


Что пишут в блогах
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026
- Как нагрузочное тестирование защищает бизнес от убытков?
- Исследовательское тестирование и UX‑аудит для интернет-магазина
- Юзабилити‑тестирование без розовых очков: почему идеальный функционал не спасёт от провала?
- А ваши тестировщики защищают ваш продукт и компанию от миллионных штрафов?
- TechWriter Days 3. Как это было

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация функционального тестированияНачало: 19 июня 2026
-
Школа тест-менеджеров v. 2.0Начало: 24 июня 2026
-
Python для начинающихНачало: 25 июня 2026
-
Азбука ИТНачало: 25 июня 2026
-
Школа для начинающих тестировщиковНачало: 25 июня 2026
-
Тестирование веб-приложений 2.0Начало: 26 июня 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 29 июня 2026
-
Тестирование REST APIНачало: 29 июня 2026
-
Школа Тест-АналитикаНачало: 1 июля 2026
-
Bash: инструменты тестировщикаНачало: 2 июля 2026
-
Docker: инструменты тестировщикаНачало: 2 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 2 июля 2026
-
SQL: Инструменты тестировщикаНачало: 2 июля 2026
-
Применение ChatGPT в тестированииНачало: 2 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 2 июля 2026
-
Git: инструменты тестировщикаНачало: 2 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 2 июля 2026
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Техники локализации плавающих дефектовНачало: 6 июля 2026
-
Логи как инструмент тестировщикаНачало: 6 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
| Падают тесты? Восстанавливаем надежность тест-результатов |
| 23.06.2025 00:00 |
|
Есть ли тут проблема? Почему определенные тесты падают, кажется, всегдаКак тестировщики, мы хотим, чтобы тесты говорили нам, если код продукта ведет себя не так, как мы ожидаем. Во многих окружениях непрерывной интеграции и деплоя (CI/CD) мы привыкли ожидать, что упавшие тесты будут «красными» на дашборде результатов. Красный цвет сообщает, что где-то есть проблема. Тесты, которые падают время от времени, особенно в областях продукта, подверженных регрессионным дефектам, очень полезны, ЕСЛИ становятся красными по веской причине: когда внедрен дефект, или в тест-окружении произошло что-то неожиданное. Но если тесты падают часто, иногда каждый день – это, возможно, знак, что их результатам нельзя доверять. Со временем, устав гоняться за ложноотрицательными результатами, за которыми не стоит никаких дефектов, команда начинает игнорировать упавшие тесты. А когда тесты падают из-за того, что в коде действительно есть дефект, никто этого не замечает. В то же время тестировщики, писавшие автоматизацию и сообщающие о дефектах, теряют доверие. Сейчас множество тестов живет там, что в терминологии DevOps называется «пайплайном». В книге The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations авторы сообщают, что роль «пайплайна деплоя» в том, чтобы убедиться, что код и инфраструктура всегда готовы к развертке – а для этого нужны непрерывные сборки, тестирование и интеграция. Задача этой статьи – не те автотесты, которые возвращают правдивые, надежные успехи и падения. Нас больше всего волнует то, что стоит назвать ненадежным пайплайном тестов, дающим недостоверные результаты, которые будут проигнорированы. Это происходит как с функциональными, так и с нефункциональными тестами. В этой статье мы разберемся, как выявить ненадежные пайплайны тестов, и, что еще важнее, что делать, чтобы исправить их или предотвратить их появление. Каковы причины ненадежных результатов тест-пайплайна?Проблемные уведомленияОдна первопричина ненадежных результатов тестов – это отсутствие грамотных уведомлений о падении. Проявляется это разными способами:
Отсутствие ответственностиСпустя некоторое время члены команды начнут игнорировать необходимость исследования проблем, о которых должен сообщать дашборд тестирования. Кто отвечает за изучение и исправление этих падений? Разработчик, создавший запрос слияния? Достаточно ли QA-поддержки, чтобы сотрудничать по этому вопросу? Надо ли девопсам присоединиться? Все эти вопросы важны, и в какой-то момент вам может понадобиться экспертиза разных ролей, чтобы докопаться до первопричины проблемы. Эмпирически стоит предположить, что как только падает какой-то этап тест-пайплайна, мы, как профессионалы обеспечения качества, должны брать дело в свои руки. Типы тестов и различия окруженийИ, конечно, создание достаточно стабильных стадий тестов не так просто, как кажется. Если в пайплайне смешаны разные типы тестов (например, функциональные и нефункциональные), при прогоне таких проверок может возникнуть широкий спектр проблем. Другой осложняющий фактор – наши локальные машины часто отличаются от тех, где будут прогоняться тесты, и тестировщики попадают в ловушку «на моей машине все работает», что усложняет исправление реальных проблем. Восстанавливаем надежность результатов тестов: мониторинг, действие, публикация
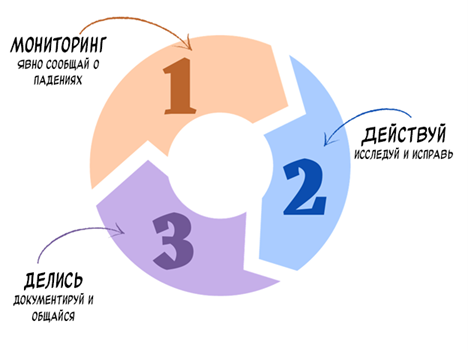
Надежный непрерывный пайплайн Для создания тест-пайплайна, который уверенно сообщает об ошибках приложения, нужно:
Этот цикл помогает убедиться в том, что пайплайн достоин доверия и выкидывает КРАСНОЕ только тогда, когда действительно найдена ошибка приложения. Цикл нужно непрерывно применять в ходе разработки, а не просто задействовать его пару раз. Далее мы глубже разберемся с каждым шагом. МониторингПо ходу проекта разработки ПО приложение и код его тестов будет параллельно развиваться. Будут добавляться новые сценарии, существующие будут меняться, и будут внедряться новые инструменты, чтобы реализовать другие типы тестирования – например, доступность и безопасность. По ходу изменений когда-то стабильный пайплайн быстро дестабилизируется. Тест, отлично работавший у разработчика, может вести себя иначе в деплой-версии приложения. Поэтому нам надо непрерывно отслеживать такие изменения.
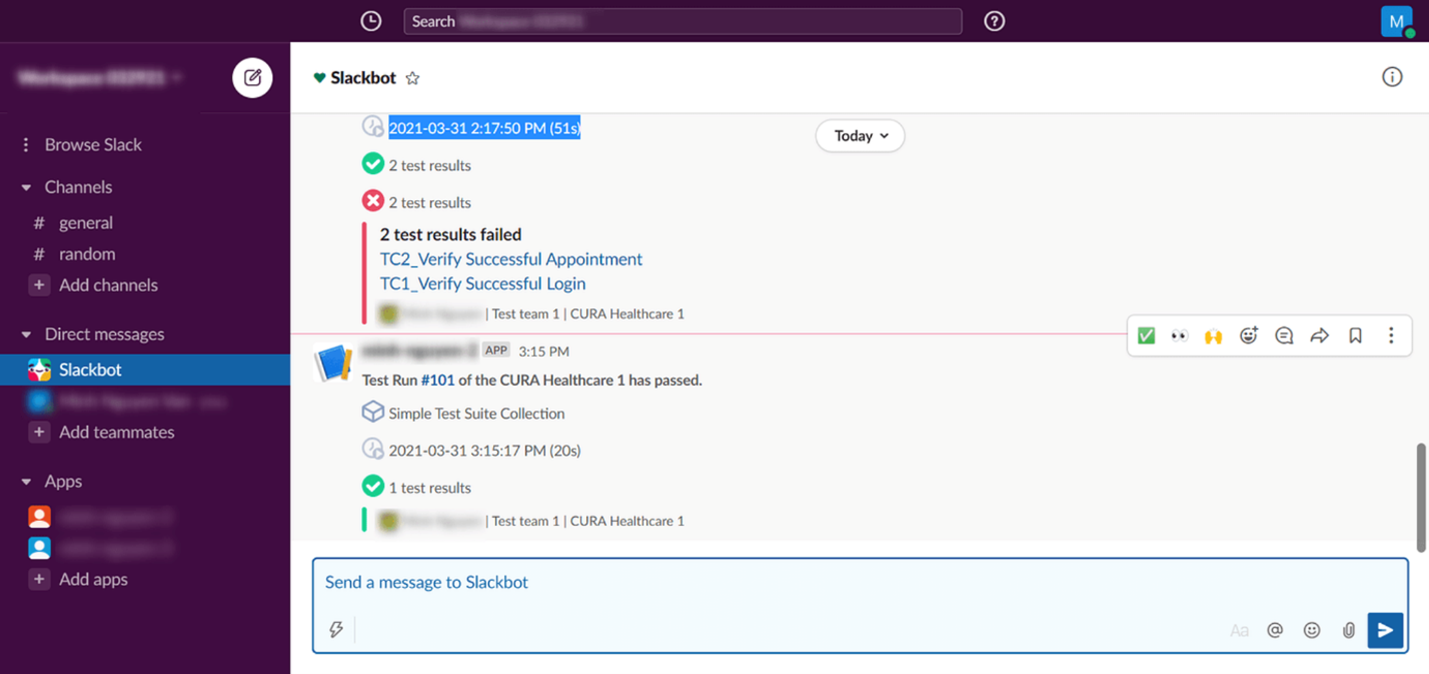
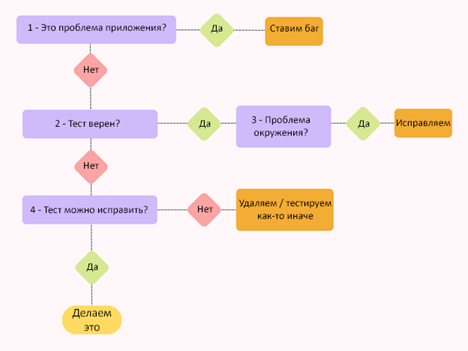
Уведомление о падении пайплайна Как показано на изображении выше, уведомления должны быть простыми и ясными – дающими необходимую и достаточную информацию, чтобы начать расследование. Если команде предоставлено краткое описание и ссылка на подробности запуска пайплайна, это помогает тщательному анализу проблемы. Результат работы пайплайна должен включать логи и все доступные отчеты о тестировании. Отправка уведомлений только в случае их релевантности для команды – другой важный аспект, который надо обдумать. Приведу пример: уведомление, что стартовала определенная фаза тестирования, имеет низкую значимость и, скорее всего, будет засорять канал, пряча более важные сообщения. ДействиеТестирование в пайплайне может упасть по тысяче причин. Это может быть вызвано чем-то простым, вроде сбоя сети, или очень сложным – запутанным тест-сценарием, который продолжает плохо себя вести, несмотря на силы, брошенные на его стабилизацию. Наиболее важная часть этапа действий – не игнорировать упавшие тесты ни под каким видом. Возможно, подробное изучение вопроса сейчас не в приоритете, но нельзя игнорировать его до бесконечности. Схема ниже показывает, как можно проанализировать проблему и определиться с дальнейшими действиями.
Схема анализа и действий 1. Исследование проблем приложенияПервый и наиболее важный вопрос, на который нужно найти ответ, изучая упавший тест: это проблема приложения? (вопрос 1 на схеме) Чтобы это определить, возможно, понадобится вернуться к требованиям, поговорить с разработчиками и бизнес-аналитиками, и даже попытаться вручную воспроизвести проблему. Как только мы убедились, что перед нами реальная проблема, ее можно завести как баг и повысить уверенность в том, что наш набор тестов правильно выполняет свою работу. 2. Код теста верен?С другой стороны, если падение теста не вызвано проблемой в коде продукта, можно усомниться в том, что автоматизированная проверка правильно взаимодействует с приложением (вопрос 2 на схеме). В этом случае надо выяснить:
3. Есть ли проблема с окружением?Если код теста верен, то следующая станция – это окружение (вопрос 3 на схеме). Вот типичные проблемы окружения, которые могут вызвать падение тестов:
Для исправления некоторых из этих проблем понадобится поработать – добавить отсутствующие переменные окружения, убедиться, что сетевые запреты сняты, проверить, что база данных правильно настроена. В других случаях, – например, если нужные службы временно недоступны или приложение не запускается, – возможно, достаточно будет перезапустить пайплайн. 4. Исправить тест или удалить его?Иногда тесты можно исправить, а иногда это невозможно. Тут мы задаем 4 вопрос со схемы. В некоторых случаях нужно пустяковое исправление, как показано на изображении ниже – тест ожидал число двойной точности, а получил строку.
В других случаях нужно изменить тест, сделав его чувствительнее к состояниям приложения, убеждаясь, что мы переходим дальше только тогда, когда приложение к этому готово. Например:
Но иногда проблема проверки не так очевидна. Например:
Если мы определили, что тест нельзя исправить за разумное время, надо решить, что с ним делать. Мы можем:
ДелимсяЗа качество отвечают все, и это, в частности, значит работу над стабилизацией тестирования. Следовательно, все вовлеченные лица должны формально и неформально документировать практики и руководства по работе с тест-стадиями имеющегося пайплайна. Требуемый уровень документации зависит от того, как работает ваша команда, но в целом вы должны покрыть:
Если все знают, как узнать о падениях и что в этом случае делать, это помогает приобщить коллег к процессу и дать им почувствовать ответственность за весь пайплайн непрерывной интеграции. Чтобы эта информация была доступна всем, критически важно сотрудничать с другими коллегами (например, DevOps). ЗаключениеКак профессионалы обеспечения качества, мы, в частности, должны предоставлять значимую информацию всем заинтересованным лицам, чтобы они вовремя принимали качественные информированные решения. Создание и поддержка стабильных тестов играет ключевую роль в создании надежной конфигурации CI/CD. «Фундаментальный принцип непрерывной поставки (CD) – это работать так, чтобы ПО всегда было готово к релизу. Чтобы этого достичь, надо работать очень качественно. В этом случае при выявлении проблемы ее легко исправить, и мы быстро и легко вернемся к возможности релиза». Дейв Фарли, Benefits of Continuous Delivery, DORA Metrics Report 2023 Чтобы код был готов к релизу, надо иметь возможность быстро выявить и исправить проблему. Чтобы этого добиться, тесты должны возвращать обратную связь, которой можно доверять. Взятие на себя ответственности за тест-стадии пайплайна требует времени и сил, но только приоритезируя эту задачу и ежедневно над ней работая, можно давать быструю обратную связь и повышать общую производительность. Следовательно, убеждайтесь, что каждый добавленный тест, каждый запуск пайплайна пристально изучается. Так вы добьетесь того, что они всегда дадут вам ценную обратную связь. |

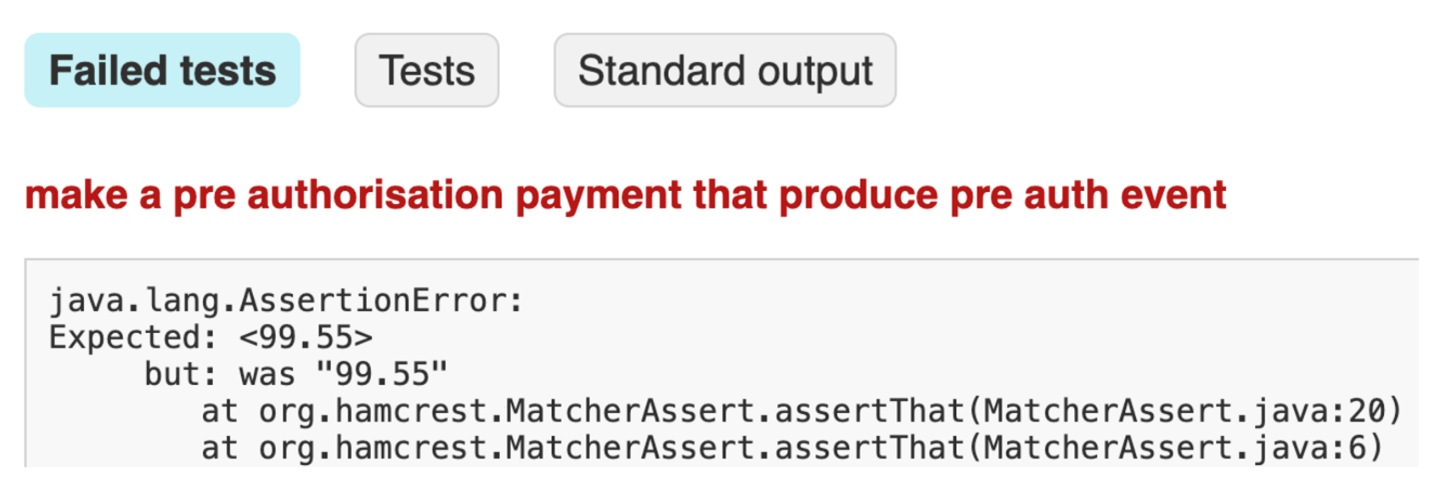 Условие ожидало числа двойной точности, а получило строку
Условие ожидало числа двойной точности, а получило строку