpenTelemetry. Казалось бы, стандартная задача, но из‑за нескольких параллельных веток работы с HTTP с разными wrappers и разными точками входа единой точки расширения просто не было. В итоге внедрение превращалось не в рефакторинг, а в рискованное изменение, требующее затронуть множество независимых реализаций. А еще тестовым фреймворком ежедневно пользовалась вся команда автоматизации тестирования. Мы не могли просто остановить разработку или «заморозить» фреймворк на несколько дней ради масштабных архитектурных изменений. Это накладывало дополнительные ограничения и усложняло их реализацию. Архитектура плохо расширялась и затрудняла интеграцию новых инструментовПомимо описанных выше проблем, со временем проявились еще два аспекта. Первый — в фреймворк было сложно интегрировать сервисные SDK. Компания начала переходить на генерацию SDK для тестировщиков. Однако при попытке использовать их в фреймворке я столкнулся с тем, что для полноценной интеграции потребуется частичная переработка вспомогательного слоя и некоторых тестовых сюитов. В архитектуре не было понятного места, чтобы встроить такие абстракции. Второй аспект — мы начали использовать инструменты на базе AI. Код был разнородным, единые паттерны отсутствовали, а границы между слоями были размыты, поэтому AI‑инструменты работали нестабильно. Им было сложно определить, какие практики считать эталонными и каким архитектурным принципам следовать при генерации или модификации кода. В условиях, когда индустрия активно движется в сторону интеграции AI в повседневную разработку, такая несогласованность показывала, что у фреймворка в текущем состоянии нет будущего. В итоге мы всё чаще задавались вопросом: насколько текущая архитектура действительно готова к дальнейшему росту — как команды, так и инструментального стека? Как мы создали новую архитектуру тестового фреймворкаПрежде чем что‑либо переписывать, нам нужно было сформулировать, каким мы хотим видеть фреймворк и по каким принципам он должен работать. Я решил сформулировать базовые архитектурные принципы и зафиксировать их в виде схемы и документации. Мы начали обсуждать видение внутри команды SDET. Сначала это были неформальные разговоры: как разграничить ответственность слоёв, где должна заканчиваться доменная логика, как централизовать транспорт и конфигурацию. Постепенно появились первые наброски архитектурной схемы и понимание принципов новой модели. Первоначальная блок-схема архитектуры выглядела так:
Ключевым стало представление, что фреймворк должен быть:
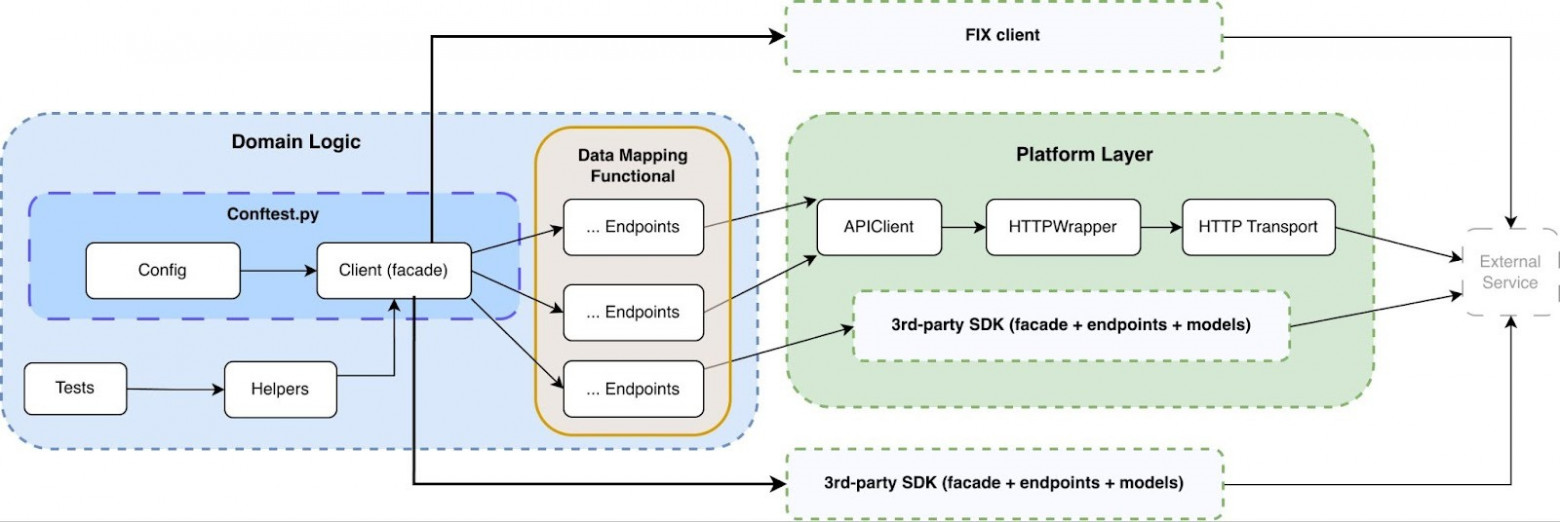
В один момент мой лид Владимир Смирнов принял решение о создании нового фреймворка. Мне было выделено время на то, чтобы спроектировать и реализовать архитектуру с нуля в отдельном репозитории. Стратегия была следующей: не переписывать существующий код постепенно внутри моно репозитория, а написать новую реализацию и постепенно мигрировать автотесты в новую структуру. В новой архитектуре была последовательность из четко разграниченных уровней ответственности. Каждый слой имел строго определенную зону ответственности и не нарушал границы соседних уровней. Основной принцип — направленные зависимости: зависимости были направлены сверху вниз, при этом каждый уровень зависел только от ближайшего нижнего уровня. Вот скриншот архитектуры, к которой мы пришли в итоге.
Для каждого слоя мы подготовили отдельную страницу документации с описанием его назначения, примерами реализации и ограничений:
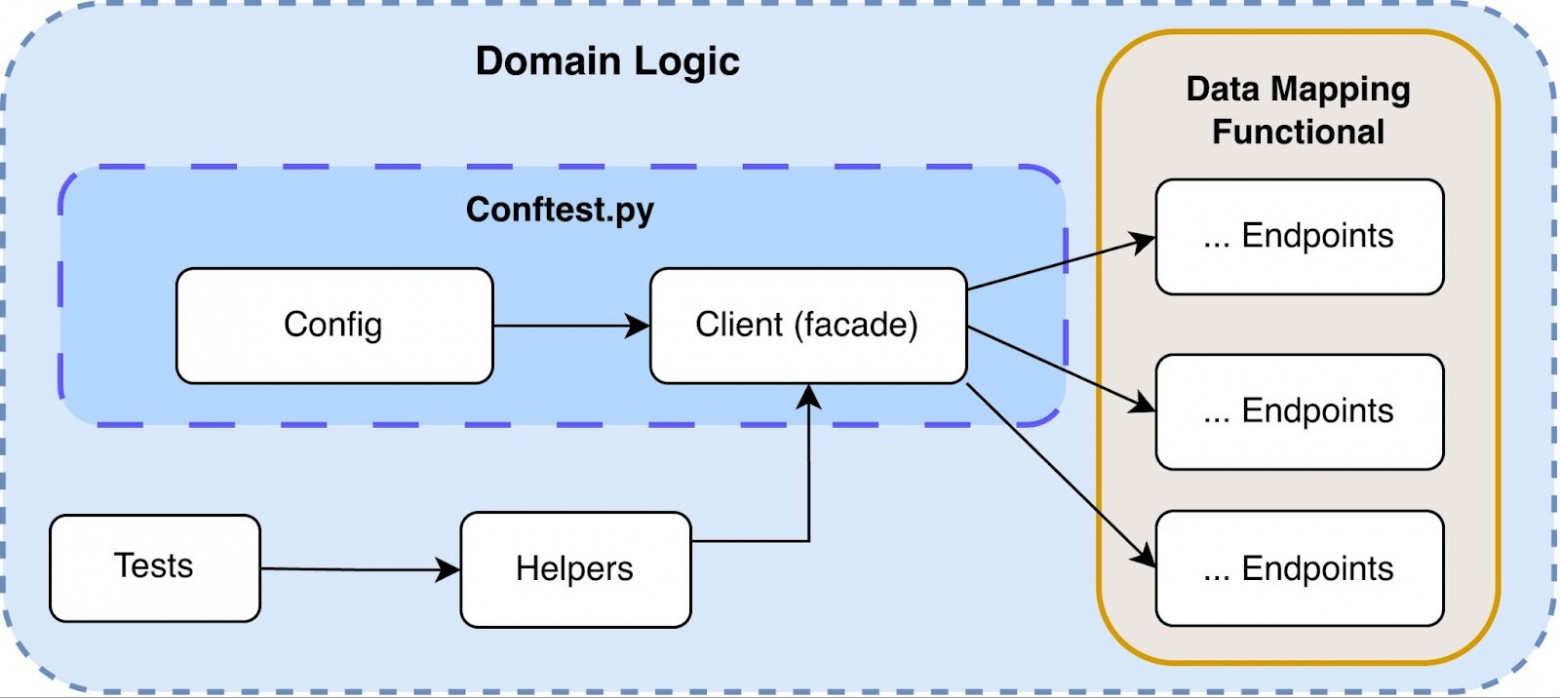
Такая декомпозиция позволила не только упорядочить код, но и формализовать ответственность каждой части системы. Слой доменной логики: где тесты выражают бизнес‑намеренияДоменный слой стал точкой входа для тестов и единственным местом описания поведения системы. В этой зоне находятся: tests, helpers, facade, endpoints и модели данных. Задача доменного слоя — описывать поведение системы в терминах бизнес‑операций, а не технических деталей. Тест не должен знать, какой транспорт используется, как формируется HTTP‑запрос или как обрабатываются заголовки.
Пример логической цепочки:
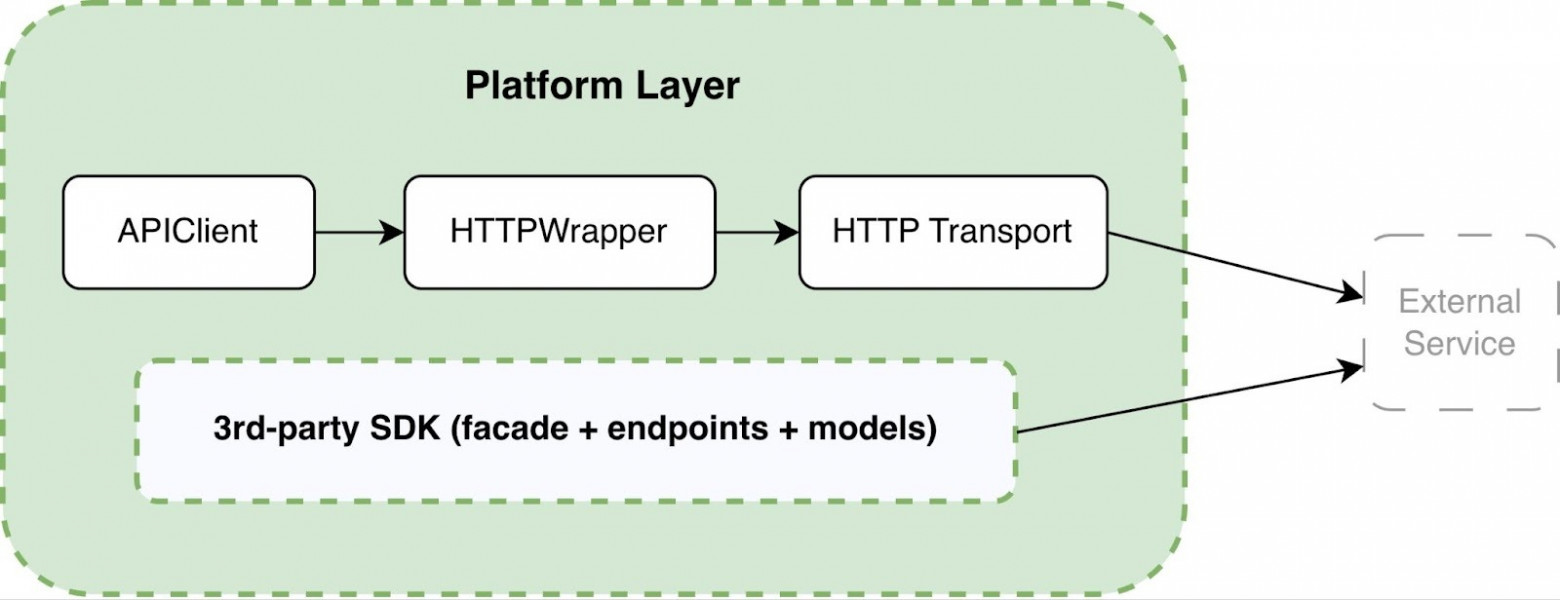
Facade играет ключевую роль. Он выступает как стабильный контракт к сервису в терминах доменной модели. Слой Endpoints отвечает за реализацию конкретных API‑операций, включая маппинг request/response через модели и взаимодействие с APIClient. При этом он не содержит бизнес‑логики или сценарной координации. Слой Models определяет строгие структуры данных (через Pydantic), обеспечивая типизированные контракты запросов и ответов, а также единый слой сериализации и валидации данных. Если меняется способ взаимодействия с API, тесты не должны переписываться — изменения изолируются внутри фасада или ниже. Такой подход позволил сделать тесты декларативными: они описывают что должно произойти, но не как именно это реализуется. На практике это вылилось в следующую структуру слоёв. FacadeFacade — это стабильный входной контракт к сервису в терминах доменной модели. Он агрегирует операции endpoints в связанный API и инкапсулирует детали вызова, параметры по умолчанию и базовые проверки. При изменении способа интеграции с сервисом модификации локализуются внутри фасада и не затрагивают тесты. EndpointsEndpoints реализуют конкретные API‑операции: формирование запроса, вызов APIClient, маппинг response в доменные модели. Этот слой отвечает за техническую корректность интеграции, но не содержит бизнес‑координации или сценарной логики. Он изолирует контракт внешнего сервиса от остальной системы. ModelsModels описывают строгие структуры данных через Pydantic и служат единым источником правды для request/response схем. Они обеспечивают типизацию, валидацию и централизованную сериализацию. Благодаря этому слой выше работает с предсказуемыми и проверенными объектами, а не с сырыми словарями. Prepare helpersPrepare helpers мы используем для генерации валидных payload, дефолтных конфигураций и подготовки тестовых сущностей. Они уменьшают дублирование и обеспечивают консистентность параметров между тестами. Их фокус — корректное формирование состояния до выполнения операции. Requests helpersRequests helpers инкапсулируют повторяющиеся паттерны вызовов фасада или endpoints. Они могут добавлять стандартные параметры, оборачивать вызовы дополнительными проверками или обрабатывать типовые сценарии. Это снижает связность тестов и делает их компактнее. Complex helpersComplex helpers агрегируют несколько доменных операций в один сценарный шаг. Они координируют последовательность действий и сохранют бизнес‑смысл на высоком уровне. Такой слой используется, когда сценарий повторяется в нескольких тестах и требует атомарной логической абстракции. Utils (в пределах доменного слоя)Utils содержат вспомогательные функции, которые не связаны напрямую с транспортом или инфраструктурой, но упрощаютработу с доменными объектами. Это могут быть преобразования, проверки инвариантов или утилиты сравнения. Их использование ограничено доменной областью, чтобы не размывать границы архитектуры. Платформенный слой: скрытие инфраструктурной сложностиПлатформенный слой отвечает за технические детали взаимодействия с внешними сервисами — всё то, о чём тесты и доменная логика вообще не должны задумываться. Он включает: API Client, HTTP Wrapper, HTTP Transport, интеграцию с внешними SDK и централизованную конфигурацию.
Задача этого уровня — полностью изолировать инфраструктурную сложность:
API ClientAPI Client — это адаптер между доменной моделью и транспортным уровнем. Он предоставляет Endpoints стабильный, предсказуемый контракт для выполнения операций, скрывает детали формирования HTTP‑вызова и конфигурации клиента. Этот слой централизует работу с базовым URL, авторизацией и общими параметрами запроса, чтобы верхние уровни не зависели от конкретной реализации транспорта. HTTP WrapperHTTP Wrapper инкапсулирует повторяющуюся инфраструктурную логику вокруг запроса. В нём сосредоточены retries, таймауты, базовое логирование, обработка ошибок и другие кросс‑срезовые механизмы. Благодаря этому поведение сетевого взаимодействия стандартизировано и не дублируется в каждом endpoint. HTTP TransportHTTP Transport отвечает исключительно за отправку запроса и получение ответа. Он не содержит бизнес‑логики и не координирует сценарии — его зона ответственности ограничена низкоуровневым взаимодействием с HTTP‑клиентом (например, httpx). Такое разделение делает транспорт заменяемым и исключает влияние изменений на остальные уровни. Такое разделение дало нам то, чего раньше не хватало — контроль и прозрачность поведения. Мы получили единую точку расширения — например, для подключения OpenTelemetry, возможность внедрять middleware без каскадных изменений в доменной логике и понятный механизм интеграции 3rd‑party SDK без вмешательства в тестовый слой. В результате платформенный слой перестал «просачиваться» вверх. Он стал изолированным, управляемым и при необходимости заменяемым компонентом. Теперь мы можем менять транспорт или добавлять middleware без каскадных правок по всему проекту. Но стоит помнить, что архитектура требует дисциплины и код‑ревью, иначе слои снова начинают смешиваться. Интеграция SDK и внешних клиентовОтдельного внимания заслуживает интеграция 3rd‑party SDK и специализированных клиентов — например, FIX client. В новой архитектуре мы стали рассматривать SDK как альтернативную реализацию уровня взаимодействия с внешним сервисом. Они могут либо подключаться через платформенный слой, либо напрямую использоваться в строго ограниченном контексте. Это позволило нам постепенно переходить на автогенерируемые SDK, не переписывать автотесты, и по возможности избегать дублирования логики. В результате новая архитектура перестала быть набором решений, сформированных исторически. Она стала формальной моделью с определёнными правилами зависимости и расширения. Именно это позволило нам двигаться дальше — к миграции тестов и постепенному выводу старого фреймворка из эксплуатации. Ключевые возможности нового фреймворкаНа момент написания статьи мы находимся в стадии постепенной миграции со старого фреймворка на новый и активного внедрения AI для написания автотестов. Говорить о количественных результатах пока рано — часть тестов всё ещё работает в прежней архитектуре.Тем не менее, уже на этапе проектирования и первых миграций стало понятно: новая архитектура упростила интеграцию SDK, сделала работу AI‑инструментов более предсказуемой за счёт чётких границ слоев и позволила добавлять новую функциональность без затрагивания несвязанных частей фреймворка. Я постарался сохранить привычную модель написания автотестов, чтобы переход для команды оставался эволюционным и не был резким. Формализация доменных шаговПроцесс написания автотестов всё больше сводится к описанию сценариев тестирования. Во время работы у команды тестировщиков постепенно накапливается всё больше специализированных функций — хелперов или шагов, которые затем специалисты снова используют в других тестах. Это естественная эволюция любого зрелого тестового набора: тестировщик пишет конкретный сценарий, в нем появляется повторяющийся фрагмент, специалист выносит его в отдельную функцию, и так шаг за шагом формирует библиотеку доменных операций. Мы и раньше старались придерживаться подобного подхода: выносили повторяющийся код, агрегировали логику, инкапсулировали шаги. Но теперь мы пошли дальше и формализовали этот процесс:
Другими словами, мы превратили стихийно возникающую практику в управляемый архитектурный механизм.В результате переиспользование стало не просто удобным, а предсказуемым. А библиотека шагов — не набором случайных утилит, а осознанным слоем, встроенным в общую архитектуру фреймворка. Минимальный пример теста можно увидеть ниже. Декларативная валидация через кастомный декоратор @response_mappingЕсли предыдущий текст отвечает за уровень сценариев, то следующий механизм нового фреймворка помогает формализовать контракты через декларативную валидацию HTTP‑ответов. В старом подходе проверки HTTP‑статусов не имели фиксированного уровня ответственности. Чаще всего они располагались в helper‑функциях, но со временем начали появляться и в самих тестах, и на уровне API‑запросов. Формально такие проверки решали одну и ту же задачу, но были реализованы по‑разному. В результате логика валидации постепенно дублировалась и начинала «расползаться» по архитектуре. Количество таких проверок росло, их поведение становилось менее предсказуемым, а сопровождение — сложнее. Кроме того, в разных местах одни и те же статус‑коды трактовались по‑разному, что фактически размывало контракт API. При анализе кода я регулярно сталкивался с одинаковыми проверками, разбросанными по разным слоям. Поэтому я решил вынести валидацию контрактов на уровень Endpoints и формализовать ее через декоратор. В новом подходе валидация происходит на уровне Endpoints. На каждый метод класса Endpoint добавляется декоратор @response_mapping, который принимает в виде аргументов набор позитивных и негативных статус‑кодов с моделями данных для этих ответов. Статус‑коды и модели данных мы берем из swagger спецификации и сервиса. Декоратор автоматически:
Таким образом, контракт API перестаёт быть разрозненной проверкой в тестах и становится частью архитектуры клиента. Это снижает вероятность расхождений и упрощает сопровождение интеграций. Единый паттерн фикстурВсе клиентские фикстуры в новом фреймворке находятся в папке fixtures/ и следуют единому шаблону. В данной папке я ввел разделение на public и private клиенты. В conftest.py‑файле мы потом просто подключаем набор фикстур как плагин pytest_plugins = («fixtures.clients»,) Данная стандартизация кажется мелочью до тех пор, пока не сталкиваешься с онбордингом нового инженера. Единая точка входа и четкое понимание, как и откуда берутся клиенты, сильно помогает в понимании того, как запускаются тесты. Внутри фикстуры происходит создание фасад‑клиента, инкапсулируется конфигурация и происходит управление жизненным циклом. Пример типового паттерна: Одинаковая структура упрощает написание и контроль за кодом сервисов. Консистентность снижает когнитивную нагрузку. И это напрямую влияет на скорость разработки. Предсказуемость на уровне сценариев и контрактов сохраняется и на уровне инфраструктуры. AI и автогенерацияОтдельно я заранее продумывал, как новая архитектура будет взаимодействовать с AI‑инструментами. На данный момент мы используем в репозитории трехуровневую систему документации:
Файл Claude.md выступает как набор ограничений для Claude Code. В нем прописано, каких принципов придерживаться при написании кода, какие файлы документации и в каких случаях стоит смотреть, кастомные правила, которые стоит применять в разных ситуациях и подобные вещи. Теперь, когда инженер использует ИИ‑инструмент, он может легко указать ему нужный контекст — просто отправить ссылку на нужный файл документации. Когда архитектура формализована и задокументирована, AI начинает работать в разы лучше. Поэтому полная и хорошо структурированная документация заметно влияет на качество генерируемого кода, code review и качество подсказок от ИИ по коду. В условиях большого моно репозитория это начинает влиять не меньше, чем качество архитектуры. ЗаключениеМы создавали новую архитектуру как устойчивую основу для дальнейшего развития фреймворка. Сейчас мы дорабатываем, обсуждаем внутри команды и постепенно формализуем несколько направлений:
Параллельно продолжается миграция тестов. Мы уже начали переносить два сервиса в новую архитектуру. Я продолжаю собирать обратную связь, дорабатывать документацию и корректировать архитектуру по мере использования. Это помогает стабилизировать реализацию и проверить архитектурные решения на практике. Архитектура начинает жить только тогда, когда ей пользуются. Новая модель упростила добавление функциональности, сделала интеграцию SDK предсказуемой и снизила связанность между компонентами. Но ключевым фактором для нас стало активное использование AI: чёткие границы слоев, единые паттерны и формализованные контракты позволяют AI‑инструментам стабильнее генерировать автотесты и модифицировать существующий код. Это ускоряет написание тестов, снижает стоимость изменений и делает развитие автоматизации более устойчивым. |