Что пишут в блогах
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026
- Как нагрузочное тестирование защищает бизнес от убытков?
- Исследовательское тестирование и UX‑аудит для интернет-магазина
- Юзабилити‑тестирование без розовых очков: почему идеальный функционал не спасёт от провала?
- А ваши тестировщики защищают ваш продукт и компанию от миллионных штрафов?
- TechWriter Days 3. Как это было
- Ричард Румельт. Взлом стратегии.
- Должны ли разработчики тестировать свой код
- Мои 12 недель в году. Часть 33 (вышла книга по SQL, закончила книгу про ИИ)
- Почему SaaS падает при росте нагрузки?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Тестирование производительности: JMeter 5Начало: 29 мая 2026
-
Bash: инструменты тестировщикаНачало: 4 июня 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 4 июня 2026
-
Docker: инструменты тестировщикаНачало: 4 июня 2026
-
Git: инструменты тестировщикаНачало: 4 июня 2026
-
Python для начинающихНачало: 4 июня 2026
-
Азбука ИТНачало: 4 июня 2026
-
SQL: Инструменты тестировщикаНачало: 4 июня 2026
-
Инженер по тестированию программного обеспеченияНачало: 4 июня 2026
-
Практикум по тест-дизайну 2.0Начало: 5 июня 2026
-
Аудит и оптимизация процессов тестированияНачало: 5 июня 2026
-
Логи как инструмент тестировщикаНачало: 8 июня 2026
-
Тестирование REST APIНачало: 8 июня 2026
-
Техники локализации плавающих дефектовНачало: 8 июня 2026
-
Применение ChatGPT в тестированииНачало: 11 июня 2026
-
Школа для начинающих тестировщиковНачало: 11 июня 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 11 июня 2026
-
Регулярные выражения в тестированииНачало: 11 июня 2026
-
Charles Proxy как инструмент тестировщикаНачало: 11 июня 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 11 июня 2026
-
Тестирование GraphQL APIНачало: 11 июня 2026
-
Программирование на Java для тестировщиковНачало: 12 июня 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 16 июня 2026
-
Автоматизация тестирования REST API на JavaНачало: 17 июня 2026
-
Тестирование безопасностиНачало: 17 июня 2026
-
Автоматизация тестирования REST API на PythonНачало: 17 июня 2026
-
Тестирование мобильных приложений 2.0Начало: 17 июня 2026
-
Автоматизация функционального тестированияНачало: 19 июня 2026
-
Школа тест-менеджеров v. 2.0Начало: 24 июня 2026
-
Тестирование веб-приложений 2.0Начало: 26 июня 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 29 июня 2026
-
Школа Тест-АналитикаНачало: 1 июля 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
| Анализ тестов — как выкидывать лишнее |
| 28.06.2022 00:00 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Анализ тестов — это выкидывание лишнего из вашего чек-листа. Работа из серии «сесть и подумать»:
Было бы здорово дать некий алгоритм, который поможет всегда и везде, но нет, увы. Универсальная фраза здесь только «сесть и ПОДУМАТЬ». А самое главное: «вместе с водой не выплеснуть ребенка». Убирайте тесты аккуратно, особенно в первые годы работы. Возможно, выкинутое было отнюдь не лишним...
Но общий принцип анализа примерно такой:
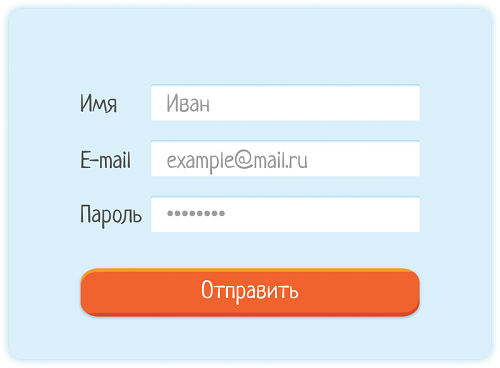
Рассмотрим каждый пункт по отдельности. Содержание1. Объединить позитивные тестыЗа одну проверку можно многое успеть. И если мы хотим ужать количество тестов, то можно проверить несколько позитивных за один раз. Проще всего это сделать, когда надо проверить сразу несколько полей. Но мы рассмотрим разные варианты. 1.1. Разные поляВозьмем для примера форму регистрации. Предположим, на ней три поля поля: имя, email, пароль.
Для каждого поля мы расписываем проверки, которые надо провести. Например:
Вот у нас есть по 7 проверок на каждое поле. Проверки можно проводить по-разному: 1. Сосредоточиться на одном параметре и варьировать именно его. Остальные оставлять неизменными (чтобы не напрягать мозг, как бы еще их проверить). Например, регистрируем свой емейл и пароль «12345», так как точно уверены в их валидности. Меняем только имя. Потом фиксируем имя и пароль, меняем емейл. И, наконец, меняем только пароль. Получается 7 + 7 + 7 = 21 тест
2. Объединить проверки. Все равно всю форму заполнять, так будем заполнять ее по разному:
Итого получается 7 тестов вместо 21.
Важно не перестараться — если напихивать в один тест кучу всего, баг по нему локализовать будет сложно. Да и покрытие тестами оценить тоже не очень. 1.2. Одно полеВ рамках тестирования одного поля тоже можно совместить разные проверки. Например, длину поля + регистр + алфавит.
1.3. Разные параметрыМне очень не хочется, чтобы вы думали, что объединять тесты можно только в больших формах ввода на N полей и больше это нигде работать не будет. Будет! Мы можем объединять проверки на разные состояния объектов или разные параметры:
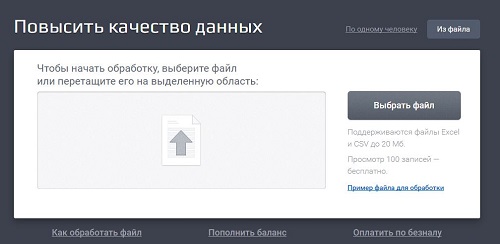
Например, в Дадате есть возможность загружать файлы в систему. На форме указаны ограничения: «Поддерживаются файлы Excel и CSV до 20 Мб».
Одним тестом мы можем проверить формат Excel и небольшой размер файла (несколько кб), другим — CSV и граничное значение 20 Мб. А потом поварьировать другие величины, скажем, проверить загрузку одной строки данных, а формат выбрать CSV с другим разделителем. 1.4. Итого по объединениюОбъединение проверок — это здорово в условиях ограниченного времени. Они сильно помогают, когда на выполнение одного теста тратится много времени по тем или иным причинам (приходится подключаться к дохлой виртуалке, где все тормозит; проходить длинную процедуру регистрации на сайте итд). Однако у них есть и минусы. Например, если что-то где-то пошло не так и программа сломалась, сложно сделать вывод: а где именно? Когда у нас всегда одинаковое имя и пароль, меняется только эл адрес, то все понятно: случился баг, проблема в емейле. А вот если мы в один тест запихали 10 разных проверок, придется потратить время на локализацию. Плюсы + Меньше тестов, больше покрытия! Минусы - Сложно составить тесты - Сложно красиво это описать - Сложно держать в голове - А если вдруг баг? Сложнее локализовывать Это не значит, что теперь вообще нельзя объединять тесты, вовсе нет! Просто помните о минусах. И в каждом случае думайте, что принесет больше выгоды: объединить проверки или оставить как есть. Если «сложно красиво описать» кажется вам надуманной проблемой, то вам просто повезло не сталкиваться с последствиями) При этом учтите, что объединять надо только позитив. Если объединить негативные проверки, нельзя четко ответить на вопрос, правда ли система умеет реагировать на каждую ошибку в отдельности. Может, она обрабатывает лишь одну из двух и вам просто повезло её увидеть. Объединяйте позитив, а негатив проверяйте отдельно, оставляя другие параметры «точно хорошими». 2. Выкинуть дублиТут может быть два варианта:
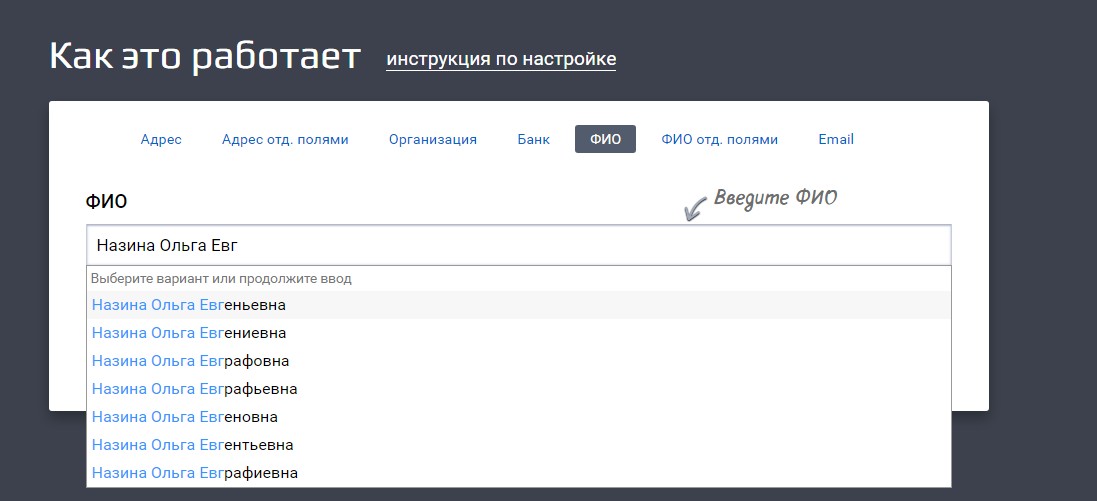
Но чтобы что-то выкидывать, надо сделать пример "откуда выкидывать" Пример для выкидыванияНа сайте Дадаты есть подсказки по ФИО:
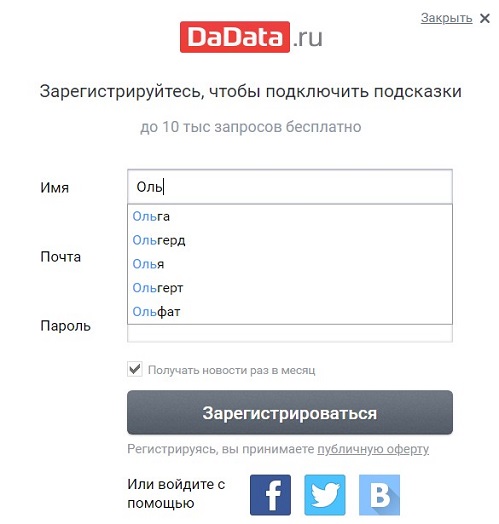
Они же подключены во время регистрации:
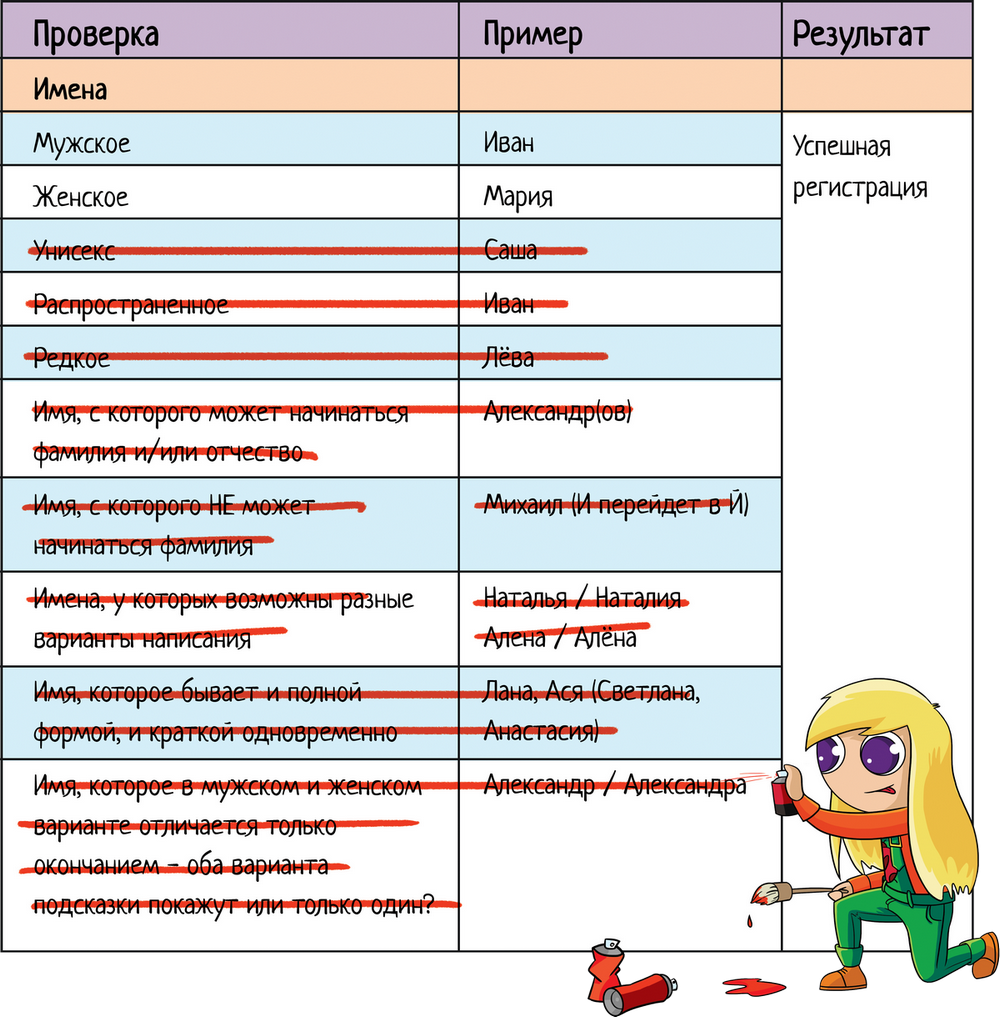
Вот как раз для поля «Имя» при регистрации мы и напишем чек-лист. Что важно в подсказках? Они помогают вводить данные быстрее и без ошибок — в длинном имени опечататься очень легко, а уж пока запишешь адрес... Итак, важно проверить:
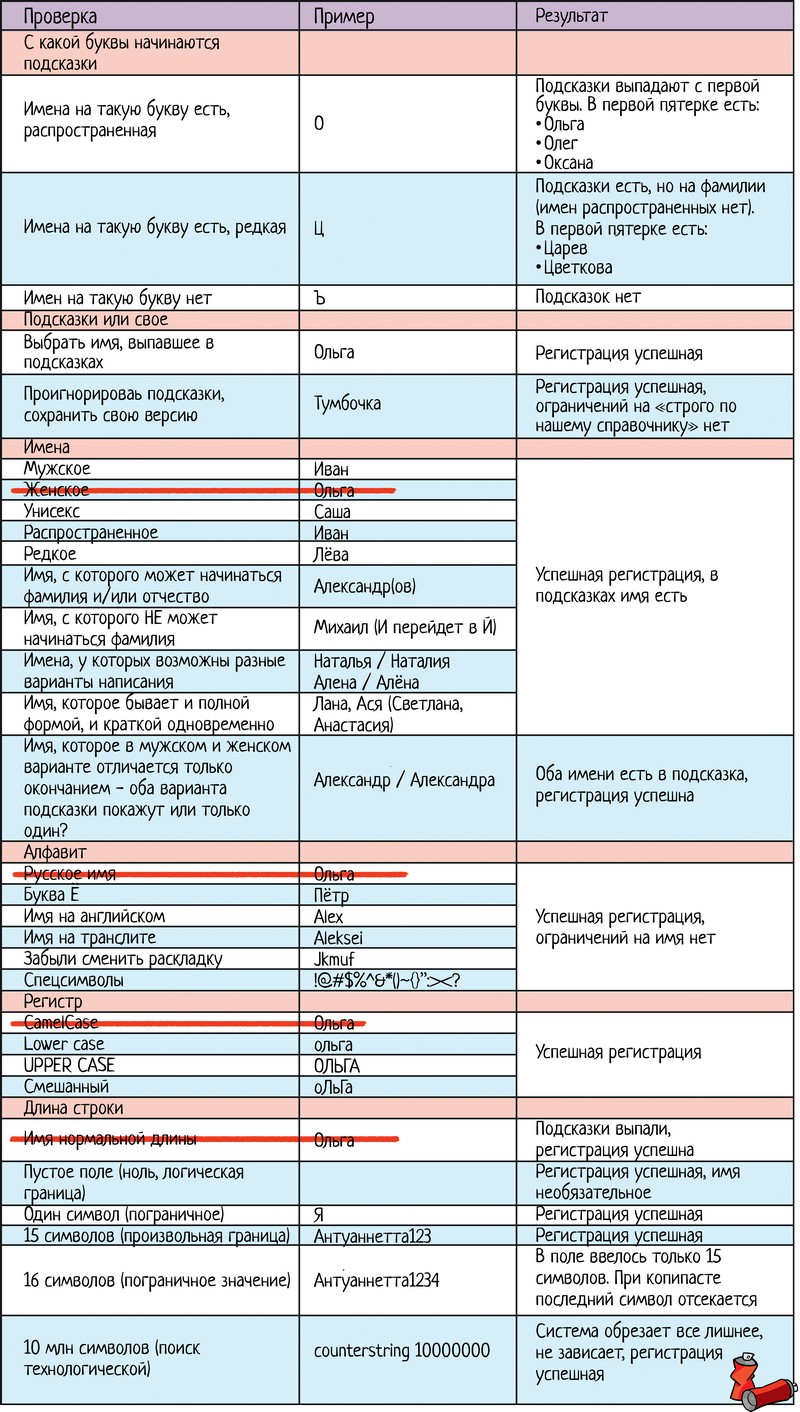
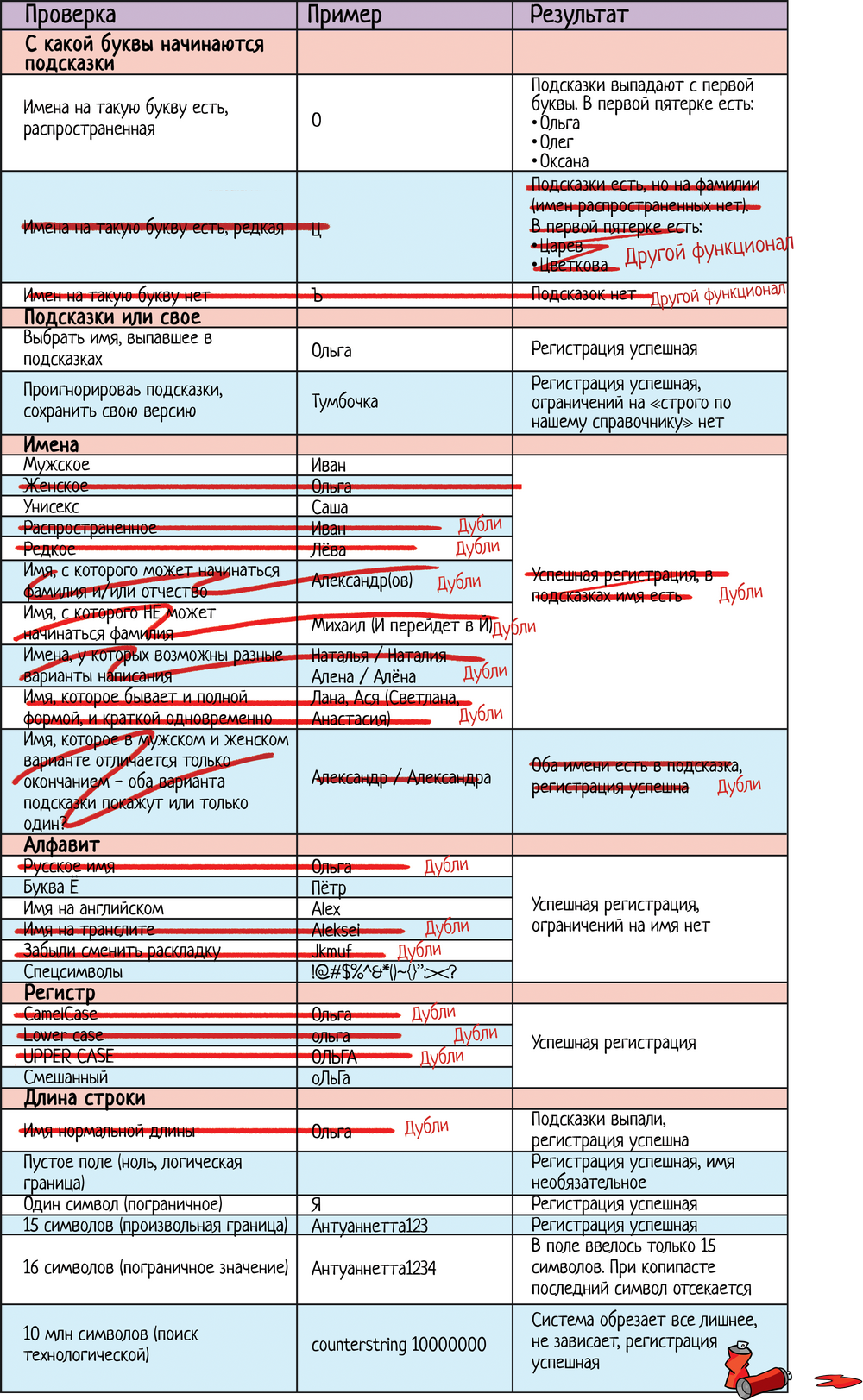
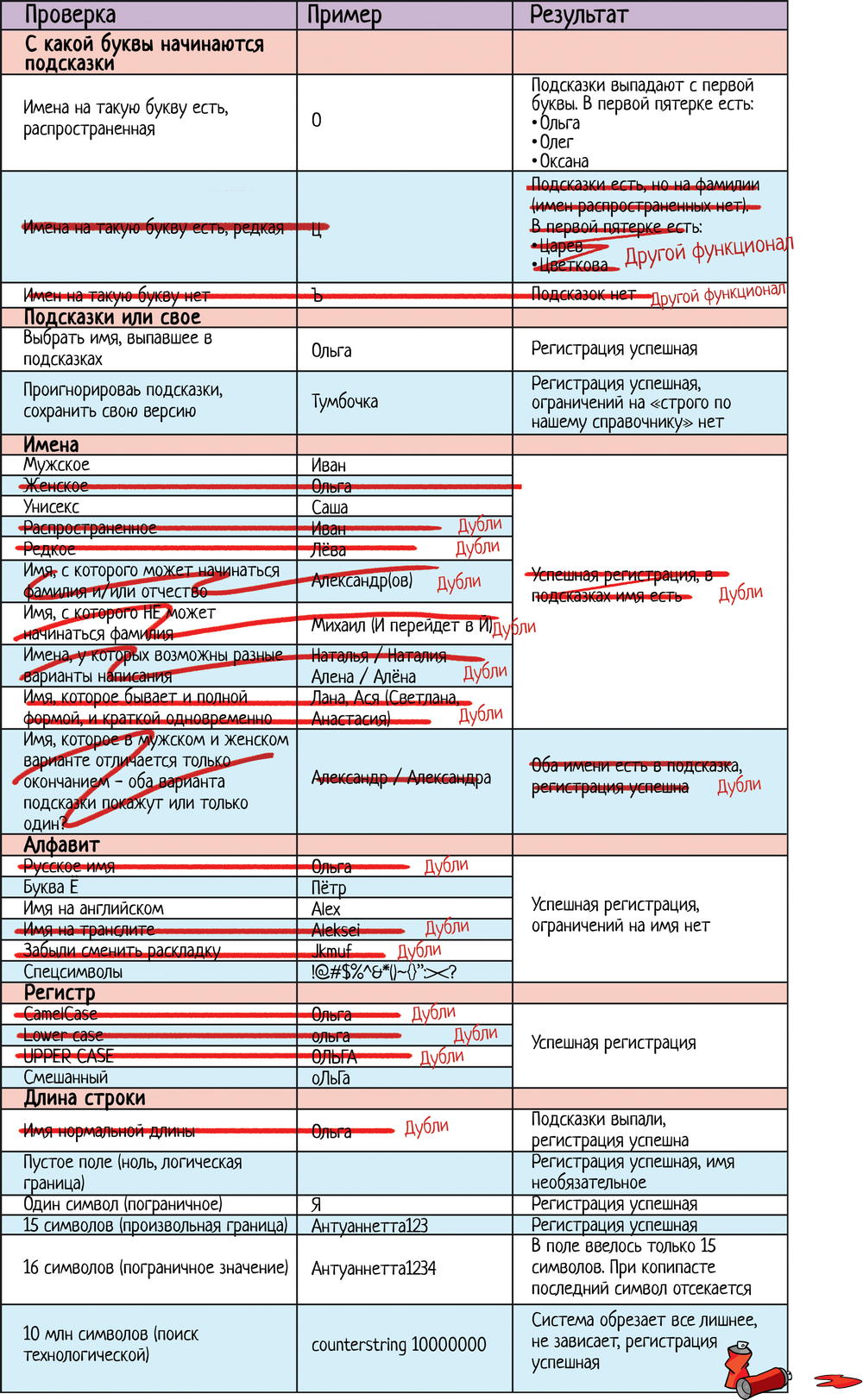
Итак, начнем! Не знаю, какое ограничение на имя будет в дадате, когда вы будете читать эту статью. Поэтому предположим, что оно ограничено 15 символами. Пишем чек-лист: ЧЛ 1.1. Чек-лист для поля «Имя» при регистрации
Чек-лист накидали, а теперь выкинем лишнее! 2.1. Фантазия разгуляласьНа тему разгулявшейся фантазии обратимся к той части чек-листа, где мы перечисляли разные варианты тестирования имен: ЧЛ 1. Чек-лист для поля «Имя» при регистрации
Если мы тестируем подсказки, то это все очень правильные тесты. Но что, если мы тестируем обычную систему, где разработчик просто добавил текстовое поле, без каких-либо ограничений? Так то разных имен можно придумать хоть сотню, но на самом деле нам не надо это все проверять. И если мы тестируем просто поле, то все лишнее можно смело выкидывать.
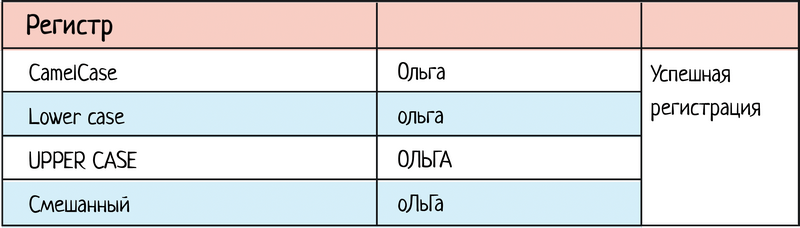
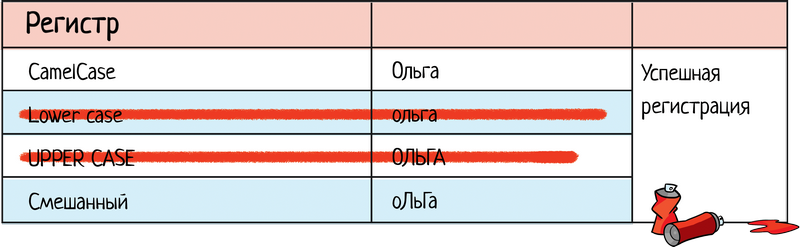
При тестировании регистра тоже можно сократить количество проверок:
Что мы хотим реально проверить? Что система не зависит от регистра. Поэтому на самом деле обычно хватает смешанной проверки: оЛьГа проверили и норм. А чистый КАПС или нижний уже не нужны:
При этом проверка зависимости от регистра очень важна. Особенно когда речь идет про поиск. Зависит ли поиск от регистра или надо вводить «четко как хранится в системе»? Проверить надо, писать десяток тестов — нет. 2.2. Я это уже проверялКогда мы накидываем варианты проверок, то даем волю фантазии. А потом смотрим на итоговый чек-лист и видим, что часть тестов повторяется. Вот, например, свое имя «Ольга» я проверяю несколько раз в разных блоках:
ЧЛ 1. Чек-лист для поля «Имя» при регистрации
Что это значит? Что можно оставить только один тест, а остальные — выкинуть!
И это на самом деле самое простое, но самое приятное, что мы можем сделать при анализе тестов. На это способен любой новичок. Причем начинающие некоторые дубли видят заранее. Вот, например, мои студенты обычно еще до лекции с анализом тестов задаются вопросом: — Зачем в разделе «длина строки» проверять нормальную длину? Мы же ее уже тестировали ранее, не получается ли дубля?
Получается! И здорово, когда ребята это сразу подмечают. Но в школе я их прошу пока оставить дубли, потому что следующая лекция про анализ и домашнее задание как раз «возьмите свой чек-лист и выкиньте лишнее». Мы работаем в Ситечке и в рамках анализа просим не удалять проверки физически, а поставить ненужным самый низкий приоритет. Сразу видно, сколько тестов выкинуто — это правда круто! Почему я прошу оставлять дубли? Все очень просто:
Фактически набросать первую версию чек-листа — это тот же брейншторм (Brainstorm — мозговой штурм), только на одного человека.
Вы сидите и генерите идеи. И если после каждой мысли останавливаться и думать «а это адекватный тест? А не проверял ли я это раньше?», то никакого полета фантазии не будет. На этапе генерации идей важно не ограничивать себя: — Выбор из подсказок? Можно выбрать. А что, если выбрать, потом стереть и ввести повторно и снова выбрать? Или стереть и ввести свое? Или выбрать и заменить потом окончание? — Алфавит? Русский, английский, русский, забыв переключить раскладку, иероглифы какие-нить... — Длина? Так, нормальная, ноль, один, граница произвольная, пограничное, поиск технологической... — Регистр? Обычный, верхний, нижний, перемешали... — ... Вот что приходит в голову, то и записываем. А уже потом начинаем отсеивать. Так, это я уже проверил, это проверил, и это. А это вообще космолет, сначала позитивные тесты. Начинайте именно так! Это очень важно особенно на начальных стадиях, пока вы в тестировании недавно, нет накопленного опыта, где вообще бывают баги, мало идей... Если еще и их контролировать, совсем ничего не придумаете. И опять же по опыту студентов, дублирование замечают заранее только в длине строки. Хотя в их чек-листах есть и другие =))) Поэтому сначала записываем, потом вычеркиваем.
Сделаете так 5 раз, 10 — уже поймете, где тесты обычно дублируются и исходно будете НЕ писать заведомо лишние проверки.
Пример: длина строки для разных алфавитов Ещё из опыта студентов. Самый частый кейс дублей — 15 млн символов русских, повторить для английских, для цифр, для спецсимволов и т.д. Когда технологическую границу ищем. А иногда вообще блок с длиной дублируется:
В целом, тут есть здравое зерно. Если у нас ограничение на 20 символов, то вполне может быть такое, что разработчик поставил ограничение в байтах. В итоге у нас 20 символов латиницей или цифр пройдут, а вот 20 русских символов не сохранятся...
Тут важно что? Важно понимание того, что такое кодировки, какие они бывают... Но для уровня новичка можно ориентироваться примерно так:
Цифры как латиница, тестировать и то, и другое явно смысла нет. Проверить произвольную границу 20 можно дважды: на русском и английском языке (вдруг они правда отличаются?). А вот все остальные проверки дублировать не надо.
0 символов — оно и в Африке ноль символов. Пограничное один — проверьте позитивным тестом, какие символы или цифры вводит пользователь, не пытающийся сломать систему? А поиск технологической... Если вы знаете четко, что кириллица занимает больше места, то ищем границу через русские символы. Дублировать тесты под цифры или латиницу уже не надо. Если разницы в произвольной границе не было, то пофиг, на чем конкретно вводить 100 млн данных. Помните — длина строки и разные алфавиты: разные классы эквивалентности, разные группы тестов. Не надо их дублировать один внутри другого. Максимум, что стоит проверить — это произвольную границу по ТЗ. На русском и английском. 3. Не тестировать один функционал 10 разКогда вы тыкаете на кнопочки в интерфейсе, внутри программы задействуются те или иные участки кода. Хороший код — с грамотной структурой и переиспользованием вместо копипасты. Это значит, что разработчик пишет функционал в одном месте, а потом просто дергает вызов этого функционала из разных мест интерфейса. Вот, допустим, поиск по каком-то сайте. Вы открываете главную — справа вверху есть строка с поиском. Вы переходите на карточку красного платьюшка — вверху осталась та же строка. Вы переходите на карточку синих брючек — строка поиска все еще есть. Внимание, вопрос — нужно ли тестировать эту строку на каждой странице отдельно, снова и снова?
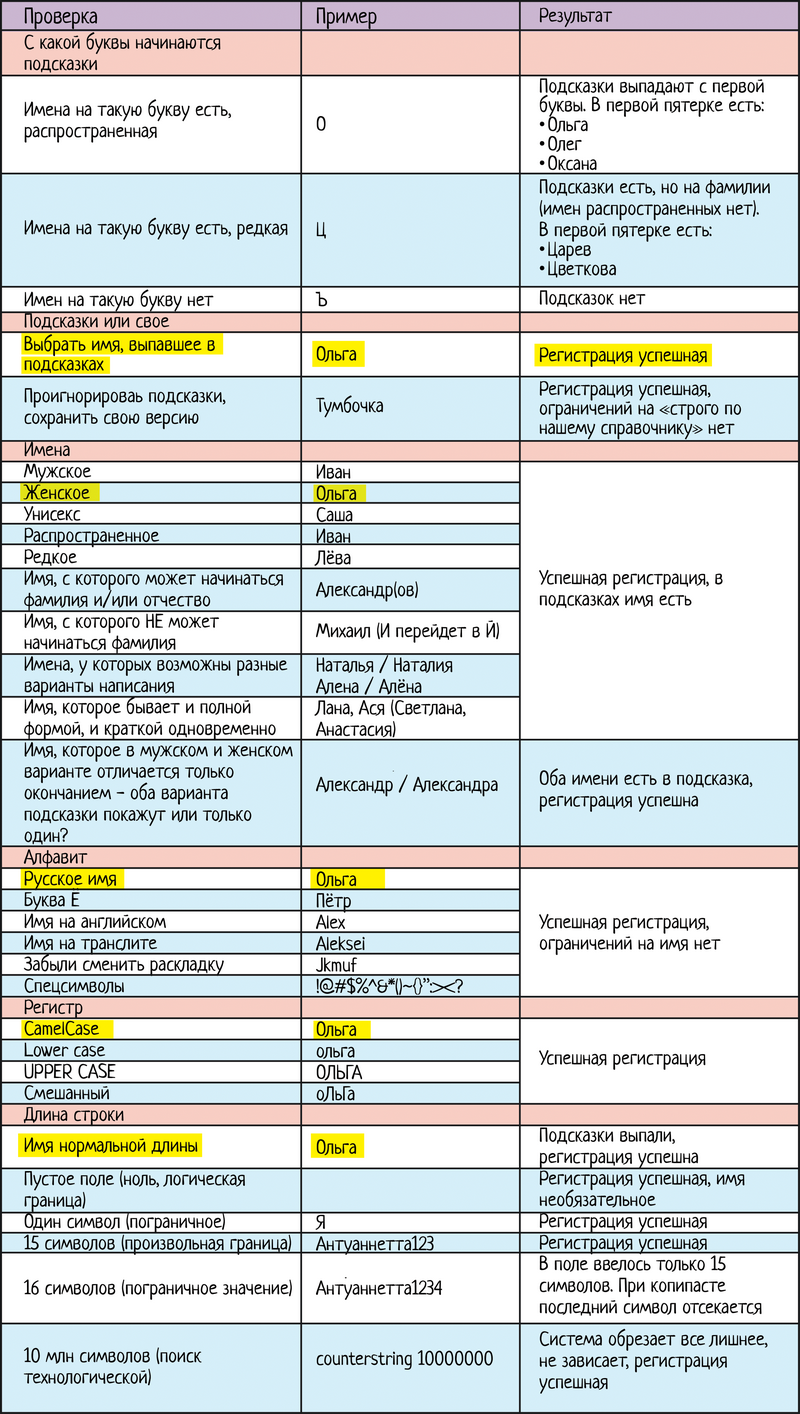
Разумеется, нет. Мы понимаем, что это один и тот же функционал, который просто привязали к кнопке с лупой. Тыкаешь на лупу — запускается код поиска. И неважно, где эта лупа была, на главной, в результатах прошлого поиска или на карточке конкретного товара. Мы помним про тест-дизайн, про классы эквивалентности. Про пример с калькулятором, где можно писать сотни миллионов тестов только на одно лишь сложение, если не использовать классы эквивалентности. Так и тут: если на сайте 10 000 товаров, то тестировать раздел навигации на каждой странице будет стоить дорого, а толку не принесет. Это простой пример. Мы видим, что на каждой странице у нас форма выглядит одинаково, никуда не пропадает, не меняется → так мы понимаем, что это один и тот же функционал, который не надо тестировать заново. Но ведь бывают и случаи сложнее. Когда функционал один, но выглядит по-разному. И тут начинается ступор и попытки протестировать одно и то же несколько раз. Хотите примеров? Подсказки при регистрацииВернемся к нашему чек-листу регистрации в Дадате. В разделе разгулявшейся фантазии мы говорили о том, что чек-лист хорош для тестирования подсказок, но для простого поля с именем это слишком много. Но ведь у нас есть подсказки! Когда начинаем вбивать имя, мы видим список подсказок. Значит, их надо тестировать. Да? Или нет? Нет, не надо. Подсказки — это отдельный функционал, который просто привязывается к конкретной формочке графического интерфейса. Поэтому при тестировании разделяем функционал. В чек-лист подсказок по ФИО вносим все наши мудрые идеи про «А если на такое имя может начинаться отчество? А если у имени возможны два написания, увижу ли оба? А если унисекс, какие увижу фамилии?...». А вот в чек-листе регистрации нам сам функционал подсказок исследовать уже НЕ нужно, мы предполагаем, что он уже проверен. Наша задача состоит лишь в том, чтобы проверить, что подсказки к имени подключены. И всё! Если начинаем ввод и подсказка выпадает — всё ок. Дальше тестируем как простую строку.
Итого после выкидывания всего лишнего что же у нас остается?
Перепишем результат ЧЛ 1.2. Чек-лист для поля «Имя» при регистрации
Сильно меньше тестов, не правда ли? Зная, что поле с именем — простая строка без доп проверок, к которой прикручены подсказки, мы проверяем:
Конечно, бывают такие разработчики, которые все делают тяп-ляп и вместо переиспользования функционала они его дублируют. Что приводит к внезапным для нас ошибкам. Обычно такое встречается на фрилансе, там не заморачиваются на чистоте кода, а просто делают по ТЗ. У меня была такая ситуация: в системе можно создать карточку товара из двух мест: на главной странице и в разделе товаров. Выглядят эти кнопки одинаково и одинаково же работают. Казалось бы, проверили одну → вторая тоже будет работать. Но я сталкивалась с багами типа «на главной работает, в разделе товаров эксепшен (ошибка)». И тут есть два варианта этой ошибки:
По умолчанию мы считаем своих разработчиков адекватными людьми, за которыми не надо перетестировать одно и то же 10 раз подряд. Если в ТЗ написано, что «вот тут тот же самый функционал», то принимаем это на веру: нам нужно буквально 1-2 теста, убедиться, что функционал сюда подключен, и все. Но во избежание эффекта пестицида мы каждый прогон ручных тестов немного варьируем свои проверки. А заодно можем тестировать чек-лист одного функционала сначала в одном месте, потом в другом. И если замечаем разницу и понимаем, что разработчик у нас «косячный», тогда уже придется увеличивать скоуп работ. Но по умолчанию один функционал мы проверяем один раз.
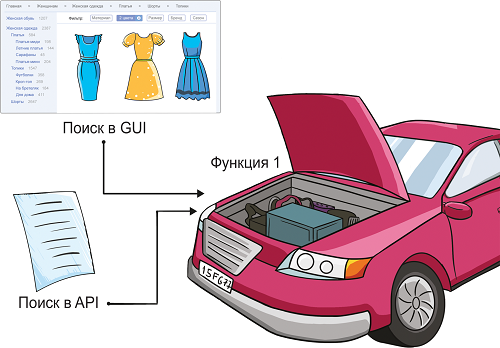
Интерфейс и API Самый распространенный пример переиспользования функционала — это когда его можно проверить вручную, потыкав на кнопочки в интерфейсе + есть некий API-метод (SOAP, REST…) На самом деле, если заглянуть под капот, то мы поймем, что в интерфейсе на самом деле дергается тот же самый код, зачастую тот самый API-метод. Что делаем в таких случаях, уже понятно:
Например, в одной из моих систем пользователь может выполнять действия вручную (искать, изменять данные и тд) + все операции продублированы через SOAP-методы. Вызовы методов описаны в документации, потому что их используют внешние системы. То есть изменение данных идет двумя разными сценариями:
Методы вроде одинаковые, но всякие плюшки интерфейса настраиваются в API с помощью параметров. Поэтому через API мы сам функционал проверяем один раз, что он в принципе работает, а потом рассматриваем особенно именно API, проходим по ТЗ, тестируем его параметры. Посмотреть, как это выглядит в требованиях, можно на примере Folks (чтобы увидеть ТЗ, надо авторизоваться, данные тут) — это бесплатное тестовое приложение, куда из реальной системы вынесена логика поиска. Можно искать через интерфейс, можно через SOAP-запрос. В Folks нет графического интерфейса (по крайней мере, пока нет, но я пока и не планирую его туда добавлять), но уже есть работоспособный код. И даже фреймворк под автотесты! Как происходит тестирование в системе, по аналогии с которой сделан Folks?
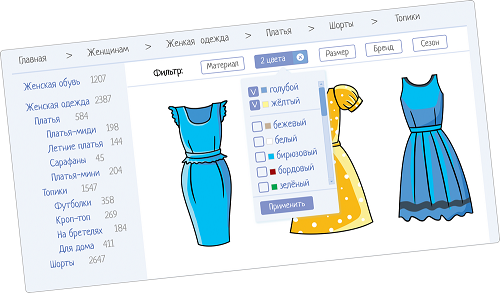
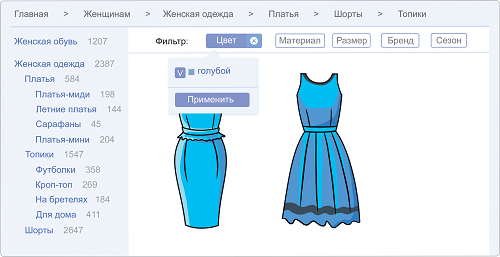
Можете попробовать сами, почитайте документацию, посмотрите обучающие видеоролики, которые я сделала специально под Folks, сравните, как выглядят тесты на поиск и тесты на SOAP-метод search. 3. Где схлопывать тесты НЕ надоНе надо объединять тесты на функционал и тесты на данные. Посмотрим на примере поиска и фильтрации. Вот, например, фильтры в интернет-магазине:
Можно установить один фильтр, а можно несколько сразу. Получается поиск с разными параметрами! Где-то там, под пользовательским интерфейсом скрывается некий API-метод, который умеет возвращать результат под разные входные условия. Как мы начинаем тестировать? Какой будет первый тест? Сразу же понеслись «а вот выберу платья, цвет серый, материал плюш, размер 42...»? Нет, это уже комплексное тестирование. Оно тоже важно и нужно, но начинаем с простого.
Берем каждый фильтр и тестируем по отдельности. Вроде кажется, что тестов будет over дофига, в базе магазина ведь целая куча данных! Но тут надо разделять тесты на функционал и тесты на данные. Тесты на функционал
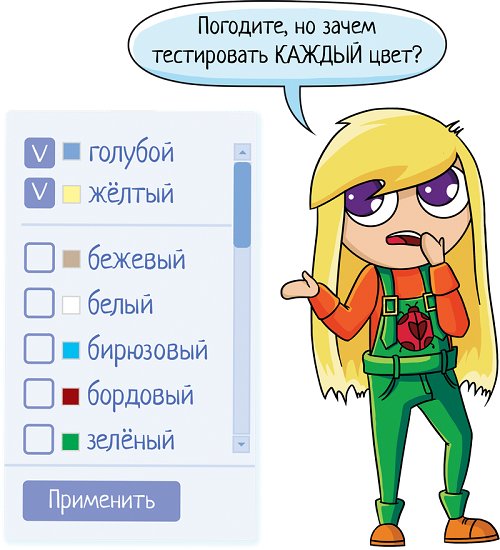
Вы сейчас можете сказать: стоп, стоп! А как же тест-анализ? Зачем тестировать каждый цвет? Достаточно проверить один, если функционал с метками работает — значит, всё норм.
Не совсем. Да, разработчик не пишет обработку для каждой вещи. Но он пишет обработку для каждой метки:
И вот тут он может ошибиться. Например, скопипастить результат и в обоих случаях выводить синие вещи. Или случайно опечатался и усе, синий работает, розовый, белый, черный — все работает, а вот на красном упадет! Причем с ужасной ошибкой, если разработчик не предусмотрел такой исход и не обернул эксепшен. Возможно, вы точно знаете, что код более умный и работает через параметры. If param = $param_1 then took thing with color = $param_1. Тут да, что красный, что синий — пофигу, один класс эквивалентности. Казалось бы. Но стоит задуматься, откуда берутся значения параметров. Наверное, где-то в коде есть класс, в котором перечислены допустимые величины — BLUE, RED, GREEN... И если разработчик опечатался в том классе, написав blie вместо blue, то хоть вы 100500 меток "синий" в админке на вещи повесите, поиск их никогда не найдет. Поэтому проверить все цвета — надо. Другое дело — как. Если у нас есть доступ к коду, то достаточно один раз вычитать файл с переменными и убедиться, что они написаны без опечаток. А в интерфейсе или автотестах проверить сам функционал:
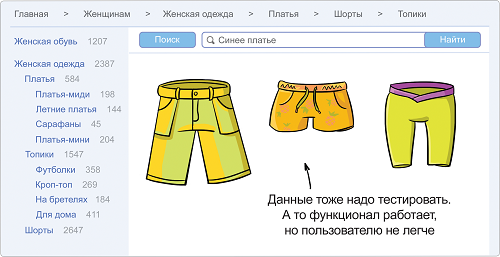
Тесты на данные
Нет, всё бывает, конечно, может быть и ошибкой функционала. Но, если мы уже провели тесты на функционал и знаем, что сами по себе метки работают, значит, такой баг является багом данных. Для исправления которого нужен не разработчик, а любой человек, имеющий доступ к админке. Комплексные тесты
Итого Когда мы пишем чек-лист, то сначала можем просто генерировать идеи, без оглядки на дубли. А потом присматриваемся к чек-листу и сокращаем:
Сократить чек-лист можно довольно сильно, посмотрите ещё раз на наш пример:
Главное — делать это осознанно и с умом, не выплеснув ценное в попытках сократить количество проверок =) А вот тесты на функционал и на данные путать не стоит. Их надо разносить в проверках. Сначала проверяем функционал, а потом уже смотрим на реальные данные (если эта задача ставится перед тестировщиком, но обычно это уже задача операторов качества данных). PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале |